Раз и навсегда разберемся со считыванием корпуса размеченных текстов с Python. Здесь я поделюсь готовым классом, реализующим этот функционал.

Для начала нам понадобятся классы библиотеки NLTK CategorizedPlaintextCorpusReader и PlaintextCorpusReader (из модуля nltk.corpus.reader.plaintext), которые инициализируются указанием корневой папки, шаблона файлов и шаблона меток (фактически названия подпапок, только для CategorizedPlaintextCorpusReader) и имеют удобные методы возврата названий файлов.
Так, CategorizedPlaintextCorpusReader, позволяет задав список папок/меток, вернуть с помощью метода fileids названия всех входящих файлов. Аналогично класс PlaintextCorpusReader путем вызова одноименного метода возвращает список названий файлов из корневой директории. Создадим собственный класс CorpusReader, наследующий CategorizedPlaintextCorpusReader. В качестве поля root_reader класс получит объект PlaintextCorpusReader для возврата имен файлов из корневой директории в свойство root_ids.
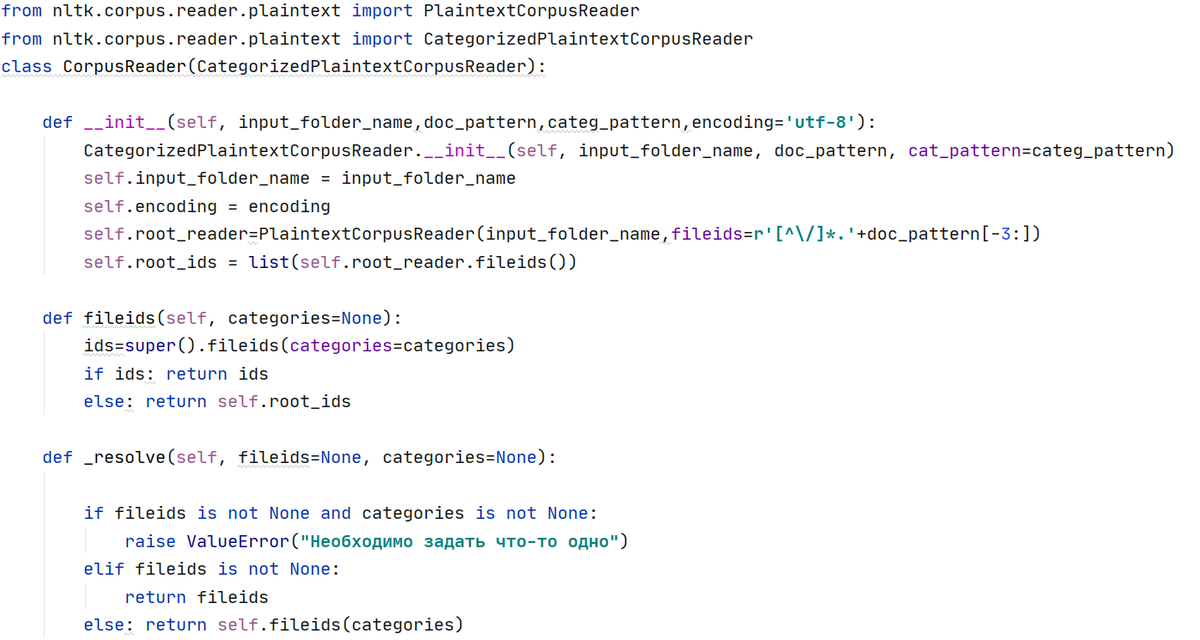
Также в классе расширяется метод родительского класса fileids, чтобы в случае categories=None, вернуть список имен файлов из корневой директории (не входящих ни в одну подпапку).
Метод _resolve предусматривает возврат списка имен файлов при задании как их имен, так и категорий. В последующем данный метод используется как вспомогательный в работе генератора, возвращающего содержимое списка файлов (readfiles):
В демонстрационных целях создадим экземпляр CorpusReader и выведем списки файлов:
Теперь выведем содержимое файла (представлена только часть):
Вот таким образом можно упростить чтение набора размеченных файлов. А какими способами пользуетесь вы? Делитесь в комментариях.



















