Дисперсией в статистике называют величину, отражающую меру разброса данных вокруг среднего арифметического значения выборки данных.
В общем виде формула для дисперсии выглядит следующим образом:

Рассмотрим пример определения дисперсии средсвами Excel. Для этого создадим тестовый массив из 20 случайных значений в диапазоне от 5 до 15 (я пользовался функцией СЛУЧМЕЖДУ()):
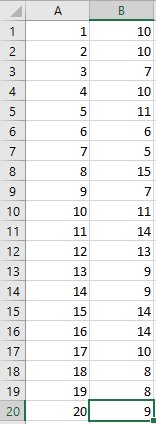
Для формулы дисперсии, представленной выше количество значений n равно значению ячейки А20; i принимает значения от 1 до n, т.е. до 20; Xi - значения ячеек B1:B20. Неизвестным остается X среднее, которое посчитаем с помощью функции СРЗНАЧ() и вычисли разницуу между Xi и X средним для каждого значения выборки:
Средним значением выборки стало число 10, соответственно в столбце С разницей Xi - Xсреднее становится 0 для первого элемента выборки, 0 для второго, -3 для третьего и т.д. до -1 для двадцатого.
Далее каждую разницу нужно возвести в квадрат, для этого можно воспаользоваться функцией СТЕПЕНЬ(), а можно поступить проще:
Теперь посчитаем сумму квадратов разниц простым суммированием столбца D и разделим ее на n-1, т.е. из ячейки А20 вычтем 1:
Или воспользуемся функцией СЧЁТ():
Для нашей выборки значение дисперсии составило 8,105263.
А вообще в Excel есть специальная функция для расчета дисперсии, вызов которой выглядит следующим образом:
Однако, способ расчета дисперсии по шагам (без использхования функции ДИСП.В()) более интересен в рамках изучения возможностей Excel.
Если Вам интересен Excel, то подписывайтесь на этот канал, ставьте лайк, пишите комментарии, задавайте вопросы.