К настоящему времени низкоуровневые механизмы запущенных процессов (например, переключение контекста) должны быть понятны; если это не так, вернитесь назад на главу или две и снова прочтите описание того, как это работает. Однако нам еще предстоит понять высокоуровневые политики, которые использует планировщик ОС. Теперь мы сделаем именно это, представив ряд стратегий планирования (иногда называемых дисциплинами), которые различные умные и трудолюбивые люди разработали на протяжении многих лет.
Истоки планирования, по сути, предшествуют компьютерным системам; ранние подходы были взяты из области управления операциями и применены к компьютерам. Эта реальность не должна удивлять: сборочные линии и многие другие человеческие усилия также требуют планирования, и многие проблемы идентичны и уже решались в каких-то областях. И таким образом, наша проблема:
ПРОБЛЕМА: КАК РАЗРАБОТАТЬ ПОЛИТИКУ ПЛАНИРОВАНИЯ
Как мы должны разработать базовую основу для размышлений о политике планирования? Каковы основные предположения? Какие показатели важны? Какие основные подходы использовались в самых ранних компьютерных системах?
Предположения О Рабочей Нагрузке (Workload Assumptions)
Прежде чем переходить к диапазону возможных политик, давайте сначала сделаем ряд упрощающих предположений о процессах, запущенных в системе, иногда совместно называемых рабочей нагрузкой. Определение рабочей нагрузки является важной частью построения политик, и чем больше вы знаете о рабочей нагрузке, тем более тонкой может быть ваша политика.
Предположения о рабочей нагрузке, которые мы делаем здесь, в основном нереалистичны, но это нормально (пока), потому что мы будем расслаблять их по ходу дела и в конечном итоге развивать то, что мы будем называть ... (драматическая пауза)... fully-operational scheduling discipline.
Мы сделаем следующие предположения о процессах, иногда называемых заданиями, которые выполняются в системе:
- Работа каждого задания занимает одинаковое время
- Все задания поступают в одно и то же время
- После запуска каждое задание выполняется до завершения
- Все задания используют только центральный процессор (т. е. они не выполняют ввода-вывода)
- Время выполнения каждого задания известно.
Мы говорили, что многие из этих предположений нереалистичны, но точно так же, как некоторые животные более равны, чем другие в "Скотном дворе" Оруэлла, некоторые предположения более нереалистичны, чем другие в этой главе. В частности, вас может беспокоить то, что время выполнения каждого задания известно: это сделало бы планировщик всеведущим, что, хотя и было бы здорово (вероятно), вряд ли произойдет в ближайшее время.
Показатели Планирования (Scheduling Metrics)
Помимо предположений о рабочей нагрузке, нам также нужна еще одна вещь, позволяющая сравнивать различные политики планирования: метрика планирования. Метрика-это просто то, что мы используем для измерения чего-то, и есть целый ряд различных метрик, которые имеют смысл в планировании.
А пока давайте также упростим нашу жизнь, просто имея одну метрику: turnaround time. Время выполнения задания определяется как время завершения задания за вычетом времени поступления задания в систему. Более формально, turnaround time составляет:
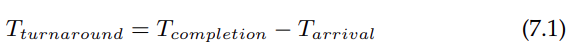
Потому что мы предположили, что все задания приходят в одно и то же время, пока T-arrival = 0 и, следовательно, T-turnaround = T-completion. Этот факт изменится, когда мы ослабим вышеупомянутые предположения.
Обратите внимание, что время выполнения работ-это показатель производительности, который будет нашим основным фокусом в этой главе. Другой интересной метрикой является fairness, измеряемая (например) с помощью Jain’s Fairness Index. Производительность и справедливость часто расходятся в планировании; планировщик, например, может оптимизировать производительность, но за счет предотвращения выполнения нескольких заданий, что снижает справедливость. Эта загадка показывает нам, что жизнь не всегда совершенна.
First In, First Out (FIFO)
Самый простой алгоритм, который мы можем реализовать, известен как First In, First Out (FIFO) или иногда First Come, First Served (FCFS).
FIFO обладает рядом положительных свойств: он явно прост и, следовательно, легок в реализации. И, учитывая наши предположения, работает довольно хорошо.
Давайте вместе сделаем небольшой пример. Представьте себе, что в систему поступают три задания-A, B и C-примерно в одно и то же время (T-arrival = 0).
Поскольку FIFO должен поставить какое-то задание на первое место, давайте предположим, что, хотя все они прибыли одновременно, A прибыл всего на волосок раньше B, который прибыл всего на волосок раньше C. предположим также, что каждое задание выполняется в течение 10 секунд. Каково будет среднее время выполнения этих работ?
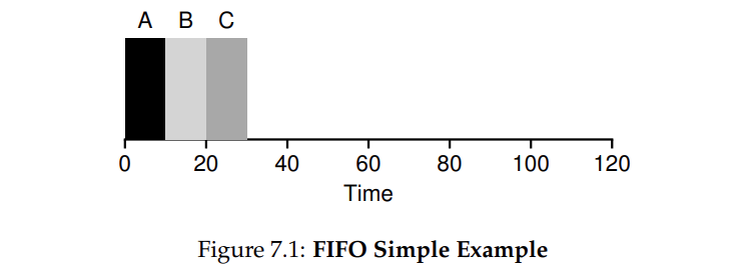
Из рисунка 7.1 видно, что A закончился работал 10 сек, B 20 и С 30. Таким образом, среднее время выполнения для этих трёх заданий - это (10+20+30) / 3 = 20. Да, вычислить turnaround так просто.
Теперь давайте ослабим одно из наших предположений. В частности, давайте ослабим предположение 1 и, таким образом, больше не будем предполагать, что каждое задание выполняется в течение одного и того же времени. Как сейчас работает FIFO? Какую рабочую нагрузку вы могли бы создать, чтобы заставить FIFO работать плохо?
(подумайте об этом, прежде чем читать дальше ... продолжайте думать ... есть идеи?!)
Вероятно, вы уже поняли это, но на всякий случай давайте приведем пример, чтобы показать, как задания разной длины могут привести к проблемам при планировании FIFO. В частности, давайте снова предположим три задания (A, B и C), но на этот раз A выполняется в течение 100 секунд, а B и C-по 10.
Как вы можете видеть на рис. 7.2, задание A выполняется первым в течение полных 100 секунд, прежде чем B или C даже получат шанс выполнить его. Таким образом, среднее время оборота системы велико: мучительные 110 секунд ( 100+110+120 3 = 110).
Эта проблема обычно называется эффектом конвоя, когда потребители ресурса с коротким временем выполнения выстраиваются в очередь за потребителем ресурса с большим временем выполнения. Этот сценарий планирования может напомнить вам об одной очереди в продуктовом магазине и о том, что вы чувствуете, когда видите перед собой человека с тремя тележками, полными провизии, и чековой книжкой; это займет некоторое время
Так что же нам делать? Как мы можем разработать лучший алгоритм, чтобы справиться с задачами, которые выполняются в течение различного количества времени? Сначала подумайте об этом, а потом читайте дальше.
Shortest Job First (SJF)
Оказывается, что очень простой подход решает эту проблему; на самом деле это идея, украденная из исследования операций и примененная к планированию заданий в компьютерных системах. Эта новая дисциплина планирования известна как Shortest Job First (SJF), и ее название должно быть легко запомнить, потому что она достаточно полно описывает политику: сначала выполняется самое короткое задание, затем следующее самое короткое и так далее.
Давайте возьмем наш пример выше, но с SJF в качестве нашей политики планирования. На рис. 7.3 показаны результаты запуска A, B и C. надеюсь, диаграмма прояснит, почему SJF работает намного лучше с точки зрения среднего времени оборота. Просто запустив B и C перед A, SJF сокращает средний turnaround со 110 секунд до 50 ( 10+20+120 3 = 50), ускоряя время выполнения более чем в 2 раза.
СОВЕТ: ПРИНЦИП РАБОТЫ SJF
Shortest Job First представляет собой общий принцип планирования, который может быть применен к любой системе, где воспринимаемое время выполнения заказа на одного клиента (или, в нашем случае, на работу) имеет значение. Подумайте о любой очереди, в которой вы ждали: если учреждение, о котором идет речь, заботится об удовлетворенности клиентов, то, скорее всего, они приняли во внимание SJF. Например, в продуктовых магазинах обычно есть линия "десять предметов или меньше", чтобы покупатели, у которых есть только несколько вещей для покупки, не застряли позади семьи, готовящейся к предстоящей ядерной зиме.
УПРЕЖДАЮЩИЕ ПЛАНИРОВЩИКИ
В старые времена пакетных вычислений было разработано несколько неперемещающих планировщиков; такие системы запускали каждое задание до завершения, прежде чем решить, запускать ли новое задание. Практически все современные планировщики являются упреждающими и вполне готовы остановить один процесс, чтобы запустить другой. Это означает, что планировщик использует механизмы, о которых мы узнали ранее; в частности, планировщик может выполнять переключение контекста, временно останавливая один запущенный процесс и возобновляя (или запуская) другой.
Фактически, учитывая наши предположения о том, что все рабочие места прибывают в одно и то же время, мы могли бы доказать, что SJF действительно является оптимальным алгоритмом планирования. Однако мы изучаем системы, а не теорию или исследование операций; поэтому доказательства не приводятся.
Таким образом, мы приходим к хорошему подходу к планированию с помощью SJF, но наши предположения все еще довольно нереалистичны. Давай ослабим ограничения. В частности, мы можем ориентироваться на предположение 2 предположить, что рабочие места могут появиться в любое время, а не все сразу. К каким проблемам это приводит?
(Еще одна пауза, чтобы подумать ... ты думаешь? Ну же, ты можешь это сделать)
Здесь мы снова можем проиллюстрировать проблему на примере. На этот раз предположим, что A прибывает в t = 0 и выполняется в течение 100 секунд, тогда как B и C прибывают в t = 10 и каждый выполняется в течение 10 секунд. С чистым SJF мы получим график, показанный на рис. 7.4.
Как видно из рисунка, несмотря на то, что B и C прибыли вскоре после A, они все равно вынуждены ждать, пока A завершит работу, и, таким образом, страдают от той же проблемы с конвоем. Среднее время выполнения этих трех заданий составляет 103,33 секунды:
(100 + (110 - 10) + (120 - 10)) / 3
Что может сделать планировщик?
Shortest Time-to-Completion First (STCF)
Чтобы решить эту проблему, нам нужно убрать предположение 3 (что задания должны выполняться до завершения), поэтому давайте сделаем это. Нам также нужны некоторые механизмы внутри самого планировщика. Как вы могли догадаться, учитывая наше предыдущее обсуждение прерываний таймера и переключения контекста, планировщик, безусловно, может сделать что-то еще, когда прибудут B и C: он может упредить задание A и решить запустить другое задание, возможно, продолжив его позже. SJF по нашему определению является не упреждающим планировщиком и, следовательно, страдает от проблем, описанных выше.
К счастью, есть планировщик, который делает именно это: добавляет упреждение к SJF, известному как планировщик кратчайшего времени до завершения первого (Shortest Time-to-Completion First) (STCF) или упреждающего кратчайшего задания первого (Preemptive Shortest Job First) (PSJF). Каждый раз, когда новое задание поступает в систему, планировщик STCF определяет, какое из оставшихся заданий (включая новое задание) имеет наименьшее оставшееся время, и планирует работу. Таким образом, в нашем примере STCF будет упреждать A и запускать B и C до завершения; только когда они будут закончены, будет запланировано оставшееся время A. На рис. 7.5 показан пример.
В результате значительно улучшилось среднее время turnaround: 50 секунд.
((120 - 0) + (20 - 10) + (30 - 10)) / 3
И как и прежде, учитывая наши новые предположения, STCF доказуемо оптимален; учитывая, что SJF оптимален, если все задания поступают в одно и то же время, вы, вероятно, сможете увидеть интуицию, стоящую за оптимальностью STCF.
Новая Метрика: Время Отклика (Response Time)
Таким образом, если бы мы знали длину заданий и то, что задания используют только процессор, а ваша единственная метрика-время выполнения, STCF была бы отличной политикой. На самом деле, для ряда ранних систем пакетных вычислений эти типы алгоритмов планирования имели определенный смысл. Однако появление машин с разделением времени изменило все это. Теперь пользователи будут сидеть за терминалом и требовать интерактивной работы от системы. И так родилась новая метрика-время отклика.
Мы определяем время отклика как время от момента поступления задания в систему до первого запланированного времени. Более формально:
Например, если бы у нас был график из рисунка 7.5 (с прибытием A в момент времени 0, а B и C в момент времени 10), Время отклика каждого задания было бы следующим: 0 для задания A, 0 для B и 10 для C (среднее значение: 3,33).
Как вы, возможно, думаете, STCF и связанные с ним дисциплины не особенно хороши для времени отклика. Например, если три задания приходят в одно и то же время, третье задание должно подождать, пока предыдущие два задания будут выполнены полностью, прежде чем быть запланированным только один раз. Хотя этот подход отлично подходит для улучшения turnaround time, он довольно плох для времени отклика и интерактивности. Действительно, представьте себе, что вы сидите за терминалом, печатаете и ждете 10 секунд, чтобы увидеть ответ от системы только потому, что какая-то другая работа была запланирована перед вашей: не слишком приятно.
Таким образом, мы остаемся с другой проблемой: как мы можем построить планировщик, чувствительный к времени отклика?
Round Robin
Чтобы решить эту проблему, мы введем новый алгоритм планирования, классически называемый циклическим (RR) планированием. Основная идея проста: вместо выполнения заданий до завершения RR запускает задание для отрезка времени (иногда называемого квантом планирования), а затем переключается на следующее задание в очереди выполнения. Он повторяет это до тех пор, пока работа не будет закончена. По этой причине RR иногда называют time-slicing. Обратите внимание, что длина временного отрезка должна быть кратна периоду прерывания таймера; таким образом, если таймер прерывается каждые 10 миллисекунд, временной отрезок может быть 10, 20 или любым другим кратным 10 мс.
Чтобы понять RR более подробно, давайте рассмотрим пример. Предположим, что три задания A, B и C поступают в систему в одно и то же время и что каждое из них должно выполняться в течение 5 секунд. Планировщик SJF запускает каждое задание до завершения перед запуском другого (рис. 7.6). В отличие от этого, RR с временным срезом в 1 секунду будет быстро выполнять задания (рис.7.7).
СОВЕТ: АМОРТИЗАЦИЯ МОЖЕТ СНИЗИТЬ ЗАТРАТЫ
Общий метод амортизации обычно используется в системах, когда существует фиксированная стоимость какой-либо операции. За счет того, что эти затраты происходят реже (т. е. за счет выполнения операции меньше раз), общая стоимость системы снижается. Например, если временной срез установлен на 10 мс, а стоимость переключения контекста составляет 1 мс, то примерно 10% времени тратится на переключение контекста и, таким образом, тратится впустую. Если мы хотим амортизировать эту стоимость, мы можем увеличить временной срез, например, до 100 мс. В этом случае менее 1% времени тратится на переключение контекста, и, таким образом, затраты на нарезку времени амортизируются.
Среднее время отклика RR составляет: (0+1+2) / 3 = 1; для SJF среднее время отклика равно: (0+5+10) / 3 = 5
Как вы можете видеть, длина временного отрезка имеет решающее значение для RR. Чем он короче, тем лучше производительность RR по метрике времени отклика. Однако сделать временной отрезок слишком коротким проблематично: внезапно стоимость переключения контекста будет доминировать над общей производительностью. Таким образом, решение о длине временного отрезка представляет собой компромисс для системного дизайнера, делая его достаточно длинным, чтобы амортизировать затраты на переключение, не делая его настолько длинным, чтобы система больше не реагировала.
Обратите внимание, что стоимость переключения контекста возникает не только из-за действий ОС по сохранению и восстановлению нескольких регистров. Когда программы запускаются, они создают большое количество состояний в кэшах ЦП, TLB, предсказателях ветвей и других аппаратных средствах на кристалле. Переключение на другое задание приводит к тому, что это состояние сбрасывается и вводится новое состояние, относящееся к текущему заданию, что может привести к заметным затратам производительности.
Таким образом, RR с разумным временным отрезком является отличным планировщиком, если время отклика является нашей единственной метрикой. Но как насчет нашего старого друга turnaround time? Давайте еще раз рассмотрим наш пример. A, B и C, каждый с временем выполнения 5 секунд, прибывают в одно и то же время, а RR-это планировщик с (длинным) 1-секундным временным срезом. Из рисунка выше видно, что A заканчивается на 13, B на 14, А С на 15, в среднем на 14. Довольно ужасно!
Поэтому неудивительно, что RR действительно является одной из худших политик, если turnaround time является нашей метрикой. Интуитивно это должно иметь смысл: то, что делает RR, растягивает каждую работу до тех пор, пока может, выполняя каждую работу в течение короткого промежутка времени, прежде чем перейти к следующей. Поскольку turnaround time учитывает только выполнение задачи, RR показывает себя плохо, даже хуже, чем простой FIFO во многих случаях.
В более общем плане любая справедливая политика (например, RR), которая равномерно распределяет ЦП между активными процессами в небольшом масштабе времени, будет плохо работать с такими показателями, как время выполнения. Действительно, это неотъемлемый компромисс: если вы готовы быть несправедливыми, вы можете выполнять более короткие задания до завершения, но за счет времени отклика; если вы вместо этого цените справедливость, время отклика уменьшается, но за счет времени выполнения. Этот тип компромисса распространен в системах; вы не можете и рыбку съесть и на велосипеде покататься.
Мы разработали два типа планировщиков. Первый тип (SJF, STF) оптимизирует turnaround time, но плохо влияет на время отклика. Второй тип (RR) оптимизирует время отклика, но плохо влияет на turnaround. И у нас все еще есть два предположения, которые нужно убрать: предположение 4 (что задания не выполняют ввода-вывода) и предположение 5 (что время выполнения каждого задания известно). Давайте теперь рассмотрим эти предположения.
Включение ввода/вывода
Сначала мы уберём предположение 4 — Конечно, все программы выполняют ввод-вывод. Представьте себе программу, которая не принимает никаких входных данных: она будет производить один и тот же результат каждый раз. Представьте себе программу без выходных данных: это как дерево упавшее в лесу. Никто его не видит и нет никакого значения в том, что оно падало.
Планировщик явно должен принять решение, когда задание инициирует запрос ввода-вывода, потому что выполняемое в данный момент задание не будет использовать процессор во время ввода-вывода; оно блокируется в ожидании завершения ввода-вывода. Если ввод-вывод отправляется на жесткий диск, процесс может быть заблокирован на несколько миллисекунд или дольше, в зависимости от текущей нагрузки ввода-вывода диска. Таким образом, планировщик, вероятно, должен запланировать еще одно задание на ЦП в это время.
Планировщик также должен принять решение, когда завершится ввод-вывод. Когда это происходит, возникает прерывание, и ОС запускает и перемещает процесс, выдавший ввод-вывод, из заблокированного состояния обратно в состояние готовности. Конечно, он может даже решить запустить работу в этот момент. Как ОС должна относиться к каждому заданию?
Чтобы лучше понять эту проблему, предположим, что у нас есть два задания, A и B, каждое из которых требует 50 мс процессорного времени. Однако есть одно очевидное различие: A работает в течение 10 мс, а затем выдает запрос ввода-вывода (предположим здесь, что каждый ввод-вывод занимает 10 мс), тогда как B просто использует процессор в течение 50 мс и не выполняет никакого ввода-вывода. Планировщик запускает А первым и B вторым (рис. 7.8).
Предположим, мы пытаемся построить планировщик STCF. Как такой планировщик должен учитывать тот факт, что A разбивается на 5 подзадач по 10 мс, в то время как B-это всего лишь один запрос процессора на 50 мс? Очевидно, что просто выполнение одного задания, а затем другого без учета того, как учитывать ввод-вывод, имеет мало смысла.
Общепринятый подход заключается в том, чтобы рассматривать каждое 10-мс подзадание задания А как самостоятельное задание. Таким образом, когда система запускается, ее выбор заключается в том, чтобы запланировать 10-мс A или 50-мс B. С STCF выбор ясен: выберите более короткий, в данном случае A. Затем, когда первая подзадача A завершена, остается только B, и она начинает работать. Затем отправляется новое подзадание A, которое вытесняет B и выполняется в течение 10 мс. Это позволяет обеспечить перекрытие, когда процессор используется одним процессом в ожидании завершения ввода-вывода другого процесса; таким образом, система используется лучше (см. рис.7.9).
Таким образом, мы видим, как планировщик может включать ввод-вывод. Рассматривая каждый пакет ЦП как задание, планировщик гарантирует, что процессы, которые являются “интерактивными”, запускаются часто. В то время как эти интерактивные задания выполняют ввод-вывод, выполняются другие задания с интенсивным использованием процессора, что позволяет лучше использовать процессор.
Никаких больше оракулов
Используя базовый подход к вводу-выводу, мы приходим к нашему окончательному предположению: планировщик знает длину каждого задания. Как мы уже говорили, это, вероятно, самое худшее предположение, которое мы могли бы сделать. На самом деле, в ОС общего назначения (как и в тех, о которых мы заботимся) ОС обычно очень мало знает о продолжительности каждого задания. Таким образом, как мы можем построить подход, который ведет себя как SJF/STF без такого априорного знания? Кроме того, как мы можем включить некоторые из идей, которые мы видели с планировщиком RR, чтобы время отклика также было довольно хорошим?
Резюме
Мы представили основные идеи планирования и разработали два семейства подходов. Первый запускает самое короткое оставшееся задание и, таким образом, оптимизирует время выполнения; второй чередует все задания и, таким образом, оптимизирует время отклика. И то, и другое где-то плохо а где-то хорошо, увы, неотъемлемый компромисс, распространенный в системах. Мы также видели, как мы могли бы включить ввод-вывод в картину, но до сих пор не решили проблему фундаментальной неспособности ОС видеть будущее. Вскоре мы увидим, как преодолеть эту проблему, построив планировщик, который использует недавнее прошлое для предсказания будущего. Этот планировщик известен как многоуровневая очередь обратной связи, и это тема следующей главы.



















