Эта технология семантического поиска (поиска по смыслу) позволяет следующее.
✔️ Идентифицировать контент по его смыслу, а не по ключевым словам
✔️ В поисковом запросе используются не ключевые слова, а пример документа — мол, «я ищу документы про это»
✔️ Документ-пример на английском языке используется для поиска близких по смыслу документов «про это» на 20+ языках
✔️ Поиск в терабайтах данных идет на порядок быстрее, чем по ключевым словам
✔️ Проблемы многозначности и двусмысленности слов неявно решаются с помощью семантических сравнений
✔️ Система поиска добавляет новые термины «на лету» без переучивания и вообще без какой-либо переподготовки (т.е. динамически расширяет словарный запас)
Чем это отличается от сегодняшних мейнстримных технологий
Этот необычайно перспективный, абсолютно инновационный и альтернативный (я бы даже сказал, перпендикулярный) современному мейнстриму ИИ метод обработки естественного языка (NPL) основан на вычислительной нейробиологии.
Он называется Семантическая свертка (Semantic Folding) и преобразует текст в двоичные представления, что позволяет осуществлять вычислительную обработку и анализ текста, чтобы сравнивать и связывать разные тексты в обширном существующем или специально формируемом корпусе знаний.
Иначе говоря, Семантическая свертка позволяет сравнивать семантику слов и фраз в зависимости от контекста и оценивать степень их семантической близости. У нас — людей, это называется понимать язык. Такое наше умение принципиально отличает человека от любого современного ИИ, у которого умение понимать текст просто отсутствует.
Современные ИИ основаны на принципиально ином — статистическом подходе, который сегодня встречается повсюду: от онлайн переводчиков до голосовых ассистентов. Отсутствие понимания семантики языка заменяется здесь использованием колоссальной статистики. Переводчик Google Translate не понимает ни слов, ни их контекста. Зато у него есть база статистики, в которой переводимое слово встречается миллиарды раз, и методы машинного обучения, которые натаскиваются (обучаются) решать конкретную задачу — в данном случае, — перевод.
Статистический метод NLP работает повсюду, но есть проблемы. Этот метод требует огромного количества данных для обучения, длительного предварительного обучения алгоритмов и, что самое обескураживающее, широкий спектр интерпретаций — вариантов перевода при полном непонимании контекста.
И все это потому, что статистический метод NLP — это совсем не то, что делает наш мозг для понимания языка, а всего лишь то, чему люди смогли научить компьютер, чтобы он переводил.
Метод Семантической свертки — основа новой технологии
Метод Семантической свертки наоборот, — работает по аналогии с мозгом. И потому его требования к вычислительной производительности, объему данных и времени предварительной подготовки (натаскиванию) несоизмеримо ниже, чем у статистического метода. А спектр интерпретаций — вариантов перевода существенно уже, вследствие «понимания» контекста.
Метод Семантической свертки (см. видео на 4:44 мин) состоит из 3 фаз.
1) Переформатирование текста в SDR
Наш мозг (точнее его неокортекс) одинаковым способом преобразует (свертывает) информацию, поступающую от зрения, слуха, языка и всех иных источников. Всю эту инфу неокортекс преобразует в специальный формат хранения и обработки данных Разреженное Распределенное Представление — Spares Distributed Representation (SDR).
Каждый SDR — это длинный двоичный вектор с очень малым числом 1. Каждая 1 кодирует определенный семантический аспект части входного текста (слова или фразы). Активация того же бита в 2х разных SDR означает, что они семантически близки, как минимум в том аспекте, что кодирует эта 1.
2) Формирование семантической карты
По единому, универсальному (для языка, зрения и слуха) алгоритму на основании SDR формируется семантическая карта.
— В тексте выделяют смыслосодержащие части — т.н. Лоскуты.
— Лоскуты распределяют по 2мерной решетке, так чтобы лоскуты близкого смысла находились как можно ближе друг к другу, а далекие по смыслу были тем дальше, чем дальше их смысл.
— Близкие лоскуты содержат некое число одних и тех же терминов.
— Сгруппированная по темам решетка составляет семантическую карту.
Каждый лоскут имеет 2 координаты, определяющие его место на семантической карте.
3) Генерация семантоскопических отпечатков
— Для каждого слова проверяется, есть ли оно в конкретных Лоскутах.
— Если есть, то координаты этого Лоскута заносятся на пустую Семантическую карту.
— Когда позиции всех содержащих слово Лоскутов нанесены на Семантическую карту, ее называют семантоскопический/семантический отпечатков — Semantic Fingerprints.
— Совокупность семантоскопических отпечатков формирует семантический словарь.
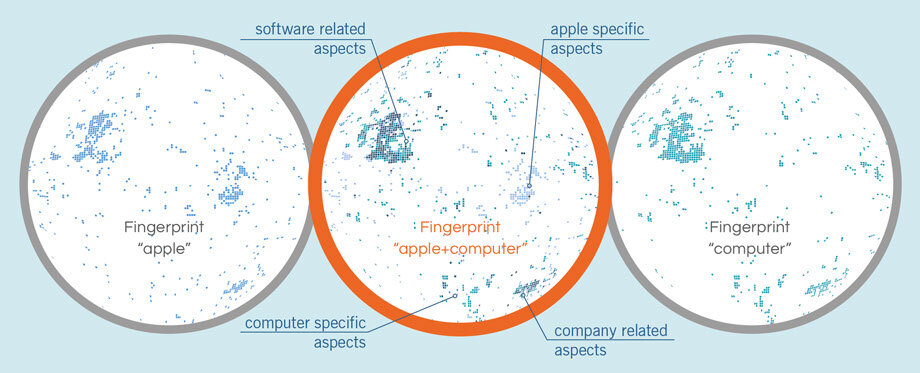
Как это работает на практике, см. в вышеупомянутом видео на примере слова «organ» (орган) в его разных семантиках/контекстах (коих, как минимум, 12).
В ролике показано, что семантоскопический отпечаток слова орган содержит в себе Кластеры Лоскутов: пианино, печень, церковь — т.е. слов, связанных с разной семантической трактовкой слова орган (музыкальной, анатомической, религиозной).
И если входная фраза, например, «орган и пианино — музыкальные инструменты», то чтобы ее осмысленно перевести:
а) для каждого из 5 слов строится его семантоскопический отпечаток;
б) все 5 отпечатков интегрируются в интегральный упрощенный отпечаток, на котором отмечаются только биты, превышающие т.н. порог разряженности (примерно 2% всех битов отпечатка);
в) интегральные отпечатки семантически близких фраз имеют похожие области (как, например, у фразы «орган и пианино — музыкальные инструменты» и фразы «Иоганн Себастьян Баха был композитор эпохи барокко»)
г) тогда как отпечатки семантически далеких фраз не имеют похожих областей (как, например, та же фраза «орган и пианино — музыкальные инструменты» и фраза «Рыбак выводит лодку из гавани»)
И все это вычисляемо, причем, быстро и точно.
Как работает технология семантического поиска
- Для каждого документа в поисковой базе строится его семантоскопический отпечаток (СО).
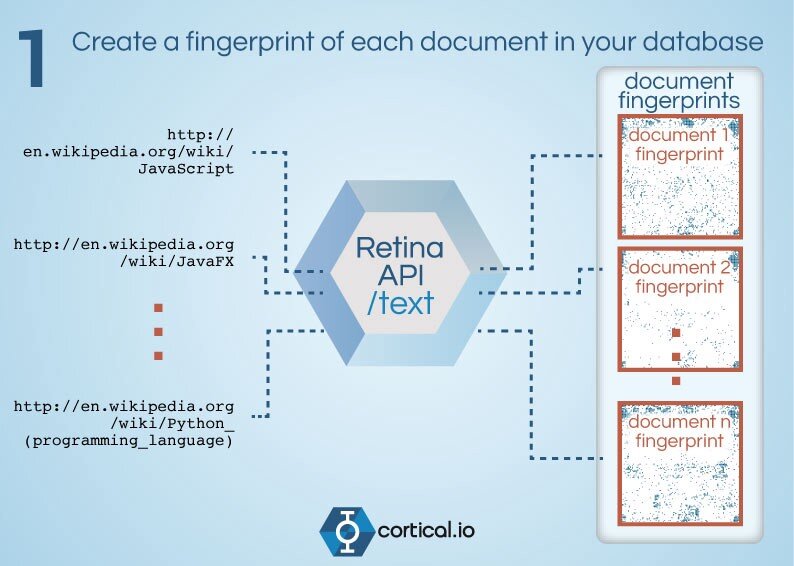
2. Строится СО документа-примера (близкого по смыслу к тому, что ищется)
3. Система семантического поиска сравнивает СО документа-примера и документов в базе и рассчитывает их семантическую близость
4. Результат поисковой выдачи настраивается по 2м параметрам: минимальная семантическая близость и максимальное число документов выдачи.
5. Для индивидуализации каждого поискового запроса строится его собственный СО.
6. Строится поисковый рейтинг документов на основе индивидуализированных поисковых запросов (этот рейтинг индивидуален для каждого пользователя, т.к. отражает его понимание семантической близости документов в выдаче по его заросам).
Подробней см. здесь.
Если кто-то подумает, что вышеизложенное — лишь новая непроверенная идейка, — это совсем не так.
— Метод Семантической свертки разрабатывался в виде технологии 6 лет и имеет крепкое научно-теоретическое обоснование.
— В 2017 году технология выведена на коммерческий рынок и имеет солидных заказчиков.
— Эта технология названа экспертами IDC и Gartner самой инновационной, прорывной и интригующей технологией в области ИИ, соответственно, в 2016 и 2017.
— N.B. Эта технология, уже называемая «Google for Business», отлично работает на внутренних базах документов отдельных компаний (например, Фольксваген), но пока не может заменить поисковые системы на статистическом подходе (Google, Яндекс и т.п.) для массового применения. Причина в том, что пока что не разработана аппаратная реализация основы метода Семантической свертки, и все «семантические вычисления», по сути, эмулируются на обычных компьютерах, изначально для этого не приспособленных.
Но это временно. И над этим ведется работа. В том числе, такими серьезными игроками, как IBM.
И самое важное
Основа метода Семантической свертки — Spares Distributed Representation (см. выше) — наряду еще с двумя супер-прорывными теоретико-технологическими инновациями,
составляют единую полномасштабную альтернативу всему современному мейнстриму ИИ.
Эта альтернатива
✔️ не только позволяет решать уже решаемые задачи, типа распознавания образов, на качественно ином уровне,
✔️ но и способна вплотную приблизить человечество к созданию «Сильного ИИ».
Об этом в следующих постах.
_________________________
Дополнительные материалы:
— простенькое изложение The Cortical Engine for Processing Text: видео на 12 мин
— более подробное изложение того же из уст сооснователя компании: видео на 33 мин
_________________________
Хотите читать подобные публикации? Подписывайтесь на мой канал вТелеграме, Medium, Яндекс-Дзене
Считаете, что это стоит прочесть и другим? Дайте им об этом знать, кликнув на иконку “понравилось”.