5 лет назад
Python. Алгоритмы
133
подписчика
Я о них столько слышал, но ни разу не писал. Пришло время это исправить
Я о них столько слышал, но ни разу не писал. Пришло время это исправить

5 лет назад
Графы и способы их представления
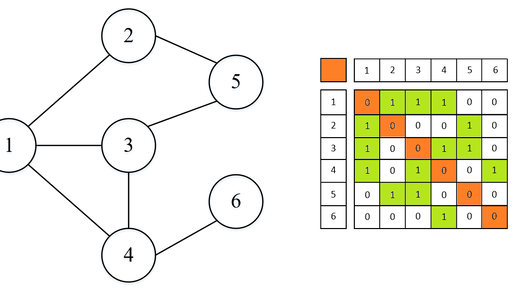
Исходя из определения графа (туть) можно хранить граф в виде списка вершин и списка ребер. Подобная структура позволяет легко проверить наличие вершины и ребра (A in V ), но задача проверки всех соседей становиться довольно сложной, т.к. нам надо перебрать весь список E и сопоставить его с V. Среди различных способов представления графов выделяют два самых популярных: Оба способа подходят для представления как ориентированных, так и неориентированных графов. Матрица смежности Она подходит для простых графов...
5 лет назад
Графы и основные определения
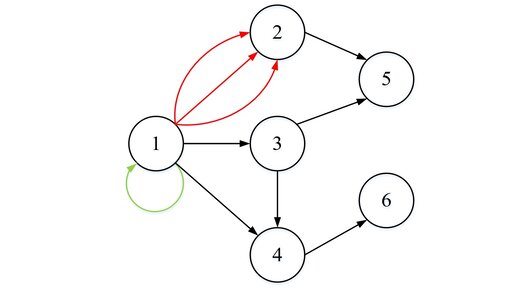
С данной статьи начнем разбирать тему графов и связанных с ними алгоритмов. Итак, Граф – это пара множеств V (англ. vertex) и E (англ. edge) где V – множество вершин E – множество неупорядоченных пар вершин из множества V (множество ребер) Граф может быть ориентированным (часто используют название «орграф»), неориентированным или смешанным. В ориентированном графе, ребра являются направленными (то есть пары в E являются упорядоченными, например, пары (a, b) и (b, a) это два разных ребра)...
6 лет назад
Линейный и Бинарный поиск
Очередной шаг в изучении алгоритмов не мыслим без алгоритмов поиска. И так, перед нами может стоять задача "найти элемент в массиве данных", или "найти положение элемента". Простейшее решение - это пройтись по всему массиву пока мы не обнаружим искомый элемент, а в случае его отсутствия "скажем" что такового не имеется. Такой алгоритм называется Линейным поиском, потому что в худшем случае (когда элемент находится в конце списка размера N) мы совершим N операций сравнения, т.е. время работы алгоритма линейно зависит от размера входного массива - О(n)...

6 лет назад
Структуры данных - Стэк и Очередь
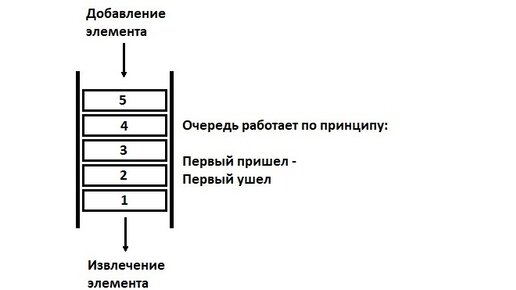
Мы уже упоминали такую структуру данных как стэк(туть). Обычно его описание ведут в сравнении с Очередью. Предлагаю разобраться как они могут быть устроены изнутри. Очередь. Очередь(англ. Queue) – это структура данных основанная на принципе «первый пришел, первый ушел» (англ. FIFO – First In, First Out). Т.е. по принципу очереди в кабинет ко врачу (если не пропускать тех кому "Мне только спросить"). В Python есть свои встроенные реализации (о них в конце статьи), но мы попробуем написать свою. И первое с чего следует начать это определить функциональность нашего класса...
6 лет назад
Сравнение сортировок
На этой статье я хочу закончить разбирать алгоритмы сортировки (на какое-то время) и уже приступить к другим типам алгоритмов. Но перед этим подведем сравнительный итог по изученному. Как оценивают алгоритмы? Во всех статьях мы разбирали работу алгоритмов в худшем случае, но в реальных задачах нам попадаются совершенно разные данные, в том числе полностью или частично отсортированные. Отсюда возникает необходимость оценки для разных случаев: Расчет сложности для случаев отличных от худшего ведется по аналогии с тем как это проводилось в статьях о конкретной сортировке...

