Генерация массива модельных данных

(описание используемых условных обозначений, а также список других публикаций канала по теме электронных таблиц, находится здесь).
Мне неоднократно доводилось сталкиваться с такой ситуацией: необходимо создать файл электронной таблицы, в который регулярно будут вноситься некие данные и при этом в нём должна производиться некоторая первичная обработка введённых значений. Характер обработки обычно известен, но главное, чего при этом не хватает – так это самих данных, что затрудняет оценку работоспособности производящих вычисления формул и качество оформления самой таблицы (в смысле удобства использования и наглядности представления величин).
Чтобы было яснее, представим себе следующий модельный случай. В окрасочном цеху производится нанесение слоя грунтовки на автомобильные кузова методом электроосаждения и ежедневно для контроля технологического процесса окрашивается тестовая металлическая пластина, на которой впоследствии осуществляется измерение толщины полученного слоя лакокрасочного материала. Замеры выполняются в девяти точках пластины – их значения должны заноситься в таблицу, где ещё должно высчитываться усреднённое значение толщины нанесённой грунтовки. Выглядеть оформление результатов в этом случае может примерно так:
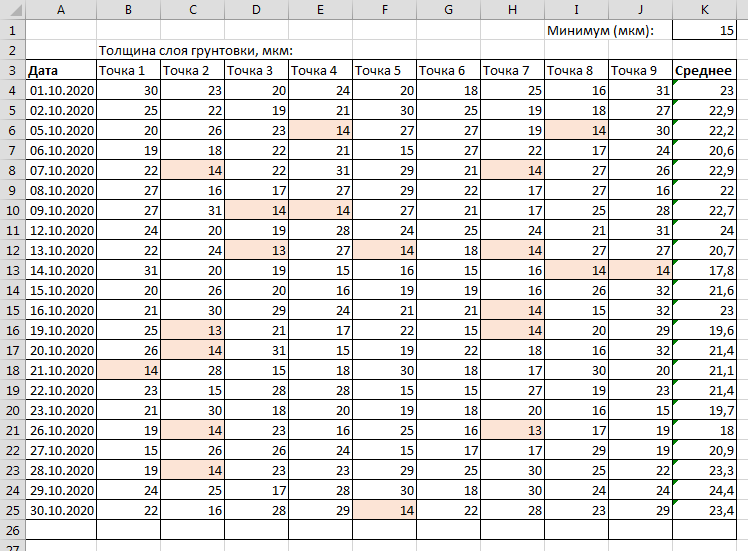
Если файл подобного отчёта только разрабатывается, а сами результаты для его наполнения ещё не собраны, то здесь сумеет пригодиться простенький вспомогательный инструмент, работа которого основана на функции табличного процессора, генерирующей случайные числа, поскольку придумывать целый массив данных и набивать его вручную может оказаться слишком трудоёмко. Именно такое вспомогательное средство и предлагается подготовить в настоящей заметке. В нём будут создаваться случайные числа в рамках определённого числового интервала, округленные до некоторой наперёд заданной степени точности.
Сначала создайте новую книгу и оформите лист в ней следующим образом:
В нём в ячейках “B2” и “B3” необходимо будет указывать соответственно начальную (a) и конечную (b) границы интервала, а в “B5” – количество знаков после запятой до которых надо округлять каждое сгенерированное число. Хотелось бы напомнить (Пособие, с. 86), что функция
СЛЧИС()
RAND()
возвращает случайное число x{0;1} с равномерным распределением, принимающее значение в интервале от 0 до 1. В нашем случае требуется создание случайного числа x{a;b} в интервале от a до b. Для его получения следует величину x{0;1} умножить на b – a (то есть на длину самого интервала) и прибавить к произведению число a (начало интервала) – иными словами x{a;b} можно получить из x{0;1} так:
x{a;b} = x{0;1}·(b– a) + a
На основании сказанного в ячейке “E2” необходимо разместить следующую формулу:
=ОКРУГЛ(СЛЧИС()*($B$3-$B$2)+$B$2;$B$5)
=ROUND(RAND()*($B$3-$B$2)+$B$2;$B$5)
В ней использована имеющая два аргумента функция
ОКРУГЛ( ; )
ROUND( ; )
Первый аргумент у неё – округляемая величина (сгенерированное случайное число x{a;b}), а второй – количество знаков после запятой, до которых нужно округлить значение первого аргумента.
Теперь остаётся при помощи маркера заполнения размножить формулу в “E2”во всём диапазоне “E2:X26” и генератор массива модельных данных готов – надо лишь скопировать блок ячеек необходимого размера и применить опцию «Специальная вставка» (Пособие, с. 52) по месту назначения.
Так, в случае с приведённым в начале заметки примером замеров толщины слоя грунта на тестовых пластинах, показанный там массив 22×9 «исходных» данных был создан на основе следующих начальных параметров:
Округлённые до целых числа в интервале от 13 до 32 были выбраны из-за наличия критерия минимально допустимой толщины для слоя грунтовки (15 мкм, ячейка “K1”), чтобы в совокупности сгенерированных значений появились величины, не укладывающиеся в указанный допуск. Это позволяет, например,проверить работу применённого в создаваемом отчёте условного форматирования, подсвечивающего цветной заливкой выходящие за разрешённые рамки числа.
Перечень публикаций на канале