Готовя к публикации очередную статью, продолжение темы"Бегущих огней", я понял, что упустил одну важную, и не самую простую тему. Во многих программа требуется реализация временных задержек, на самое разное время, причем иногда таймер нельзя использовать. А такие задержки нам понадобятся даже в самом первом учебном проекте, ведь таймеры мы еще не изучали.
Вариантов реализации таких задержек несколько, но самый простой это крутиться в каком то цикле не выполняя никаких полезных действий. Это безусловно далеко не самый лучший способ, но, благодаря простоте, он находит довольно широкое применение. И именно этот метод реализуют процедуры, например, Delay, Delay_us, Delay_ms, и тому подобное.
Но такие процедуры есть в библиотеках не всех компиляторов, поэтому иногда их приходится писать самому программисту. Нельзя сказать, что это что-то очень сложное, но использование языка высокого уровня будет не лучшим выбором. Однако, давайте по порядку.
Проблемы с программной реализацией задержки
Самая большая сложность, даже с написанной на ассемблере процедурой задержки, вовсе не зависимость от тактовой частоты, на которой работает микроконтроллер. Основная проблема в прерываниях. Если, конечно, они разрешены. Причем новички часто даже не догадываются о такой особенности.
Предположим, вы написали прекрасную процедуру задержки, которая обеспечивает необходимое время. Но если прерывания разрешены, то нельзя гарантировать, что такое прерывание не возникнет при отработке задержки. А значит, мы получим задержку большую, чем планировалось.
Самое неприятное, что прерывания являются асинхронными событиями, а значит и задержка на не правильное время будет возникать лишь иногда. Возможно, и очень редко. И обнаружить причину редких периодических сбоев в работе устройства будет сложно.
Причем в документации внимание на такой проблеме с прерываниями при использовании процедур программной задержки обычно не заостряют. Не редко об этом вообще не говорится.
В "avr libc user manual" в описании модуля <util/delay_basic.h> есть лишь короткая строчка " It should be kept in mind that the functions described here do not disable interrupts". То есть " Следует учитывать, что описанные функции не запрещают прерывания". Этот модуль определяет процедуры _delay_loop_1 и _delay_loop_2, которые напрямую используются относительно редко.
Зато в описании модуля <util/delay.h> о прерываниях нет ни слова. При том, что именно описываемые этим модулем процедуры _delay_ms и _delay_us обычно и используются в программах. Многие ли будут разбираться, как именно устроены эти функции задержки?
Однако, это касается не только AVR. Это общий момент.
На самом деле прерывания, если разрешены, влияют на точность и стабильность формирования задержки в любом случае, даже при использовании таймера. Просто там это критические ситуации возникают реже, да зачастую могут разрешаться расстановкой приоритетов прерываний.
Особенности реализации программных задержек
Кроме того, нужно учитывать, что любая функция задержки, включая inline функции и макросы, обладает некоторой дискретностью времени задержки. Причем эта дискретность превышает время выполнения одной машинной команды. Исключением является прямая вставка команды NOP, которая обеспечивает задержку, обычно, на один машинный цикл.
Есть и еще одна тонкость. Дело в том, что любая функция задержки (кроме NOP) имеет некоторые накладные расходы. То есть, кроме времени выполнения собственно цикла задержки, некоторое время займет подготовка к выполнению цикла. Сюда же включаются и время вызова процедуры и возврата из нее, если это не макрос и не inline процедура.
Про зависимость от тактовой частоты, думаю, известно всем. Именно по этой причине необходимо указывать тактовую частоту, если указывается время задержки, а не количество машинных циклов.
Думаю, что вполне очевидно, что простой перенос процедуры задержки, причем даже в виде исходного кода, на другой микроконтроллер не возможен. Процедуру придется переписывать.
Гораздо менее очевидно, что простое перемещение процедуры задержки в памяти, например, при изменении программы, может привести к ошибке времени формируемой задержки. Для PIC, например, процедура может попасть на другую страницу памяти, что приведет к вставке дополнительных команд переключения страниц. А для микроконтроллеров с большим объемом памяти процедура может попасть в верхние области, когда для ее вызова потребуются или команды дальнего вызова, или дополнительный код. Что так же может повлиять на формируемую задержку. Аналогичное влияние может оказать и перенос переменной счетчика цикла в другой банк памяти. Или даже изменение способа размещения (статическая, глобальная, локальная в стековом фрейме).
Влияние компилятора и козни оптимизации
Можно сколько угодно говорить, компиляторы, например С, должны быть идеальны и точно соответствовать требованиям стандартов. И что единственно правильным является их использование в рамках тех же стандартов. Реальность же такова, что каждый компилятор имеет свои особенности, а программирование для микроконтроллеров является довольно низкоуровневым, что никак не соответствует описанной в стандарте С абстрактной машине. И оптимизаторы тут добавляют не мало головной боли.
На моем канале есть не мало статей на эту тему, найти их не трудно. Поэтому я не буду повторяться, и даже ссылки на статьи не буду приводить. Просто кратко рассмотрю вопрос. Это касается всех компиляторов и микроконтроллеров. Даже тех, которые мы в рамках данного цикла статей не рассматриваем.
Компилятор преобразует текст программы на языке высокого уровня в машинные коды. При этом он пользуется своими внутренними правилами, которые для разных компиляторов будут разными. И даже один и тот же компилятор может генерировать разные последовательности команд для разных конструкция языка, которые, с точки зрения программиста, делают одно и тоже.
Например, циклы (даже пустые) for, while, do while,которые используют некую целую переменную в качестве счетчика цикла, могут приводить к генерации не только разной последовательности команд (что вполне обосновано), но и разному количеству команд. То есть, и размер кода, и время его выполнения будут разными. При том, что результат выполнения будет одинаков, с точки зрения программиста.
Кроме того, простое обновление компилятора до новой версии может привести к генерации совершенно иного кода. А это изменит и время выполнения циклов задержки. И это отнюдь не страшилка. В уже упоминавшейся документации "avr libc user manual", в описании модуля <util/delay.h> есть примечание
The implementation of _delay_ms() based on __builtin_avr_delay_cycles() is not backward compatible with older implementations. In order to get functionality backward compatible with previous versions, the macro "__DELAY_BACKWARD_COMPATIBLE__" must be defined before including this header file. Also, the backward compatible algorithm will be chosen if the code is compiled in a freestanding environment (GCC option -ffreestanding), as the math functions required for rounding are not available to the compiler then.
То есть, реализация функции _delay_ms основана на встроенной функции __builtin_avr_delay_cycles, что является не обратно совместимым со старыми версиями. И если при модификации старой программы использована иная, более свежая, версия компилятора/библиотеки, нужно принять дополнительные меры, что обеспечить совместимость.
Ну и "вишенка на торте" - оптимизатор. Ваш пустой цикл, который по задумке и должен формировать задержку, может быть спокойно удален оптимизатором. Так как, с точки зрения оптимизатора, он ничего не делает. Причем не важно, будет ли этот цикл вставлен непосредственно в нужное место, например, как макрос, или будет вызываться процедура с таким циклом. В последнем случае и сама процедура, и все ее вызовы, могут быть удалены.
О важности учета особенностей оптимизатора говорит и то, что в уже упоминавшейся документации "avr libc user manual", в описании модуля <util/delay.h> есть примечание
In order for these functions to work as intended, compiler optimizations must be enabled, and the delay time must be an expression that is a known constant at compile-time. If these requirements are not met, the resulting delay will be much longer (and basically unpredictable)...
То есть, без включенной оптимизации функции могут работать не так, как ожидается. Тот факт, что эти функции используют арифметику с плавающей точкой, как раз и показывает, что накладные расходы могут быть довольно большими.
Но и это еще не все. В документации есть отдельная глава посвященная оптимизации. Вот небольшой фрагмент из нее
Programs contain sequences of statements, and a naive compiler would execute them exactly in the order as they are written. But an optimizing compiler is free to reorder the statements - or even parts of them - if the resulting "net effect" is the same.
То есть, оптимизирующий компилятор может изменять последовательность операторов или их частей, если итоговый результат будет тем же самым. Определенные ограничения на свободу действий оптимизатора накладывает работа с volatile переменными.
Однако, даже фрагменты на встроенном ассемблере попадают под такую оптимизацию. Во всяком случае, в avr-gcc. Даже если ассемблерный фрагмент объявлен как volatile, он может быть перемещен относительно остального кода. Правда уже как единое целое.
А оптимизаторы не так уж и редко выполняются над уже сформированной генератором кода последовательности машинных команд. И это касается не только avr-gcc.
Надеюсь, теперь вам стало понятно, что такие простые программные задержки на деле оказываются не так просты. И что использовать языки высокого уровня для их написания не самая лучшая идея.
Тем не менее, я прекрасно понимаю, писать процедуру задержки на ассемблере захотят не многие.
Возможные варианты
По большому счету, вариантов всего четыре.
Готовые процедуры
Если поставляемая с компилятором библиотека (или иная библиотека) предоставляют процедуры задержки, а вас устраивают их ограничения и особенности, то лучшим вариантом будет использовать готовые процедуры.
А не устраивать может многое. Например, та же арифметика с плавающей точкой, если остальная часть программы числа с плавающей точкой не использует. Если опять вернуться к avr-gcc.
Ленивый вариант
Если поставляемые с компилятором библиотеки не имеют процедур программной задержки, а другую библиотеку найти не удается, то придется писать свои процедуры. Если высокая точность формирования задержки не требуется и использовать ассемблер, в любом виде, категорически не хочется, то можно написать на С.
Правда нужно понимать, что ключи компиляции будут иметь важное значение. И придется ограничить рвение оптимизатора используя volatile переменные. А еще, потребуется осциллограф или частотомер (измеритель длительности импульса/периода) на время отладки написанных процедур.
Код процедуры задержки очень прост
Счетчик цикла объявлен volatile, что бы у оптимизатора не было соблазна. Той же цели служит декремент счетчика внутри цикла. Поскольку цикл короткий, то и выполняться он будет быстро. Что бы не выйти за границы 16 бит при при необходимости длинных задержек может потребоваться увеличить время одной итерации цикла. И сделать это можно вставкой дополнительного кода. При этом нужно следить, что бы оптимизатор не мешался.
Теперь остается откалибровать нашу процедуру. Для это нужно написать простую программу, которая реализуется примерно такой алгоритм
- Установить вывод порта в состояние логического 0
- Установить вывод порта в состояние логической 1
- Вызвать процедуру задержки
- Инвертировать состояние вывода порта
- Перейти к шагу 2
Подключаем осциллограф или частотомер к выводу порта и запускаем нашу программу. Причем сначала с параметром 0 (ни одной итерации цикла). Длительность импульса, примерно равная длительности паузы, будет соответствовать накладным расходам процедуры. То есть, это постоянная и неизменная часть задержки.
Теперь меняем параметр вызова процедуры на максимально возможное, в данном случае 16 битное, значение - 0xFFFF или 65535. И снова измеряем длительность импульса или паузы. Теперь это максимально возможная длительность задержки, с учетом накладных расходов.
Осталось немного позаниматься арифметикой. Пусть Т0 это минимальное время задержки, те самые накладные расходы. Тм это максимальное время задержки. Тогда длительность одной итерации цикла, Т1, будет
Т1 = (Тм - Т0) / 65535
Соответственно, мы можем вычислить требуемое число итераций N для задержки на время Т по простой формуле
N = (Т - Т0) * Т1
При этом Т1 будет и дискретностью нашей процедуры задержки.
Понятно, что с большой вероятностью придется подбирать код выполняющийся в теле цикла. Тем не менее, это самый простой способ, который правда требует некоторых измерительных приборов.
Иногда, как в случае наших бегущих огнях, когда нужна всего одна задержка на фиксированное время, которое к тому же можно оценить визуально, можно пойти более простым путем и просто подобрать требуемое число итераций и выполняющий в цикле код.
Вариант для пунктуальных и не боящихся трудностей
В данном случае процедура задержки по прежнему пишется на С, но вместо измерений мы будем анализировать сгенерированный машинный код (точнее, код на ассемблере) и считать время его выполнения. В машинных циклах.
Да, здесь уже появляется ассемблер, но мы не будем писать на нем сами, мы будем анализировать уже готовый код. Наш пример на С будет очень простым
Это тоже самое, что в ленивом варианте, причем без дополнительного кода в цикле. Но добавлена main, что бы оценить накладные расходы.
Итак, что же получится в результате компиляции? Я рассмотрю все три семейства микроконтроллеров.
PIC
Начну с PIC16F630, очень простого микроконтроллера.
Сначала давайте посмотрим на функцию main (строка 25). Мы видим, что для двух вызовов Delay использовано разное количество команд, что вполне объяснимо. На самом деле, есть еще третий вариант, когда параметр вызова занимает лишь младший байт param.
Итак, подготовка к вызову Delay требует от 2 до 4 команд. При этом каждая команда, в данном случае, выполняется за 1 машинный цикл. А вот команда вызова требует 2 машинных цикла.
В самой функции Delay, до команды BTFSC (строка 13), которая завершает проверку counter на 0 и выполняет ветвление, выполняется 6 команд. Каждая требует 1 цикла. Если param равно 0, BTFSC потребует всего 1 цикл, после чего выполнится команда GOTO (строка 14), которая потребует 2 такта. Осталась команда RETURN, которая выполнится за 2 такта.
Таким образом, в функции main потребуется от 4 до 6 машинных циклов, а в Delay 11 машинных циклов. Значит накладные расходы на формирование задержки составят от 15 до 17 циклов. Для упрощения можно считать, что требуется 16 циклов. При тактовой частоте 4 МГц и цикле состоящем из 4 тактов минимальное время задержки составит 16 мкс.
Если param не равняется 0, то в функции Delay по прежнему сначала выполнятся 6 команд, потом BTFSC, которая уже потребует 2 цикла, так как команда GOTO будет пропущена. То есть, потребуется на один цикл больше.
Сам цикл располагается в строках с 11 по 21. Команда BTFSC в строке 18 потребует 1 или 2 цикла. Но вместе с последующей командой DECF время выполнения будет всегда 2 цикла. Почему именно так, оставляю вам "на подумать". Если интересно, можно обсудить это в комментариях.
Итак, время выполнения одной итерации цикла составит 10 циклов. Или 10 мкс, при указанных вше условиях.
Накладные расходы составят от 15 до 17 циклов в main и 4 цикла в Delay (команды до начала цикла, до строки 11). можно считать, что в среднем накладные расходы составляют 20 циклов. Ну а дискретность времени задержки равна времени одной итерации, то есть 10 мкс.
При этом максимальное время задержки составит примерно 655 мс при param=65535. Вот такая арифметика. И измерительные приборы не потребовались.
AVR
Теперь посмотрим, что будет с микроконтроллером ATmega328P, который весьма распространен. Компиляция выполнена avr-gcc версии 10, ключи компиляции -mmcu=atmega328p -save-temps -Os
Тут уже несколько сложнее все выглядит. Н о суть не изменилась.
Теперь у нас в main для вызовов Delay используется одинаковое количество команд. Команда LDI выполняется за 1 цикл, а CALL за 4 цикла. То есть, всего на вызов требуется 6 циклов.
В процедуре Delay, при вызове с параметром 0, будут выполняться команды со 2 по 12 строки. PUSH выполняется 2 цикла, RCALL 3, IN 1, STD 2, LDD 1, OR 1. Итого 16 циклов.
Команда BRNE, так как условие не выполняется, потребует одного цикла, POP 2, RET 4. Это еще 13 циклов.
Таким образом, при нулевом аргументе один вызов Delay будет выполняться 35 циклов. При конфигурации по умолчанию тактовая частота будет 1 МГц, а значит, минимальная задержка составит 35 мкс. Примерно в 2 раза больше, чем в PIC.
Если param не равно 0, то в Delay будут выполнены строки с 2 по 8. Это потребует 13 циклов. С учетом кода в main, получаем накладные расходы 19 машинных циклов. Примерно столько же, сколько и для PIC.
Сам цикл занимает в Delay занимает строки с 9 по 12 и с 18 по 23. Его выполнение занимает 15 машинных циклов. Таким образом, дискретность времени задержки, равная длительности одной итерации цикла, составит 15 мкс при конфигурации по умолчанию.
А максимальная задержка равна примерно 983 мс. Что в полтора раза больше, чем для PIC.
STM8
Осталось рассмотреть, как будет выглядеть результат компиляции для STM8S103F3
На первый взгляд, здесь нет ничего страшного, все очень похоже на предыдущие примеры. Только компилятор постарался и показал количество циклов, требуемое для выполнения каждой команды.
Но на самом деле, в STM8 полное время выполнения команды может меняться в зависимости от предшествующих ей команд и адреса, по которому размещается команда.
Так что с STM8 все очень даже не просто. Более того, подробный разбор тонкостей работы конвейера выходит за рамки тем для начинающих. Однако, я немного внимания этому уделю. В очень упрощенном виде.
Я уже касался немного вопроса работы конвейеров и синхронизации в статье "Микроконтроллеры для начинающих. Часть 18. Еще раз о циклах, тактах, конвейерах и о том, "что у куколки внутри"." Рекомендую ее прочитать.
Итак, в STM8 есть два внутренних буфера. Первый, 64-битный буфер выборки (Fetch buffer). Второй, 32-битный буфер предвыборки (prefetch buffer). В сумме оба буфера могут хранить 96 бит, или 12 байт, информации считанной из памяти команд.
Шина данных памяти программ 32-битная. Выполнение кода из ОЗУ я даже близко не буду сейчас рассматривать. При этом, считывание информации в буфер предвыборки может выполняться не с любого адреса, а только кратного 4 байтам. Это адреса заканчивающиеся на 0, 4, 8, или С. При том, что команды могут иметь длину не кратную 4 байтам и располагаться с начиная с любого адреса.
Если команда занимает более 4 байт (например, имеет префикс замены регистра) или располагается по не выравненному адресу (не кратен 4 байтам) и пересекает границу выравнивания, то выборка команды может потребовать не одного, а двух доступов к памяти.
При этом, несколько коротких команд могут быть выбраны за одно обращение к памяти. А значит, выборка очередной команды требуется не всегда.
Другими словами, очередная команда может потребовать от 0 до 2 циклов выборки. И зависит это от предшествующих ей команд и состояния конвейера. А значит, даже добавление безобидной однобайтной команды NOP где то далеко, но перед нашей командой, может кардинально изменить требуемое число циклов для полной выборки команды.
Декодирование команды не может начаться до ее полной выборки. При этом внутреннее выравнивание команды происходит в буфере выборки в фазе декодирования.
Декодирование, при косвенной адресации, может быть приостановлено для чтения указателя из памяти данных. Количество пропускаемых циклов зависит от размера указателя (шина данных памяти данных 8-битная). Таким образом, декодирование команды может занимать разное количество циклов. При этом непосредственные операнды обрабатываются не в фазе декодирования, а в фазе выполнения.
В фазу выполнения, кроме собственно выполнения операции, производится и сохранение результата в аккумуляторе или памяти данных. При этом могут возникать конфликты доступа к требуемой ячейке памяти. Например, ячейка памяти данных используется и для сохранения результата, и в фазе декодирования последующей команды. Для исключения конфликтов могут вводиться дополнительные циклы ожидания.
Думаю, уже понятно, что предсказать точное время выполнения команды чрезвычайно сложно. Что бы немного облегчить задачу, в документации приводится не время собственно выполнения, а некое усредненное типовое время Cy.
Cy = DecCy + ExeCy - 1
То есть, сумма времени декодирования и выполнения. И именно Cy указано в квадратных скобках в результате компиляции (как и в документации). Cy не всегда точно отражает время выполнения, но во многих случаях им можно пользоваться.
Обратите внимание, что в Cy не включено время выборки команды!
Теперь мы можем попробовать хотя бы примерно оценить наш пример. Давайте посмотрим на процедуру Delay. Она начинается в строке 4 с адреса 0х008024, то есть, адрес выровнен. При этом конвейер пуст, так как команда вызова выполняет сброс конвейера.
Процессор тратит один цикл на чтение 4 байт, то есть, сразу двух команд (строки 4 и 6). Cy обеих команд равен 2. Может показаться, что суммарное время выполнения будет равно 4 циклам. Это не всегда так, потому что декодирование второй команды начнется во время выполнения первой. А Cy это суммарное время декодирования и выполнения. Так что "выполнение" команд может частично перекрываться.
Но у нас в обеих командах используется один и тот же регистр SP в качестве операнда. А это тот самый конфликт доступа. Более того, вторая команда использует косвенную адресацию, а значит, она не может быть декодирована, пока не закончится выполнение первой команды. Поэтому будет пропущено 2 цикла (время выполнения первой команды).
Итак, выполнение двух команд у нас займет 5 циклов, а не 4, как казалось на первый взгляд. Для второй команды не нужно выполнять выборку из памяти. Но во время ее выполнения конвейер произведет чтение очередных 4 байт, которые находятся в строка 7 и 10, начиная с адреса 0х008028 (опять выровненный).
Команда в строке 7 тоже использует регистр SP, но уже в качестве приемника, и снова косвенная адресация. Поскольку предыдущая команда использует SP как источник, конфликта доступа не возникает. А значит, декодирование может выполняться одновременно с выполнением предыдущей команды.
Таким образом, три первые команды будут выполняться 6 циклов, а не 7.
Команда в строке 10 использует SP как источник, и косвенную адресацию. Но ее декодирование может выполняться параллельно выполнению команды из строки 7, так как сам SP не изменяется. И первые 4 команды будут выполняться 7 циклов.
Параллельно со всем этим будут выбраны очередные 4 байта - команды в строках 11 и 12. Ждать здесь не придется.
Но вот команда в строке 11 является командой условного перехода. При этом для ее выполнения нужен результат предыдущей команды, а значит, ее выполнение будет задержано. Поскольку param у нас равен 0, переход будет выполнен, что займет два цикла.
В сумме у нас уже набирается 9 циклов. Но при выполнении перехода конвейер будет сброшен.
Теперь нам снова потребуется 1 цикл для заполнения конвейера. При этом адрес перехода не выровненный. Ближайший выровненный адрес 0х008034. Нам повезло, выбранные 4 байта полностью включают обе наши оставшиеся команды. Выравнивание будет выполнено на этапе декодирования, дополнительных обращений к памяти не потребуется.
Для команды в строке 19 нет конкурирующих команд, поэтому она будет выполнена на 2 цикла. Общее количество циклов 12.
Команда в строке 20 будет декодироваться параллельно с выполнением предыдущей. Поэтому общее количество циклов будет 15, а не 16, как может показаться.
Таким образом, процедура задержки с параметром 0 будет выполняться 15 циклов. А вот определить время требуемое для ее вызова в процедуре main уже сложнее. Мы можем точно определить, что при возврате конвейер будет очищен, а значить потребуется один цикл на его заполнение. Очистка стека, строка 27, займет 2 цикла. Итого, общее время составит уже 18 циклов.
Но мы не знаем что предшествовало, в общем случае, двум командам в строках 24 и 25. Точнее, в данном случае знаем почти наверняка, что была команда перехода или вызова, которые сбросили конвейер. Но в общем случае, вызов Delay может быть в любом месте программы, а мы же не собираемся отдельно анализировать каждый такой вызов.
К счастью, для достаточно больших задержек возникающая погрешность будет не большой. Поэтому мы можем просто считать, что конвейер пуст, с достаточной точностью.
Итак, для заполнения конвейера нам нужен 1 цикл. Адрес у нас выровнен, так что все в порядке. Команда в строке 24 будет выполняться один цикл. Команде в строке 25 не потребуется выборка из памяти, но возникает конфликт доступа, так как обе команды используют регистр Х. Однако, здесь нет косвенной адресации, поэтому декодированию команды ничего не мешает, оно будет выполнено одновременно с выполнением предыдущей команды.
Но возникает проблема, у нас команда в строке 26 выбрана не полностью. А значит, требуется еще одно обращение к памяти программ. Но ждать не придется, так как это будет сделано во время выполнения команды в строке 24 и декодирования команды в строке 25. И выполнение будет перекрываться с выполнением предыдущей команды.
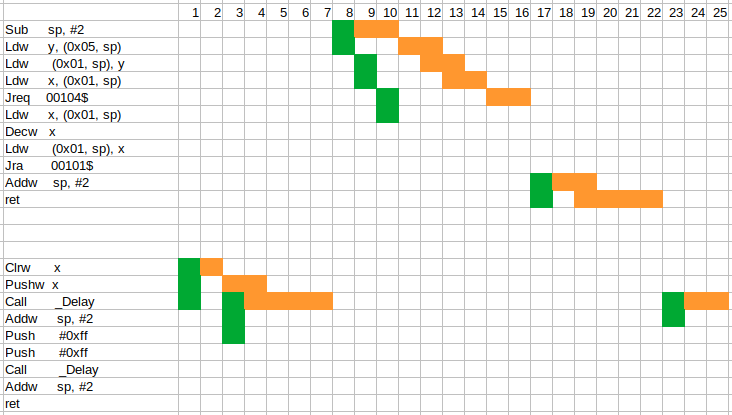
Таким образом, общее количество циклов составит 25. Это и есть минимальное время задержки, в циклах. По умолчанию, STM8 стартует на тактовой частоте 2 Мгц. А значит, минимальная задержка будет равняться 12,5 мкс.
Аналогично, можно вычислить и накладные расходы, и длительность одной итерации цикла. С вашего позволения, я не буду это расписывать. Желающие потренироваться могут сделать это самостоятельно, так же, как я это описал.
Но нужно сказать, что первая итерация цикла будет выполняться за время, отличное от последующих. По той причине, что при последующих итерациях команда в строке 9 с толкнется со сброшенным конвейером и отсутствием конкурирующих команд.
При этом, и это важно, любое перемещение нашей процедуры задержки в памяти программ, сделает все расчеты неверными. Все придется пересчитывать с начала.
Итак, STM8 является более современным микроконтроллером, чем PIC или AVR. Его конвейер позволят выполнять команды более быстро, многие фазы выполняются параллельно. Но, как и все современные процессоры, он очень плохо подходит для формирования временных интервалов программным способом. Так как время выполнения команд стало величиной переменной, причем зависящей от многих факторов. И это даже без предсказаний ветвлений и прочей магии.
Когда мы познакомимся с таймерами, мы будем использовать именно их для формирования временных интервалов. Что позволит исключить почти все факторы нестабильности.
Но пока я буду давать вам готовые решения для формирования программных задержек для STM8 в наших учебных примерах.
Вариант для самых упорных
Остается еще один вариант - написать процедуру прямо на ассемблере. Это может быть встроенный ассемблер компилятора. А может быть отдельный компилятор. В последнем случае процедуру можно поместить в библиотеку. Библиотечный объектный модуль имеет то преимущество, что исключается влияние оптимизатора, так как объектный модуль подключается уже на этапе компоновки.
Заключение
Программная реализация не лучший выбор, но используется довольно часто. При кажущейся простоте, ее реализация имеет не мало подводных камней. Особенно, для современных микроконтроллеров использующих конвейеризацию. Причем не только 8-битных.