3 года назад
• Вы подписаны
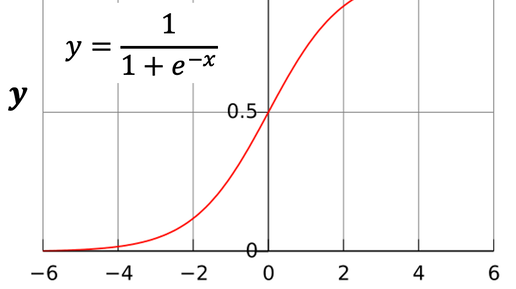
1. Логика логистической регрессии I.3. Преобразование вероятностей в логиты Логит тесно связан с понятиями «вероятность» и «шанс». Вероятность – это объективная мера появления некоторого события, измеряемая от 0 до 1. На практике оценкой вероятности служит относительная частота появления события. Значение вероятности 0 означает невозможность появления события. Значение вероятности 1 означает, что событие непременно произойдет. Шансы – это отношение вероятности того, что событие произойдет, к вероятности того, что событие не произойдет...