ИИ-агенты научились сами себя улучшать без участия инженеров
Исследователи опубликовали работу под названием «Next-Generation Agentic Reinforcement Learning Systems Enable Self-Evolving Agents», где описан механизм, позволяющий корпоративным ИИ-агентам развиваться без постоянного вмешательства разработчиков.
Агенты, которые работают внутри компаний, каждый день генерируют огромный объем полезных данных о своей работе. Проблема в том, что команды обычно улучшают их вручную: инженеры вычитывают логи, правят промпты, дообучают модели и заново разворачивают системы. Такой процесс медленный и не поспевает за темпом накопления данных.
Авторы предлагают трехчастный механизм. Сначала каждый шаг агента записывается в общем формате, пригодном для дальнейшего обучения. Затем данные проходят через прокси-слой, который очищает их, приводит к единому виду, сохраняет и позволяет заново воспроизводить реальные сценарии работы. Отдельный управляющий слой решает, что стоит обновить: память агента, его навыки, промпты, инструменты или веса самой модели.
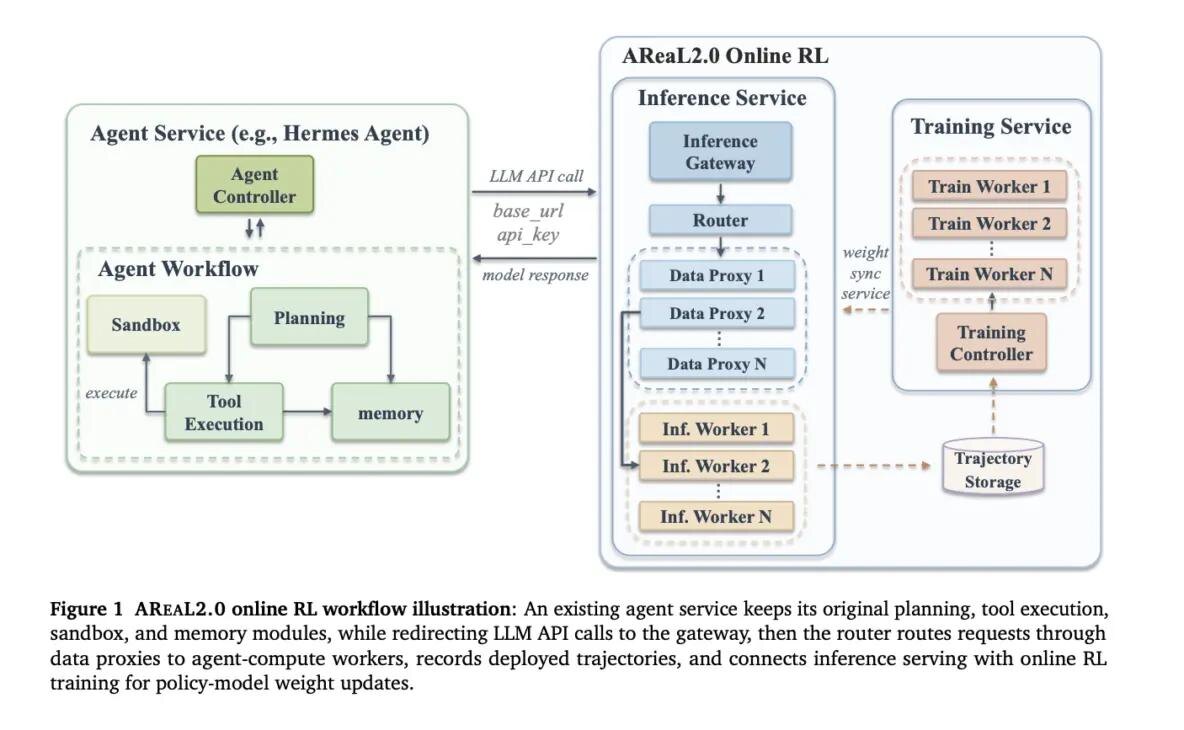
Один из примеров такого подхода уже работает на практике, это система AREAL2.0, в которой обращения агента к языковой модели проходят через онлайн-сервис обучения с подкреплением. Благодаря этому реальные взаимодействия агента сразу становятся материалом для будущих обновлений модели.
Авторы считают, что индустрии нужна именно система для превращения повседневной работы агента в пригодные для обучения данные. Это более важная задача, чем поиск более удачных алгоритмов оптимизации. Будущим агентам потребуются безопасные и воспроизводимые способы обновления памяти, навыков, промптов, инструментов и моделей, чтобы прогресс оставался управляемым.
Полный текст работы: https://arxiv.org/abs/2607.01120v1