12 месяцев назад
• Вы подписаны
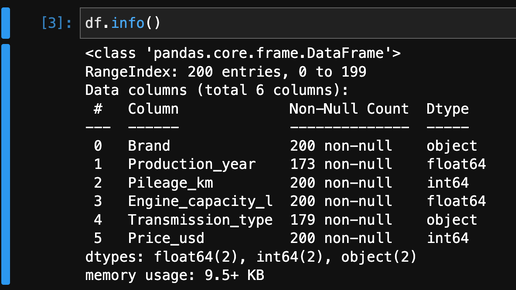
Начнем с небольшого экскурса. Чтобы вы понимали суть добавляю небольшой словарик: В целом, это всё что вам следует знать для понимания текста ниже. Чекаем информацию в данных и можем начинать. Сделаем небольшой вывод: В таблице 309864 объекта и 11 признаков, из которых 6 признаков типа object, в признаках нет пропусков, что уже хорошо, но в дальнейшем нам надо будет поработать над таблицей, чтобы все признаки были количественными. ВАЖНО! Я советую делать манипуляции по кодированию после того как вы разбили данные на на выборки...