Центральные языки на этой карте могут и не иметь самого большого количества носителей, однако они служат «общими» языками для общения элит.
В молодом направлении Big Data есть свои восходящие звезды и многообещающие лидеры, один из самых ярких это Цезарь Хидальго — профессор MIT Media Lab, разработчик онлайн-платформы визуализации данных о торговых связях между разными странами мира Observatory of Economic Complexity, и один из “50 человек, которые изменят мир” по версии журнала Wired.
Несколько лет назад Цезарю и его боевым товарищам захотелось исследовать взаимосвязь языковых узлов в Интернете. Языки отличаются по значимости по куче причин: начиная от технических и заканчивая демографическими. Задачу ставили себе амбициозную — определить глобальную значимость языка, которая не зависит от простых демографических и экономических показателей. О том, что из этого получилось, читайте в посте ниже.↓.
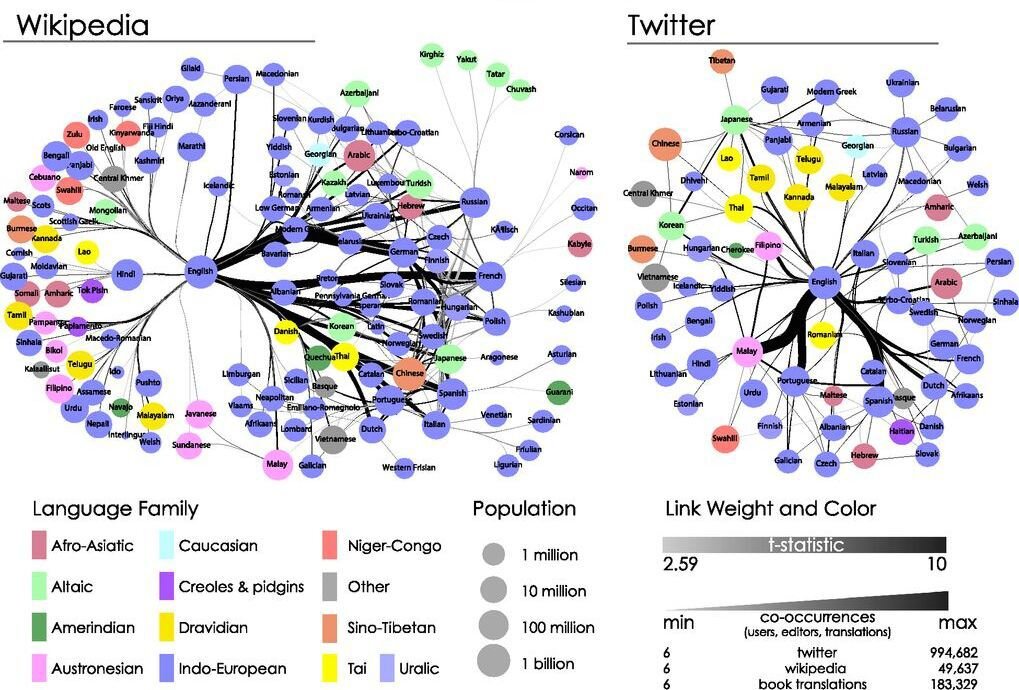
Основная информация в трех глобальных языковых сетях (GLN) содержится на английском языке — центральном, а также нескольких менее распространенных: испанском, немецком, французском, русском, португальском и китайском. Значимость языка находится в прямой зависимости от числа популярных людей, говорящих на нём. Положение языка в GLN также способствует привлечению внимания к его носителям и к производимому ими культурному содержанию.
Первый вопрос, конечно, в том, как измерить глобальное влияние языка. До этого исследования опирались на численность и благосостояние носителей языка. Однако исторически сложилось так, что распространение языка требовало серьезной политической поддержки, поэтому такие показатели не сильно влияют на глобальность языка, так как его носители и их богатство могут быть сосредоточены в относительно малом масштабе. Другой метод измерения глобального влияния языка состоит в определении того, кто является его носителем, а также на связь между носителями. Лингвист Дэвид Кристалл утверждает: «Популярность языка не имеет ничего общего с количеством его носителей. Намного важнее то, кем они являются». В прошлом латынь была общеевропейским языком не потому, что она была родным языком для большинства европейцев, а потому, что являлась языком Римской империи, а позже Католической церкви, ученых и педагогов. Использование латыни элитами и связь между ними, помогли ей продержаться в качестве универсального языка более 1000 лет.
Фулсайз изображение.
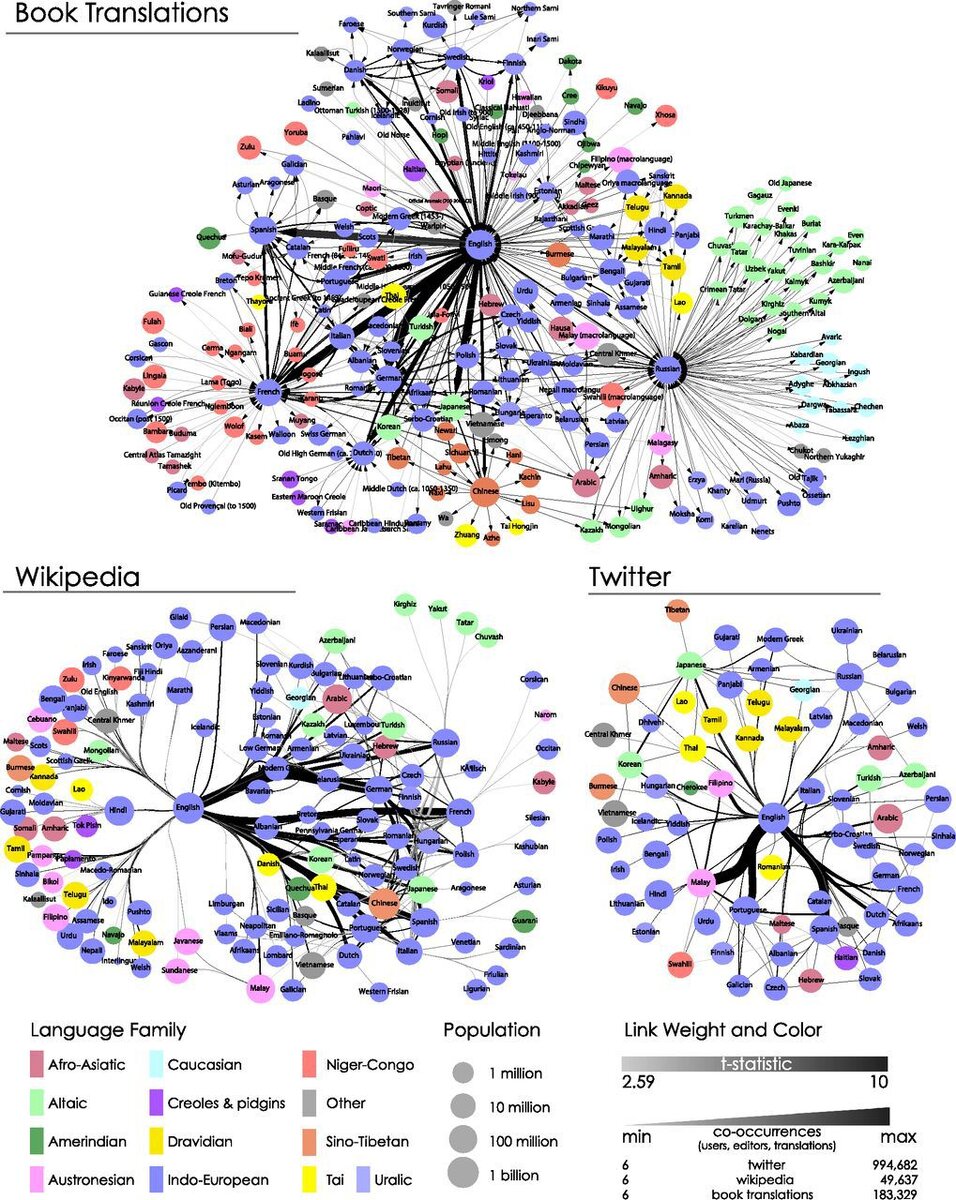
Для начала посмотрим на коллекцию более 2,2 миллионов книжных переводов, составленную по проекту ЮНЕСКО. Этот набор данных позволяет отобразить сеть книжных переводов от авторов и профессиональных переводчиков. Он строился на основе рыночного спроса на книги на разных языках. Каждый перевод с одного языка на другой формирует связь. Затем мы наносим на карту мультиязычную сеть, используемую редакторами Википедии. Здесь связь между языками образуется, когда пользователь редактирует статью в одной языковой версии Википедии и со значительной долей вероятности отредактирует ее в другой языковой версии. И наконец, мы наносим на карту сеть совместного использования языков в Твиттере. Здесь связь образуется, если пользователь пишет сообщение на одном языке и с большой долей вероятности напишет его на другом.
Языки имеют непропорциональную степень влияния, поскольку некоторые обеспечивают прямые и косвенные пути перевода между большинством других языков мира. Например, чтобы слова испанца мог понять англичанин, нужен двуязычный носитель английского и испанского. Однако носителю языка мапудунгун могут стать понятны слова вьетнамца только через обходные пути, например по схеме: вьетнамский — английский, английский — испанский, испанский — мапудунгун. В обоих случаях испанский и английский языки вовлечены в процесс связи и выступают в роли глобальных языков.
Влияние глобальных языков
По логике, англичанину, как находящемуся на одном из узлов, легче влиять на языковую сеть, чем жителю Непала. Чем глобальнее язык, тем больше стимулов создавать на нем контент и переводить на него информацию с менее популярных языков. Например, репортер, желающий распространить новость о крупном мероприятии по всему миру, будет делать это на глобальном языке.
Затем Цезарь собрал данные Твиттеру из более чем одного миллиарда твитов, опубликованных между 6 декабря 2011 и 13 февраля 2012. Язык каждого твита был обнаружен с помощью Chromium Compact Language Detector после очистки от хештегов, ссылок и смайликов. Использовались только те сообщения, где шанс ложного срабатывания был менее 10%. Конечный набор данных состоит почти из 550 миллионов твитов на 73 языках, созданных более 17 миллионами уникальных пользователей. Два языка считаются связанными, если пользователь написал твит на одном языке и с большой долей вероятности напишет его на другом.
Набор данных из Википедии был составлен при редактировании истории всех языковых разделов Википедии, написанных в конце 2011 года. После удаления информации от ботов и применения фильтров, получилось 382 миллиона правок на 238 языках от 2,5 миллионов уникальных редакторов. Здесь два языка оказались связанными, если пользователь отредактировал статью на одном языке и с большой долей вероятности сделал это же на другом.
Набор данных индекса переводов (ИП) состоит из 2,2 миллионов переведенных книг, изданных между 1979 и 2011 в 150 странах более чем на тысяче языков. Набор данных содержит список переводов, а не список переведенных книг. Каждый перевод в нем учитывается отдельно, например, 22 независимых перевода «Анны Карениной» Толстого с русского на английский. В отображении сети мы учитываем каждый перевод отдельно, и в этом случае учитывались 22 перевода, а не один. Также отметим, что источник перевода может отличаться от языка оригинала книги. Например, в ИП содержатся данные о 15 переводах «Тома Сойера», причем 13 из них были сделаны непосредственно с английского, а 2 — с испанского и галисийского. Эта характеристика набора данных позволяет определить промежуточные языки для перевода.
Во всех трех случаях мы изобразили похожие языки в соответствии со стандартом ISO 639-3(10). Например, индонезийский и малазийский языки закодированы как малайский, а все диалекты арабского языка — как арабский.
Результаты
Как видно из результатов, язык с большим количеством связей в одной GLN будет иметь много связей и в другой сети. Положительные корреляции выражений и связь в языковых парах говорят о том, что все три GLN подобны с точки зрения силы связей и количества представителей той или иной группы. Интересно, что общие черты, наблюдаемые в трех GLN, определяются, судя по всему, необходимостью наличия определенных литературных навыков для участия в каждой из этих сетей. Сеть книжных переводов является самой требовательной к этому фактору(поскольку в ней находятся авторы и профессиональные переводчики), Твиттер же наименее требователен(так как состоит из коротких сообщений, которые может публиковать любой человек с доступом в Интернет). Википедия является серединой между книжными переводами и Твиттером с точки зрения необходимых литературных навыков, а ее GLN также занимает середину с точки зрения подобия.
Есть гипотеза о том, что человек переводит информацию с центрального языка на свой родной, так как она больше заслуживает внимания, или гипотеза о том, что человек, родившийся в стране с центральным языком имеет больше шансов для достижения мировой известности.
Можно утверждать, что периферийное расположение языков хинди, китайского и арабского в GLN происходит из-за недостаточного представления в мире этих и некоторых других языков, которые к ним подключаются. Эти языки могут быть центральными в различных СМИ, однако их слабая роль в трех глобальных сетях — Твиттер, Википедия и сеть книжных переводов, ослабляет их претензии на глобальное влияние. Кроме того, китайский, арабский и хинди не могли бы быть центральными языками, даже если бы в базах данных была бы лучше указана их связь с различными региональными языками, так как центральный язык должен соединять даже очень отдаленные языки, а не только местные.
Лекция
Цезарь Хидальго может много рассказать про важность работы с большими данными. Он считает, что любой экономический рост — это частный случай роста информации во Вселенной. При этом рост информации в экономиках ограничивается способностью людей формировать социальные сети.
п.с. Цезарь выступал у нас в Digital October 22 апреля с открытой лекцией (телемост) «Почему объем информации все время растет?».
Пишите нам: info@newprolab.ru
А больше информации можно найти на сайте и facebook



















