Google обладает гибкими условиями поиска, которые позволяют значительно увеличить релевантность получаемых результатов. Их умелое применение позволяет находить материал, как бы глубоко он ни был спрятан, и сэкономить время за счет фильтрации шума.

Рассмотрим эти настройки на примерах.
Поиска по сайту
Зачастую вам требуется не только найти информацию, но и получить ее именно с какого-то определенного сайта. Такая необходимость может возникать, например, в силу повышенного доверия к сведениям с этого ресурса или когда вас интересует позиция его владельцев/редакторов, а также данные, хранящиеся на нем.
Например, если я уверен в качестве материалов на сайтах habr.com и xakep.ru, и хочу ограничиться статьями об "обработке звука с помощью python" на них, мне потребуется задать:
обработка звука с помощью python site:habr.com | site:xakep.ru
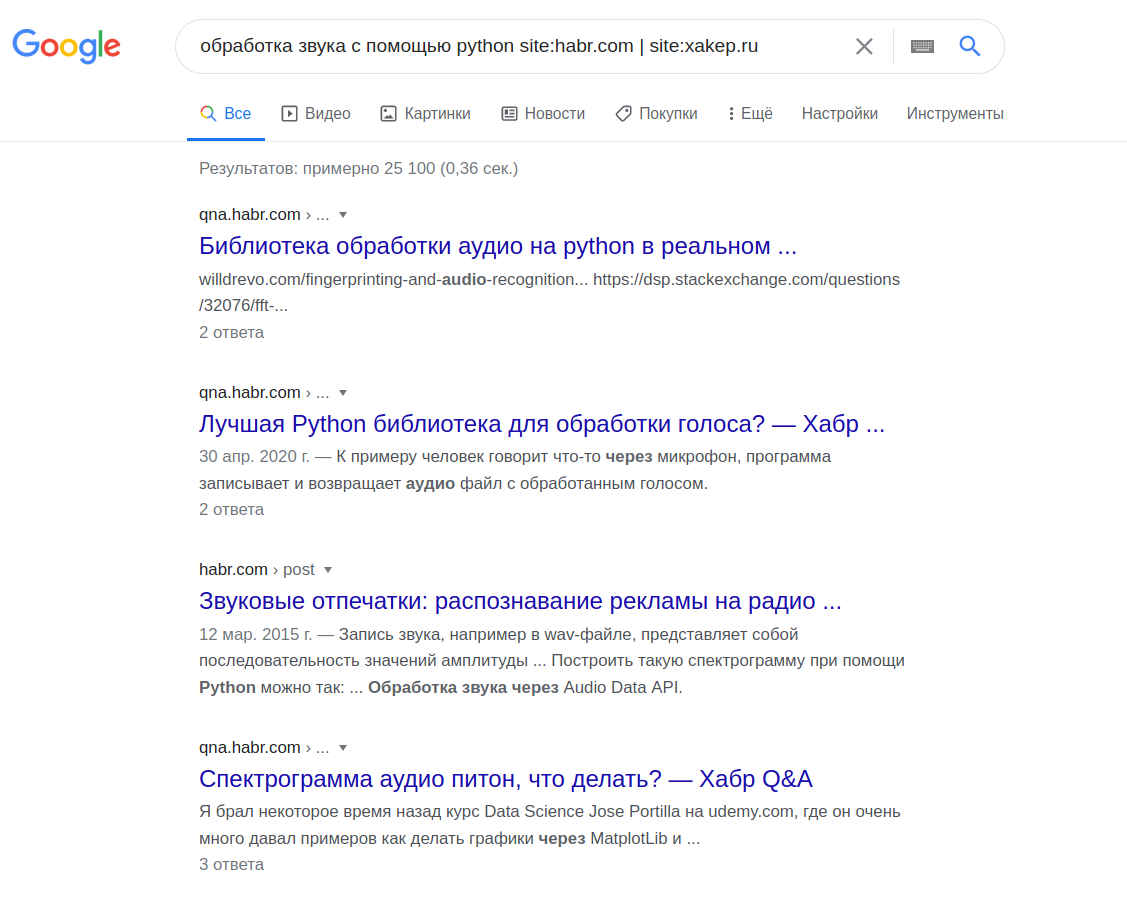
То есть мы сообщаем поисковой системе о желании воспользоваться поиском по сайту при помощи ключевого слова site:сайт. Знак "|" обозначает условие ИЛИ.
Отмечу, что многие сайты имеют свои поисковые системы и для наших целей можно воспользоваться и ими.
Поиск по типу файла
Продолжая охоту на материалы по обработке звука с помощью Python, можно попробовать искать соответствующий текст не на каком-либо сайте, а в файлах. Это дает надежду найти качественный материал, так как обстоятельное изучение определенной темы зачастую оформляется в виде файла формата pdf, docx и.т.д. Для поиска по файлам Google предусмотрел ключевое слово filetype. Например, наш запрос по популярным типам файлов приобретет следующий вид:
обработка звука Python filetype:doc | filetype:docx | filetype:rtf | filetype:txt | filetype:fb2 | filetype:djvu | filetype:odt | filetype:pdf | filetype:rar | filetype:zip
Поиск по части url
Когда нам может быть полезен поиск по части url? Обратите внимание на сайт iro23.ru на последнем скриншоте, который приводит к ссылке на книгу. Допустим, вы хотите поискать еще книги по Python на данном сайте и поэтому приглядываетесь внимательнее к адресу - http://iro23.ru/sites/default/files/sveygart_e._-_uchim_python_delaya_krutye_igry_4-e_izdanie-2018.pdf
Можно предположить, что другие пособия лежат рядом с данным и начало их url совпадает с этим - http://iro23.ru/sites/default/files/. Однако попытка зайти по адресу через браузер не приводит к достижению цели:
Тогда на помощь приходит запрос с использованием начального url, который в Google можно осуществить с использованием ключевого слова inurl. Таким образом, наш запрос примет следующий вид:
python inurl:http://iro23.ru/sites/default/files/
Как можно убедиться, альтернативным путем нам все-таки удалось получить другие ссылки на книги.
Нахождение точного соответствия
Все, что нужно для этого - заключить поисковую фразу в кавычки. Обычно я использую точное совпадение для поиска книг, имея произвольную фразу из ее содержания. Например, для нахождения сборника стихов Пушкина А.С. можно попробовать ввести:
Также поиск по точному соответствию я обычно использую для нахождения первоисточника новости. Попытаемся определить первоисточник текста с призывом отказываться от прохождения биометрической аутентификации в Сбербанке, о котором шла речь в прошлой статье.
Задав произвольный период поиска с 01 мая 2020 г., можно увидеть, что только 2 результата содержат ключевую фразу:
Затем я стал перебирать различные периоды и определил, что в 2019 г. и до 21 января 2020 г. ссылок на аналогичную публикацию не имеется:
Теперь, задав период в один день - 21 января 2020 г., - можно найти ориентировочный первоисточник новости (точно утверждать не буду, так как Google индексирует не все страницы в Интернете, а только самые популярные):
Таким образом, я описал практикуемые мной способы использования ключевых слов Google. А какими возможностями поисковой системы пользуетесь вы? Делитесь в комментариях.



















