Авторы Саймон Фридер, Лука Пинчетти, Райан-Рис Гриффитс, Томмазо Сальватори, Томас Лукасевич, Филипп Кристиан Петерсен, Алексис Шевалье и Юлиус Бернер
Абстракт
В статье исследуются математические возможности ChatGPT, проверяя его на общедоступных наборах данных, а также созданных вручную, и измеряя его производительность по сравнению с другими моделями, обученными на математическом корпусе, таком как Minerva. Мы также проверяем, может ли ChatGPT быть полезным помощником для профессиональных математиков, эмулируя различные варианты использования, возникающие в повседневной профессиональной деятельности математиков (ответы на вопросы, поиск теорем). В отличие от формальной математики, где доступны большие базы данных формальных доказательств (например, Lean Mathematical Library), текущие наборы данных математики естественного языка, используемые для эталонного тестирования языковых моделей, охватывают только элементарную математику.
Авторы решают эту проблему, вводя новый набор данных: GHOSTS (ПРИЗРАКИ). Это первый набор данных на естественном языке, созданный под руководством работающих исследователей в области математики, который (1) направлен на охват математики для выпускников и (2) предоставляет целостный обзор математических возможностей языковых моделей. Авторы тестируют ChatGPT на GHOSTS и оцениваем производительность по точным критериям. Они делают этот новый набор данных общедоступным, чтобы помочь сообществу сравнить ChatGPT с (будущими) большими языковыми моделями с точки зрения расширенного математического понимания. Они пришли к выводу, что, вопреки многим положительным сообщениям в СМИ (потенциальный случай предвзятости отбора), математические способности ChatGPT значительно ниже, чем у среднего выпускника магистратуры по математика. Результаты показывают, что ChatGPT часто понимает вопрос, но не может предоставить правильные решения. Следовательно, если ваша цель — использовать его для сдачи университетского экзамена, вам лучше копировать у своего среднего сверстника!
Таким образом, вклад этой статьи состоит из трех частей:
• Во-первых, предоставляется информация для математического использования. Авторы показывают, для каких типов вопросов и в каких областях математики может быть полезен ChatGPT и как его можно интегрировать в рабочий процесс математика.
• Во-вторых, определяются режимы отказа ChatGPT, а также пределы его возможностей. Это может помочь будущим усилиям по разработке Large Language Models (LLM) - Больших языковых моделей, которые лучше работают в математике. Наш анализ похож на карточку математической модели, где суммированы сильные и слабые стороны математики.
• В-третьих, мы предоставляем эталонные тесты для тестирования математических возможностей будущих LLM, чтобы их можно было сравнить с ChatGPT по целому ряду аспектов, касающихся углубленного понимания математики. Это достигается за счет введения новых математических наборов данных на естественном языке. Два из этих эталонных тестов основаны на самых передовых наборах данных, касающихся математических запросов для языковых моделей, которые существуют сегодня. Кроме того, авторы разрабатывают еще четыре набора данных, на которых оценивают производительность ChatGPT. Они публикуют коллекцию этих наборов данных публично на GitHub2 и поощряют участие сообщества, разрешая запросы на вытягивание GitHub, чтобы увеличить наборы данных за пределы их текущих размеров.
Выводы
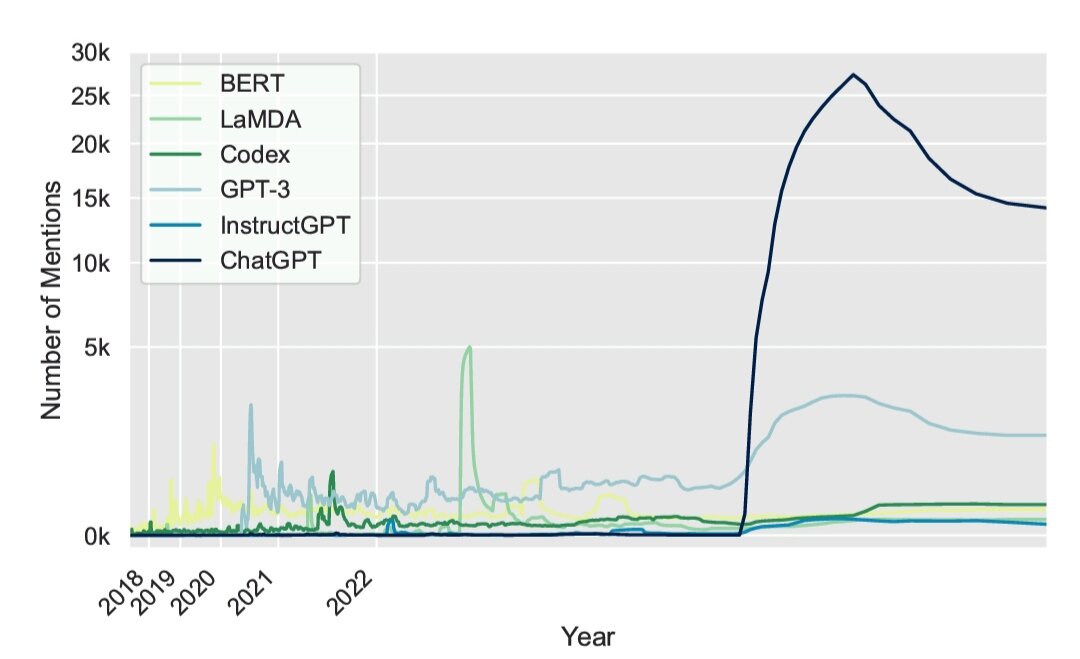
Мы изучили поведение ChatGPT в различных наборах данных, которые проверяют различные аспекты математических навыков. Вопреки шумихе в СМИ, которую вызвал ChatGPT (см. подсчет Twitter на рис. 1),
ChatGPT еще не готов стабильно предоставлять высококачественные доказательства или расчеты. В то же время качество ответа может приятно удивить. В разделе F приложения мы собираем лучшие и худшие результаты для ряда выбранных наборов данных. Лучшие ответы могут быть замечены, чтобы оправдать сенсацию СМИ. Кажется справедливым сказать, что ChatGPT непоследовательно плох в высшей математике: хотя его рейтинги падают из-за математической сложности подсказки, в некоторых случаях он дает проницательные доказательства.
Однако ChatGPT не достигает той же производительности, что и модели, специально обученные для одной единственной задачи. Этим моделям, напротив, не хватает гибкости ChatGPT, универсального инструмента, подходящего для любой области математики.
Тем не менее, способность ChatGPT искать математические объекты с учетом информации о них — это то, где сияет ChatGPT. Он получил самые высокие оценки в файлах поиска обратного определения из поднабора данных Search-Engine-Aspects.
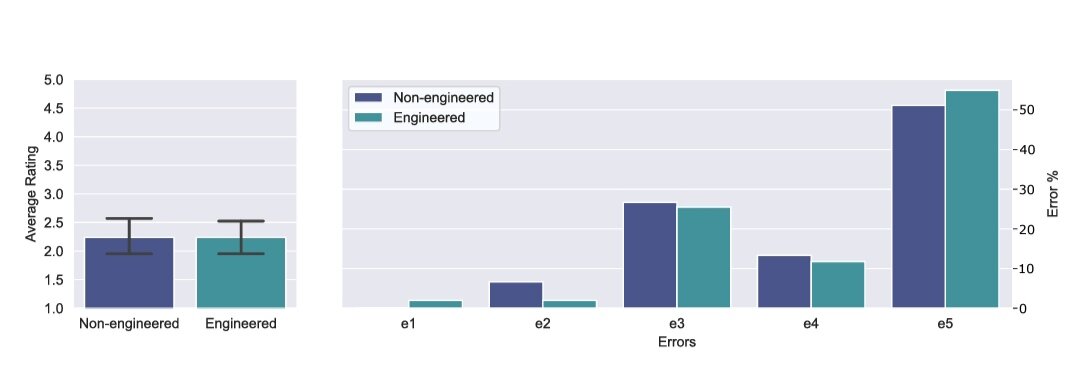
Из-за чрезмерных усилий по аннотированию наш набор данных недостаточно велик, чтобы его можно было использовать для тонкой настройки LLM с целью повышения их математических способностей; хотя мы считаем, что он достаточно всеобъемлющий, чтобы позволить оценить существующие LLM. Мы также отмечаем в качестве рекомендации для будущего дизайна LLM, что включение некоторых возможностей автоматической оценки форм, как это сделано в [16], необходимо для снижения стоимости оценки результатов.
Мы надеемся, что набор данных, который мы публикуем вместе с этой публикацией, побудит других профессиональных математиков внести свой вклад, чтобы установить тщательный эталон для оценки математических способностей LLM.
Мы разрешим запросы на включение в наш репозиторий GitHub и будем поощрять общественное участие. Мы призываем других исследователей изучить наш набор данных за пределами описательной статистики, которую мы вычислили, чтобы получить более глубокое понимание поведения ChatGPT (и других LLM) в математике.