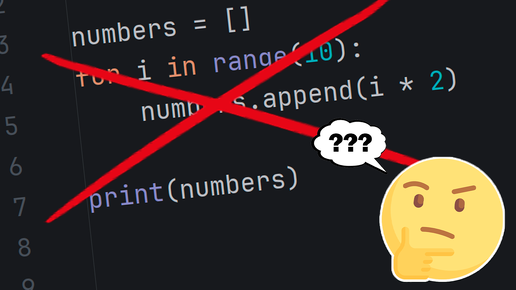
🚀 mapply — это удобная Python-библиотека для ускоренного применения функций к pandas-объектам с использованием параллелизма
Расширяет возможности pandas.apply, позволяя выполнять операции быстрее за счёт многопоточности или мультипроцессинга — особенно полезно при работе с большими датасетами. 📌 Основные особенности: 🔵Параллельное выполнение apply, map, applymap 🔵Простая интеграция с pandas...