Загадки Digital-маркетинга
308
подписчиков
Блог Дмитрия Тумайкина, автора надстройки SEMTools, эксперта по SEO и контекстной рекламе. …
Как я оптимизировал инструменты для анализа семантики: технические детали, кейсы и выводы из стрима
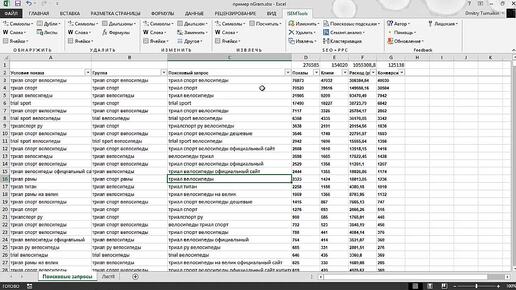
Всем привет! С вами на связи автор надстройки !SEMTools для Excel Дмитрий Тумайкин. Вчера (20 марта 2024) я провел стрим, где подробно разобрал обновления своих инструментов для работы с CSV-файлами и кластеризации семантики. Если вы пропустили — вот запись: В этой статье — структурированный пересказ с акцентом на технические нюансы, примеры и выводы. Поехали! Исходные CSV-файлы из Букварикса содержат избыточность: каждый запрос повторяется 9-15 раз (по числу доменов в выдаче). Например, для Москвы размер файла достигал 90 ГБ в UTF-8.
Формат вывода одной ключевой фразы до оптимизации:
"купить пуф", 1500, 300, 10000, hof...
ChatGPT API увидел свет 1 марта 2023 года, и это стало поистине революционным событием. Потому что теперь воспользоваться Всеми возможностями искусственного интеллекта который может во многих задачах превосходить вас, можно не только в браузере. Что умеет ChatGPT? Во-первых — это выдавать справочную информацию различного рода. Нейронная модель знает практически всё — это как Википедия, которая может с тобой ещё и разговаривать. Во-вторых — решать задачи. Это именно интеллект, и он может решать математические, логические и многие другие задачи. Дайте ему на вход определённую информацию, скажите, что с ней сделать — и он сделает. Причём Вы можете не давать ему эту информацию непосредственно. Вы можете просто сказать ему найти её и он наверняка найдёт её самостоятельно. Один важный момент — эта информация должна датироваться не позднее сентября 2021 года, о фактах, случившихся позднее, даже самая продвинутая модель не знает. Перефразирует, переведет на другой язык, проанализирует и сделает выборку нужных вам данных из текста. Сделает выводы, если попросите. Научитесь задавать ему вопросы, и он напишет вам статью, эссе, диссертацию, курсовую. Конечно, не стоит переоценивать инструмент. Это всё ещё программный интерфейс, не способный отличать правду от неправды, дотошно копаться в фактах в поисках истины. Поэтому порой информация которую он выдаёт и аналитические выводы в том числе, могут быть недостоверными, не точными, некорректными. Ну что греха таить, этому подвержены и многие люди. Так или иначе я не мог пропустить эту новость и реализовал доступ к своей надстройке для Excel !SEMTools. Самая продвинутая модель chatgpt-3.5-turbo доступна и выдает шикарные результаты прямо на лист. Подробнее читайте на моем сайте: ChatGPT в вашем Excel
Сумма прописью с копейками в Excel одной формулой
Бухгалтерам и HR-специалистам очень нужна формула, которая преобразует число в его текстовый вариант суммы с копейками.
Для различных документов.
Большинство решений в интернете - очень сложные
Вот простое...
8 видов ошибок директолуха при работе со стоп-словами
Директолух - на то и директолух, чтобы допускать ошибки. От ошибок не застрахован никто. Но основные ошибки директолухов случаются от того, что те не знают, что это ошибки. А посему не стремятся их исправлять. Отсюда и эта статья. Особый класс ошибок связан со стоп-словами в Яндекс.Директе. Стоп-слова Яндекс-директа - необычная сущность. Их список доподлинно неизвестен, разные интерфейсы Яндекса по-разному определяют их. Более того, их список иногда меняется. Но ключевой момент заключается в том, что стоп-слова имеют колоссальное влияние на эффективность контекстной рекламы...
Мультитриггеринг в PPC и как его посчитать
Это когда по одному поисковому запросу может показаться несколько ключевых слов в аккаунте.
У вас такого нет? :) Конечно же, есть. И это плохо. Очень плохо. Когда мультитриггеринг есть - это приводит к проблемам. Проблемы, к которым приводит мультитриггеринг 1. Мультитриггеринг ключевых слов - это одновременно и мультитриггеринг текстовых объявлений, иными словами, на один запрос вы не очень предсказуемым образом посылаете разные маркетинговые сообщения. 2. Провоцирует перерасход бюджета и повышает...
Частотный словарь n-грамм в семантическом ядре
Применение в контекстной рекламе, SEO и аналитике Перед прочтением рекомендуется прочитать предыдущую статью про частотный словарь - что это такое и почему важно.
А также про n-граммы:
https://ru.wikipedia.org/wiki/N-грамма А сегодня я расскажу о существенном апгрейде возможностей аналитики семантического ядра. Если в прошлый раз весь анализ строился на подсчете упоминаемости единичных слов, то теперь есть возможность подсчитывать не только слова, но и их сочетания, вплоть до 5-словников. Также...
"Телепорт" из Директа в Google Ads в Excel
Все просто. 1 клик. Никаких длинных инструкций. Скачать надстройку для Excel можно по адресу https://bit.ly/SEMTools Ни для кого не секрет, что классическая формула преобразования аккаунта Яндекс Директа в AdWords (Google Ads) выглядит так: Единственная проблема в том, что последний этап довольно медленный, особенно сложно в нем то, что нужно преобразовывать кроссминусовку из строчного в табличный вариант. В связи с этим на рынке появилось немало инструментов, предлагающих бесплатно и небесплатно услугу переноса аккаунта...
Статистический подход к семантике в поисковой рекламе: как сделать свой лемматизатор и генератор словоформ в Excel
Который не генерирует десятки бессмысленных словоформ, с помощью Букварикса, Mystem и Excel.
В этой статье я расскажу, как и зачем создавал собственный файл генерации словоформ на базе словаря Зализняка, Opencorpora и других инструментов Глоссарий Лемматизация - приведение слова к его лемме.
Лемма - начальная форма.
Нормализация - сокращение избыточности для обеспечения компактного хранения данных
Неявные дубли - слова и фразы, отличающиеся хотя бы на один символ, но в том или ином контексте являющиеся...
Частотный словарь: что такое, зачем и как составить
Настоящий директолух, исходя из специфики своих задач, просто обязан работать с семантическими ядрами. И чем больше ядро, тем выше его самооценка.
Однако, при работе с объемами уже более 1000 фраз ручная работа становится нерентабельной, особенно, если вы специалист на стороне агентства и получаете лишь свой процент от небольшого процента агентства от прибыли клиента, которую приносит ваша работа. Нужно автоматизировать. Но автоматизировать работу умеет далеко не каждый директолух, и поэтому настраивает рекламу на пределе своих человеческих возможностей (если вообще работает на пределе)...
Клиентский спрос в мире альтернатив и его семантическое отражение
Профессора мединститута на лекции совершенно не слушают. Он, чтобы привлечь внимание, неожиданно говорит:
- А чтобы не забеременеть - нужно пить хорошо заваренный зеленый чай!
Аудитория разом притихла. Женский голос из аудитории:
- До или после "того"?
- Вместо "того"! А теперь продолжим. Собственно, о чем я. Взаимодействие пользователя с продуктом, сильно утрируя, тоже можно разделить на 3 этапа-случая - ДО, ПОСЛЕ и ВМЕСТО. Поисковые запросы пользователей во всех вариантах так или иначе затрагивают продукт/услугу, но взаимодействие с ними может быть нам неинтересно...
Почему нельзя смотреть отчеты по поисковым запросам в Метрике и Analytics
Или систематическая ошибка выжившего Многие специалисты по контекстной рекламе, с которыми мне приходилось общаться, рекомендуют смотреть отчет по поисковым запросам в Метрике. Однако зачастую это может оказаться не тот отчет, который нужен специалистам на самом деле. Потому что есть еще отчет по поисковым запросам в самом Яндекс.Директе. Для понимания нужно рассмотреть такой психологический термин, как систематическая ошибка выжившего Если кратко - когда по одной группе («выжившим») есть много...
5 инсайтов, которые можно получить в процессе анализа поисковых запросов
Многие маркетологи при анализе эффективности рекламных кампаний нижним уровнем считают уровень ключевых фраз. Однако, это не так. Ниже уровня ключевых фраз есть еще один уровень, самый интересный, но при этом сложнее всего поддающийся анализу - поисковых запросов, как правило, в несколько раз больше, чем ключевых фраз. Большинство систем автоматизации маркетинга также импортируют из систем статистику только до уровня ключевых фраз. Иногда привыкший к своей системе автоматизации специалист в интерфейсы и отчеты Яндекс...