В этой статье создадим веб-парсер на Python, который будет парсить страницы Википедии.
Парсер перейдет на страницу Википедии, считает заголовок и перейдет по случайной ссылке на следующую страницу Википедии.
Я думаю, будет интересно посмотреть, какие случайные страницы Википедии посетит этот парсер!
Установка парсера
Для начала создадим новый файл Python с именем scraper.py:
touch scraper.py
Чтобы сделать HTTP-запрос, будем использовать библиотеку запросов. Вы можете установить её с помощью следующей команды:
pip install requests
Давайте использовать вики-страницу для парсинга в качестве отправной точки:
import requests
response = requests.get(
url="https://en.wikipedia.org/wiki/Web_scraping",
)
print(response.status_code)
При запуске парсера он должен отображать код состояния 200:
python3 scraper.py
200
Хорошо, пока все хорошо!
Извлечение данных со страницы
Давайте извлечем заголовок из HTML-страницы. Чтобы облегчить себе жизнь, будем использовать для этого пакет BeautifulSoup.
pip install beautifulsoup4
При просмотре страницы Википедии я вижу, что тег заголовка имеет идентификатор #firstHeading.
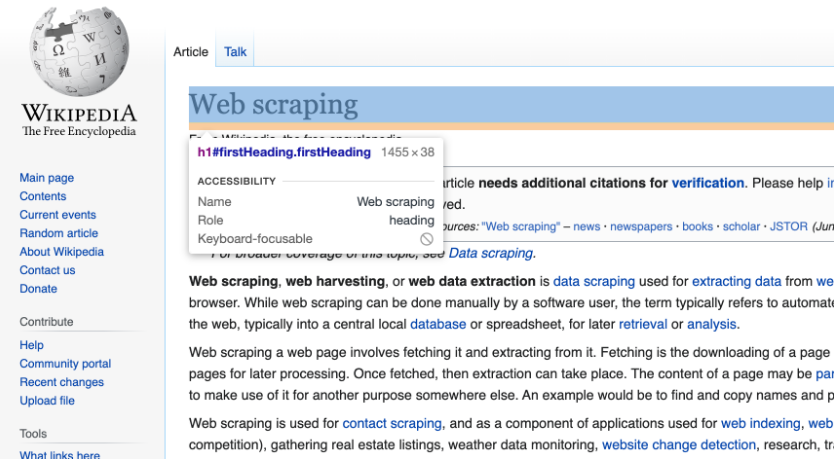
BeautifulSoup позволяет найти элемент по ID тегу.
title = soup.find(id="firstHeading")
Собирая все вместе, программа теперь выглядит так:
import requests
from bs4 import BeautifulSoup
response = requests.get(
url="https://en.wikipedia.org/wiki/Web_scraping",
)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find(id="firstHeading")
print(title.string)
И при запуске он показывает заголовок статьи Wiki:
python3 scraper.py
Web scraping
Парсинг других ссылок
Теперь углубимся в Википедию. Возьмем случайный тег <a> к другой статье Википедии и спарсим эту страницу.
Для этого воспользуемся BeautifulSoup, чтобы найти все теги <a> в статье вики. Затем перемешаем список, чтобы сделать его случайным.
import requests
from bs4 import BeautifulSoup
import random
response = requests.get(
url="https://en.wikipedia.org/wiki/Web_scraping",
)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find(id="firstHeading")
print(title.content)
# Get all the links
allLinks = soup.find(id="bodyContent").find_all("a")
random.shuffle(allLinks)
linkToScrape = 0
for link in allLinks:
# We are only interested in other wiki articles
if link['href'].find("/wiki/") == -1:
continue
# Use this link to scrape
linkToScrape = link
break
print(linkToScrape)
Как видите, мы используем soup.find (id = «bodyContent»). Find_all («a»), чтобы найти все теги в основной статье.
Поскольку нас интересуют только ссылки на другие статьи в Википедии, удостоверяемся, что ссылка содержит префикс / wiki.
Теперь при запуске программы отображается ссылка на другую статью в Википедии, приятно!
python3 scraper.py
<a href="/wiki/Link_farm" title="Link farm">Link farm</a>
Создание бесконечного парсера
Хорошо, давайте заставим парсер очищать новую ссылку.
Для этого переместим все в функцию scrapeWikiArticle.
import requests
from bs4 import BeautifulSoup
import random
def scrapeWikiArticle(url):
response = requests.get(
url=url,
)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find(id="firstHeading")
print(title.text)
allLinks = soup.find(id="bodyContent").find_all("a")
random.shuffle(allLinks)
linkToScrape = 0
for link in allLinks:
# We are only interested in other wiki articles
if link['href'].find("/wiki/") == -1:
continue
# Use this link to scrape
linkToScrape = link
break
scrapeWikiArticle("https://en.wikipedia.org" + linkToScrape['href'])
scrapeWikiArticle("https://en.wikipedia.org/wiki/Web_scraping")
Функция scrapeWikiArticle получит статью вики, извлечет заголовок и найдет случайную ссылку.
Затем он снова вызовет scrapeWikiArticle с этой новой ссылкой. Таким образом, он создает бесконечный цикл парсера, который скачет по википедии.
Запустим программу и посмотрим, что получим:
pythron3 scraper.py
Web scraping
Digital object identifier
ISO 8178
STEP-NC
ISO/IEC 2022
EBCDIC 277
Code page 867
Code page 1021
EBCDIC 423
Code page 950
G
R
Mole (unit)
Gram
Remmius Palaemon
Encyclopædia Britannica Eleventh Edition
Geography
Gender studies
Feminism in Brazil
Замечательно, примерно за 10 шагов мы прошли путь от «Веб-скрейпинга» до «Феминизма в Бразилии». Удивительно!
Вывод
Мы создали веб-парсер на Python, который парсит случайные страницы Википедии. Он бесконечно перемещается по Википедии по случайным ссылкам.
Это забавный трюк, и Википедия довольно снисходительна, когда дело касается парсинга веб-страниц.
Также труднее парсить такие сайты, как Amazon или Google. Если вы хотите спарсить такой веб-сайт, вам следует настроить систему с автономными браузерами Chrome и прокси-серверами. Или вы можете использовать сервис, который сделает все за вас, как этот.
Но будьте осторожны, не злоупотребляйте веб-сайтами и парсите только те данные, которые вам разрешено парсить.
Удачного кодирования!