В этой главе мы рассмотрим проблему разработки одного из наиболее известных подходов к планированию, известного как многоуровневая очередь обратной связи (MLFQ). Планировщик многоуровневой очереди обратной связи (MLFQ) был впервые описан Corbato et al. в 1962 году в системе, известной как совместимая система разделения времени (CTSS), и эта работа, наряду с более поздними работами по Multics, привела ACM к присуждению Corbato своей высшей награды - премии Тьюринга. Планировщик впоследствии был усовершенствован на протяжении многих лет до реализаций, с которыми вы столкнетесь в некоторых современных системах.
Фундаментальная проблема, которую пытается решить MLFQ, двоякая. Во-первых, он хотел бы оптимизировать время выполнения, которое, как мы видели в предыдущей заметке, выполняется сначала путем выполнения более коротких заданий; к сожалению, ОС обычно не знает, как долго будет выполняться задание, именно те знания, которые требуются алгоритмам типа SJF (или STCF). Во-вторых, MLFQ хотел бы, чтобы система чувствовала себя отзывчивой к интерактивным пользователям (то есть пользователям, сидящим и уставившимся на экран, ожидая завершения процесса) и, таким образом, минимизировать время отклика; к сожалению, такие алгоритмы, как Round Robin, сокращают время отклика, но ужасны для времени оборота. Таким образом, наша проблема: учитывая, что мы в целом ничего не знаем о процессе, как мы можем построить планировщик для достижения этих целей? Как планировщик может узнать, как работает система, характеристики выполняемых заданий и, таким образом, принимать лучшие решения по планированию?
СУТЬ:
КАК ПЛАНИРОВАТЬ БЕЗ СОВЕРШЕННОГО ЗНАНИЯ?
Как мы можем разработать планировщик, который одновременно минимизирует время отклика для интерактивных заданий, а также минимизирует время выполнения без априорного знания длины задания?
Многоуровневая очередь обратной связи-отличный пример системы, которая учится у прошлого предсказывать будущее. Такие подходы распространены в операционных системах (и во многих других областях информатики, включая аппаратные предсказатели ветвей и алгоритмы кэширования). Такие подходы работают, когда задания имеют фазы поведения и поэтому предсказуемы; конечно, нужно быть осторожным с такими методами, поскольку они могут легко ошибаться и заставлять систему принимать худшие решения, чем они могли бы сделать без знания вообще.
MLFQ: Базовые правила
Чтобы построить такой планировщик, в этой главе мы опишем основные алгоритмы, лежащие в основе многоуровневой очереди обратной связи; хотя специфика многих реализованных MLFQ отличается, большинство подходов схожи.
В нашем примере MLFQ имеет несколько различных очередей, каждой из которых присвоен свой уровень приоритета. В любой момент времени готовое к запуску задание находится в одной очереди. MLFQ использует приоритеты, чтобы решить, какое задание должно выполняться в данный момент времени: для выполнения выбирается задание с более высоким приоритетом (т. е. задание в более высокой очереди).
Конечно, несколько заданий могут находиться в одной очереди и, следовательно, иметь одинаковый приоритет. В этом случае мы просто будем использовать циклическое планирование среди этих заданий.
Таким образом, мы приходим к первым двум основным правилам для MLFQ:
- Правило 1: Если приоритет А > приоритета B - А запускается, B - нет
- Правило 2: Если приоритеты равны, А и B запускаются с использованием RR
Таким образом, ключ к планированию MLFQ лежит в том, как планировщик устанавливает приоритеты. Вместо того чтобы давать фиксированный приоритет каждому заданию, MLFQ изменяет приоритет задания на основе его наблюдаемого поведения. Если, например, задание неоднократно освобождает процессор в ожидании ввода с клавиатуры, MLFQ будет сохранять высокий приоритет, поскольку именно так может вести себя интерактивный процесс. Если вместо этого задание интенсивно использует процессор в течение длительного периода времени, MLFQ снизит его приоритет. Таким образом, MLFQ будет пытаться узнать о процессах по мере их выполнения и, таким образом, использовать историю задания для прогнозирования его будущего поведения.
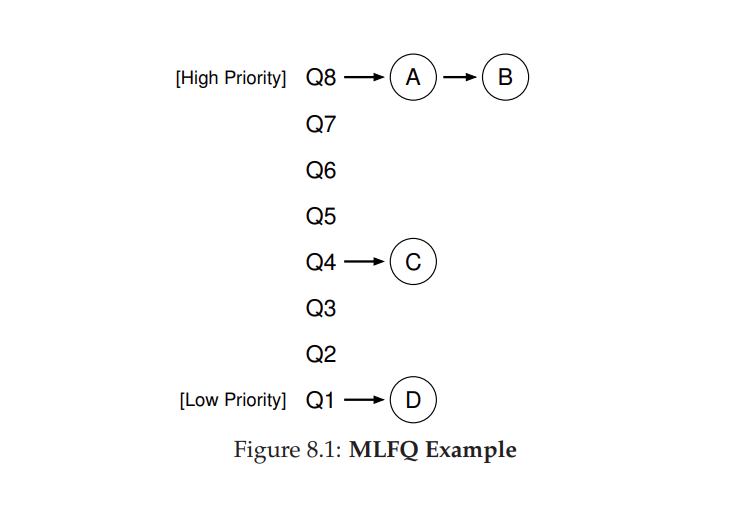
Если мы представим себе, как могут выглядеть очереди в данный момент, то увидим примерно следующее (рис.8.1). На рисунке два задания (А и B) находятся на самом высоком уровне приоритета, в то время как задание С находится посередине, а задание D-на самом низком уровне приоритета. Учитывая наши текущие знания о том, как работает MLFQ, планировщик будет просто чередовать временные срезы между A и B, потому что они являются самыми приоритетными заданиями в системе; плохие задания C и D никогда даже не будут запущены — возмутительно!
Конечно, просто показ статического снимка некоторых очередей на самом деле не дает вам представления о том, как работает MLFQ. Что нам нужно, так это понять, как приоритет работы меняется с течением времени. И это, к удивлению только тех, кто читает главу из этой книги в первый раз, именно то, что мы будем делать дальше.
Попытка №1: Как Изменить Приоритет
Теперь мы должны решить, как MLFQ будет изменять уровень приоритета задания (и, следовательно, в какой очереди оно находится) в течение всего срока службы задания. Чтобы сделать это, мы должны иметь в виду нашу рабочую нагрузку: смесь интерактивных заданий, которые являются кратковременными (и могут часто отказываться от процессора), и некоторые более длительные “связанные с процессором” задания, которые требуют много процессорного времени, но где время отклика не важно. Вот наша первая попытка алгоритма настройки приоритета:
- Правило 3: когда задание поступает в систему, оно помещается в самый высокий приоритет (самая верхняя очередь).
- Правило 4а: если задание использует весь временной срез во время выполнения, его приоритет уменьшается (т. е. оно перемещается вниз на одну очередь).
- Правило 4b: если задание отказывается от процессора до истечения временного среза, оно остается на том же уровне приоритета.
Пример 1: Одно Длительное Задание
Давайте рассмотрим несколько примеров. Во-первых, мы рассмотрим, что происходит, когда в системе была длительная работа. На рис. 8.2 показано, что происходит с этим заданием с течением времени в планировщике с тремя очередями.
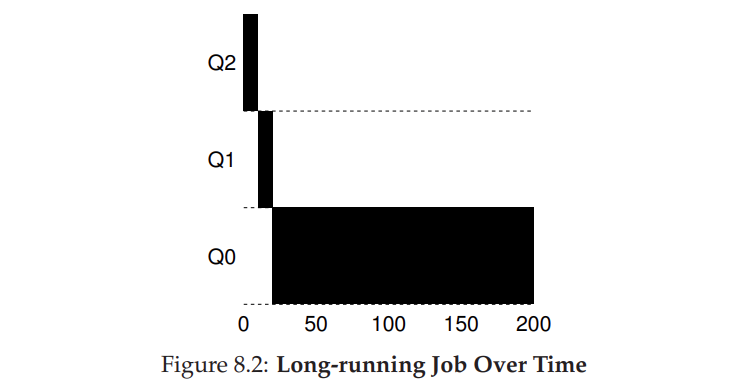
Как видно из примера, задание вводится с наивысшим приоритетом (Q2). После одного временного среза в 10 мс планировщик уменьшает приоритет задания на единицу, и таким образом задание находится на Q1. После запуска в Q1 в течение временного среза задание, наконец, опускается до самого низкого приоритета в системе (Q0), где оно и остается. Довольно просто, не так ли?
Пример 2: Появилась Короткая Работа
Теперь давайте рассмотрим более сложный пример и, надеюсь, посмотрим, как MLFQ пытается приблизиться к SJF. В этом примере есть два задания: A, которое является длительным и интенсивным для процессора, и B, которое является кратковременным интерактивным заданием. Предположим, что A работает в течение некоторого времени, а затем появляется B. Что же будет? Будет ли MLFQ приблизительным SJF для B?
На рис. 8.3 показаны результаты этого сценария. A (показано черным цветом) выполняется в очереди с самым низким приоритетом (как и любые длительные задания с интенсивным использованием ЦП); B (показано серым цветом) прибывает в момент времени T = 100 и, таким образом, вставляется в самую высокую очередь; поскольку его время выполнения короткое (всего 20 мс), B завершается до достижения нижней очереди в два временных среза; затем A возобновляет работу (с низким приоритетом).
Из этого примера вы, надеюсь, поймете одну из главных целей алгоритма: поскольку он не знает, будет ли задание коротким или длительным, он сначала предполагает, что это может быть короткое задание, тем самым придавая ему высокий приоритет. Если это действительно короткая работа, она будет выполняться быстро и полностью; если это не короткая работа, она будет медленно двигаться вниз по очередям и, таким образом, вскоре окажется длительным процессом, более похожим на пакет. Таким образом, MLFQ приближается к SJF.
Пример 3: Как Насчет Ввода-Вывода?
Давайте теперь рассмотрим пример с некоторым вводом-выводом. Как указано выше в правиле 4b, если процесс отказывается от процессора до использования своего временного среза, мы сохраняем его на том же уровне приоритета. Цель этого правила проста: если интерактивное задание, например, выполняет много операций ввода-вывода (скажем, ожидая ввода данных пользователем с клавиатуры или мыши), оно откажется от процессора до завершения его временного среза; в таком случае мы не хотим наказывать задание и, таким образом, просто держим его на том же уровне.
На рис. 8.4 показан пример того, как это работает, с интерактивным заданием B (показано серым цветом), которому требуется процессор только в течение 1 мс перед выполнением ввода-вывода, конкурирующего за процессор с длительным пакетным заданием A (показано черным цветом). Подход MLHFQ сохраняет оба самых высоких приоритета, потому что B продолжает освобождать процессор; если B является интерактивным заданием, MLFQ далее достигает своей цели быстрого запуска интерактивных заданий.
Проблемы с нашим текущим MLFQ
Таким образом, у нас есть базовый MLFQ. Похоже, он делает довольно хорошую работу, справедливо распределяя процессор между длительными заданиями и позволяя быстро выполнять короткие или интенсивные интерактивные задания ввода-вывода. К сожалению, подход, который мы разработали до сих пор, содержит серьезные недостатки. Вы можете назвать какие-нибудь?
(Здесь вы делаете паузу и думаете так хитро, как только можете)
Во-первых, существует проблема голода: если в системе “слишком много” интерактивных заданий, они будут объединяться, чтобы потреблять все процессорное время, и, таким образом, длительные задания никогда не получат никакого процессорного времени (они голодают). Мы хотели бы добиться некоторого прогресса для долгих заданий даже при таком сценарии.
Во-вторых, умный пользователь может переписать свою программу для игры в планировщик. Игра в планировщик обычно относится к идее сделать что-то хитрое, чтобы обмануть планировщик и дать вам больше, чем ваша справедливая доля ресурса. Алгоритм, который мы описали, подвержен следующей атаке: прежде чем закончится временной срез, выполните операцию ввода-вывода (для какого-то файла, который вам безразличен) и, таким образом, откажитесь от процессора; это позволит вам оставаться в той же очереди и, таким образом, получить более высокий процент процессорного времени. При правильном выполнении (например, при выполнении 99% временного среза перед отказом от ЦП) задание может почти монополизировать ЦП.
Наконец, программа может изменить свое поведение с течением времени; то, что было привязано к процессору, может перейти в фазу интерактивности. При нашем нынешнем подходе такая работа будет неудачной и не будет рассматриваться как другие интерактивные задания в системе.
СОВЕТ: ПЛАНИРОВАНИЕ ДОЛЖНО БЫТЬ ЗАЩИЩЕНО ОТ АТАК
Вы можете подумать, что политика планирования, будь то внутри самой ОС (как обсуждается здесь) или в более широком контексте (например, в обработке запросов ввода-вывода распределенной системы хранения), не является проблемой безопасности, но во все большем числе случаев это именно так. Рассмотрим современный центр обработки данных, в котором пользователи со всего мира делятся процессорами, памятью, сетями и системами хранения данных; не заботясь о разработке политики и ее применении, один пользователь может нанести вред другим и получить преимущество для себя. Таким образом, политика планирования является важной частью безопасности системы и должна быть тщательно разработана.
Попытка №2: Повышение Приоритета
Давайте попробуем изменить правила и посмотрим, сможем ли мы избежать проблемы голода. Что мы можем сделать, чтобы гарантировать, что связанные с процессором задания достигнут некоторого прогресса (даже если и небольшого?).
Простая идея здесь заключается в том, чтобы периодически повышать приоритет всех заданий в системе. Есть много способов добиться этого, но давайте просто сделаем что-то простое: бросим их все в самую верхнюю очередь; отсюда и новое правило:
- Правило 5: через некоторое время S переместите все задания в системе в самую верхнюю очередь.
Наше новое правило решает сразу две проблемы. Во-первых, процессы гарантированно не голодают: сидя в верхней очереди, задание будет делиться процессором с другими высокоприоритетными заданиями в циклическом порядке и, таким образом, в конечном итоге получать обслуживание. Во-вторых, если задание, связанное с процессором, стало интерактивным, планировщик обрабатывает его должным образом, как только он получил повышение приоритета.
Давайте рассмотрим пример. В этом сценарии мы просто показываем поведение продолжительного задания при конкуренции за процессор с двумя короткими интерактивными заданиями. Два графика показаны на рис. 8.5. Слева нет повышения приоритета, и, таким образом, длительная работа голодает, как только появляются две короткие работы; справа есть повышение приоритета каждые 50 мс (что, вероятно, слишком мало, но используется здесь для примера), и таким образом мы, по крайней мере, гарантируем, что длительное задание будет иметь некоторый прогресс, повышаясь до самого высокого приоритета каждые 50 мс и, таким образом, периодически запускаясь.
Конечно, добавление временных периодов приводит к очевидному вопросу: на что должно быть установлено значение S? Джон Остерхаут, известный исследователь систем, обычно называл такие значения в системах константами вуду, потому что они, казалось, требовали какой-то формы черной магии, чтобы установить их правильно. К сожалению, у S есть эта особенность. Если он установлен слишком высоко, длительные задания могут голодать; слишком низко, и интерактивные задания могут не получить должной доли процессора.
Попытка №3: Лучший Учет
Теперь нам нужно решить еще одну проблему: как предотвратить возможность взлома нашего планировщика? Настоящим виновником здесь, как вы уже могли догадаться, являются Правила 4a и 4b, которые позволяют заданию сохранить свой приоритет, отказавшись от процессора до истечения временного среза. Так что же нам делать?
Решение здесь состоит в том, чтобы лучше учитывать процессорное время на каждом уровне MLFQ. Вместо того чтобы забывать, какую часть временного среза использует процесс на данном уровне, планировщик должен отслеживать; как только процесс использует выделенные ресурсы, он понижается до следующей приоритетной очереди. Использует ли он временной срез в одном длинном всплеске или во многих маленьких, не имеет значения. Таким образом, мы перепишем правила 4a и 4b в следующее единое правило:
- Правило 4: Как только задание использует свое распределение времени на заданном уровне (независимо от того, сколько раз оно отказывалось от процессора), его приоритет уменьшается (т. е. он перемещается вниз на одну очередь).
Давайте рассмотрим пример. На рис. 8.6 показано, что происходит, когда рабочая нагрузка пытается использовать планировщик со старыми правилами 4a и 4b (слева), а также с новым правилом 4. Без какой-либо защиты от хаков процесс может выдавать ввод-вывод непосредственно перед окончанием временного среза и, таким образом, доминировать над процессорным временем. При наличии такой защиты, независимо от поведения процесса ввода-вывода, он медленно перемещается вниз по очередям и, таким образом, не может получить несправедливую долю ЦП.
Настройка MLFQ и другие вопросы
С планированием MLFQ возникает еще несколько проблем. Один большой вопрос заключается в том, как параметризовать такой планировщик. Например, сколько должно быть очередей? Насколько большим должен быть временной срез для каждой очереди? Как часто следует повышать приоритет, чтобы избежать голода и учитывать изменения в поведении? Простых ответов на эти вопросы нет, и поэтому только некоторый опыт работы с рабочими нагрузками и последующая настройка планировщика приведут к удовлетворительному балансу.
СОВЕТ: ИЗБЕГАЙТЕ КОНСТАНТ ВУ-ДУ (ЗАКОН ОУСТЕРХАУТА)
Избегать констант вуду - хорошая идея, когда это возможно. К сожалению, как и в приведенном выше примере, это часто бывает трудно. Можно было бы попытаться сделать так, чтобы система усвоила хорошую ценность, но это тоже не так просто. Частый результат: файл конфигурации, заполненный значениями параметров по умолчанию, которые опытный администратор может настроить, когда что-то работает не совсем правильно. Как вы можете себе представить, они часто остаются неизменными, и поэтому нам остается надеяться, что дефолты хорошо работают в этой области. Этот совет принес вам наш старый профессор ОС Джон Остерхаут, и поэтому мы называем его законом Остерхаута.
Например, большинство вариантов MLFQ допускают различную длину временного среза в разных очередях. Очереди с высоким приоритетом обычно задаются короткими временными срезами; в конце концов, они состоят из интерактивных заданий, и поэтому быстрое чередование между ними имеет смысл (например, 10 или менее миллисекунд). Очереди с низким приоритетом, напротив, содержат длительные задания, привязанные к процессору; следовательно, более длинные временные срезы работают хорошо (например, 100 мс). На рис.8.7 показан пример, в котором два задания выполняются в течение 20 мс в самой высокой очереди (с временным срезом 10 мс), 40 мс в середине (с временным срезом 20 мс) и с временным срезом 40 мс в самой низкой.
Реализация Solaris MLFQ - Time-Sharing sheduling class или TS - особенно проста в настройке; она предоставляет набор таблиц, которые точно определяют, как изменяется приоритет процесса на протяжении всего его жизненного цикла, как долго длится каждый временной срез и как часто повышается приоритет задания; администратор может возиться с этой таблицей, чтобы заставить планировщик вести себя по-разному. Значения по умолчанию для таблицы - 60 очередей, с медленно увеличивающейся длиной временного среза от 20 миллисекунд (самый высокий приоритет) до нескольких сотен миллисекунд (самый низкий), а приоритеты увеличиваются примерно каждые 1 секунду или около того.
Другие планировщики MLFQ не используют таблицу или точные правила, описанные в этой главе; скорее они корректируют приоритеты с помощью математических формул. Например, планировщик FreeBSD (версия 4.3) использует формулу для расчета текущего уровня приоритета задания, основываясь на том, сколько процессоров использовал процесс; кроме того, использование со временем уменьшается, обеспечивая желаемое повышение приоритета иным способом, чем описано здесь. Отличный обзор таких алгоритмов использования распада и их свойств см. в статье Epema (Epema’s paper).
Наконец, многие планировщики имеют несколько других функций, с которыми вы можете столкнуться. Например, некоторые планировщики резервируют самые высокие уровни приоритета для работы операционной системы; таким образом, типичные пользовательские задания никогда не могут получить самые высокие уровни приоритета в системе. Некоторые системы также содержат некоторые советы пользователям с целью помочь установить приоритеты; например, с помощью утилиты командной строки nice вы можете увеличить или уменьшить приоритет задания (несколько) и, таким образом, увеличить или уменьшить его шансы на выполнение в любой момент времени. Подробнее см. справочную страницу.
СОВЕТ: ИСПОЛЬЗУЙТЕ СОВЕТЫ ТАМ, ГДЕ ЭТО ВОЗМОЖНО
Поскольку операционная система редко знает, что лучше для каждого процесса системы, часто бывает полезно предоставить интерфейсы, позволяющие пользователям или администраторам предоставлять некоторые подсказки ОС. Мы часто называем такие подсказки советами, так как ОС не обязательно должна обращать на них внимание, а скорее может принять совет во внимание, чтобы принять лучшее решение. Такие подсказки полезны во многих частях ОС, включая планировщик (например, с nice), менеджер памяти (например, madvise) и файловую систему (например, информированная предварительная выборка и кэширование).
MLFQ: резюме
Мы описали подход планирования, известный как многоуровневая очередь обратной связи (MLFQ). Надеюсь, теперь вы понимаете, почему он так называется: он имеет несколько уровней очередей и использует обратную связь для определения приоритета данного задания. История-это ее руководство: отслеживание поведения задачи в процессе работы, и выставление соответствующего приоритета.
Изысканный набор правил MLFQ, разбросанных по всей главе, воспроизводится здесь для вашего удобства:
- Правило 1: Если приоритетом(А) > приоритет(B), А выполняется (B нет).
- Правило 2: Если приоритет (A) = приоритет(B), A & B выполняются циклически, используя временной срез (квантовую длину) данной очереди.
- Правило 3: когда задание поступает в систему, оно помещается в самую высокую очередь (самую верхнюю очередь).
- Правило 4: Как только задание использует свое распределение времени на заданном уровне (независимо от того, сколько раз оно отказывалось от процессора), его приоритет уменьшается (т. е. он перемещается вниз на одну очередь).
- Правило 5: через некоторое время все задания в системе перемещаются в самую верхнюю очередь.
MLFQ интересен по следующей причине: вместо того, чтобы требовать априорных знаний о характере работы, он наблюдает за выполнением работы и соответственно расставляет приоритеты. Таким образом, ему удается достичь лучшего из обоих миров: он может обеспечить отличную общую производительность (аналогичную SJF/STCF) для кратковременных интерактивных заданий, а также является справедливым и поставляет ресурсы для длительных задач с интенсивным процессором. По этой причине многие системы, включая производные BSD UNIX, Solaris и Windows NT и последующие операционные системы Windows, используют форму MLFQ в качестве базового планировщика.