6 лет назад
• Вы подписаны
Об этом рассказал Андрей Белов, руководитель команды подбора персонала Яндекса, на встрече Data&Science. По роду службы он сталкивается с людьми, которые позиционируют себя как аналитики, разработчики, и всё такое. И так оказывается, что если разработчик и аналитик - один и тот же человек, от этого все выигрывают. Традиционная позиция - data scientist, он же аналитик. Другая позиция - МЛ-инженер. Это тот же самый аналитик, но он ещё умеет писать продакшн-код и хорошо шарит в алгоритмах. Для компании...
Об этом рассказал Алексей Рустамов из Loginom Company на встрече Data&Science в Яндексе. Его компания уже лет 20 занимается анализом данных, в частности, кредитным скорингом, на примере которого и строится рассказ. Оказалось, что основная причина низкого проникновения ML - недоверие заказчика к моделям. Но этого можно избежать. Большая часть популярных задач машинного обучения связана с проблемами поиска, рекомендаций, обогащения данных, анализа изображений, перевода, и игр. С другой стороны, в России...
Базовых варианта ценообразования проектов (в частности, в data science) существует три: фиксированная цена, пропорционально затратам, и пропорционально результату. О выборе между ними рассказал Роман Чеботарёв, CTO из Theta Data Solutions, на конференции Data&Science в Яндексе. Разговор ведётся в основном с точки зрения исполнителя (он менее защищён, ибо клиент всегда прав). Сложности обычно приходят при закрытии проекта: клиенту и исполнителю сложно договориться, сколько же заплатить за него. Поэтому договариваться надо заранее...
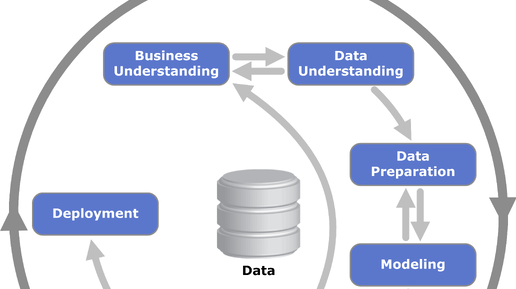
Сегодня на конференции Data&Science в Яндексе выступал Саша Белугин - преподаватель в НИУ ВШЭ и до недавнего времени главный project manager в Yandex Data Factory. Он поделился своим взглядом на особенности проектного управления в задачах, связанных c анализом данных (в первую очередь - в промышленности, ибо последний год YDF занималась именно этим). А я записал его лекцию, и сейчас пересказываю своими словами, иногда вставляя что-то от себя. Таких постов будет несколько, ибо и спикер сегодня был не один...
В предыдущем посте мы познакомили вас с распределением Парето. Сегодня покажем, как оно выглядит в жизни, измерив количество дружеских связей между подписчиками vk-сообщества Матчасти. Для выгрузки данных мы воспользовались кодом на Python (блокнот) и официальным API VK. В сообществе оказалось 700 с чем-то подписчиков, многие из которых находятся друг у друга в друзьях. Соединив их в граф, мы обнаружили в нём "гигантскую компоненту" из 424 человек, которые могут дойти друг до друга по цепочке "рукопожатий" из подписчиков сообщества...