В прошлом уроке мы договорились: тестирование — это 3 шага (expected → actual → сравнить и зафиксировать вывод).
Логичные следующие вопросы это:
1) Где и как фиксировать? (чтобы команда реально могла этим пользоваться)
2) Что именно проверять? (потому что “проверить всё” невозможно)

Разберём по порядку.
1) Где и как фиксировать?
Главное правило: если результат тестирования нельзя воспроизвести и использовать — его как будто не существует.
Твоя ценность как тестировщика проявляется не в том, что ты “нашёл баг”, а в том, что команда:
— поняла проблему
— воспроизвела
— починила
— проверила фикс
— и всё это осталось в истории
Что именно фиксирует тестировщик (обычно)
1) Баги — “expected ≠ actual”
2) Тест-кейсы — пошаговые сценарии проверки (чтобы повторять)
3) Чек-листы — список проверок без детальной пошаговости (быстро и практично)
4) Статус/итоги — что проверено, что не проверено, какие риски остались
Иногда ещё: тест-ран/прогон (набор выполненных кейсов в конкретной сборке), тестовые данные, “charter” для исследовательского тестирования (что исследовали и что нашли).
Где это хранится (без привязки к конкретной компании)
Есть два “дома”:
Дом №1: таск-трекер / баг-трекер
Там живут баги и задачи разработки. Примеры: Jira, YouTrack, GitLab Issues, Azure DevOps.
Дом №2: тест-менеджмент
Там живут тест-кейсы, чек-листы, прогоны, отчёты покрытия. Примеры: TestRail, Qase, Zephyr, Xray, Allure TestOps.
Если тест-менеджмента нет, на старте часто используют Confluence/Notion/Google Sheets — это нормально как временное решение. Важно другое: должна быть единая точка правды, а не “у меня в заметках”.
Как связывать всё между собой (это важно)
— Тест-кейс (или чек-лист) должен ссылаться на требование/стори (что проверяем и почему).
— Баг должен ссылаться на задачу/компонент/версию (где сломано и в каком релизе).
— Хорошая практика: баг связывают с тест-кейсом “найден при выполнении TC-123”.
Это даёт трассируемость: “что требовали → чем проверяли → что сломалось”.
2) Как оформлять баг (чтобы его реально починили)
Золотое правило: баг-репорт — это инструкция “как сделать так, чтобы у тебя тоже сломалось” + факты.
Минимальный шаблон баг-репорта:
1) Заголовок
Коротко и по делу: платформа/раздел/суть/условие.
Пример: “Android | Корзина | При оформлении заказа 500 после выбора времени доставки”
2) Окружение
— среда: prod/stage/dev
— версия приложения / номер сборки
— устройство/ОС/браузер
— пользователь/роль (если важно)
3) Предусловия
“Пользователь авторизован”, “в корзине есть товар”, “адрес выбран” и т.д.
4) Шаги воспроизведения
- …
- …
- …
5) Фактический результат (Actual) - собственно суть бага
Что произошло (желательно с точным текстом ошибки/кодом/поведением).
6) Ожидаемый результат (Expected)
Что должно было быть по требованиям/логике/договорённостям.
7) Доказательства (вложения)
— скрин/видео
— логи (клиент/сервер)
— HAR / Network
— запрос/ответ API (Postman/curl)
— id заказа / correlation id / trace id (если есть)
8) Важность (если в команде принято)
Severity — насколько больно пользователю/бизнесу.
Priority — насколько срочно чинить (часто зависит от планов релиза).
Важно: не пиши “ничего не работает”. Пиши наблюдаемый факт: “после нажатия ‘Оформить заказ’ получаем 500, заказ не создаётся”.
3) Как оформлять тест-кейс (чтобы его можно было повторять)
Тест-кейс — это не сочинение. Это повторяемый алгоритм проверки.
Минимальный шаблон тест-кейса:
1) Название/ID
Пример: “TC-Checkout-001: Оформление заказа с доставкой на сегодня”
2) Цель
Что подтверждаем: “заказ создаётся и отображается в истории заказов”.
3) Предусловия
Пользователь авторизован, адрес заполнен, товар доступен и т.п.
4) Тестовые данные
Товар/адрес/сумма/способ оплаты/промокод — конкретно.
5) Шаги
- …
- …
- …
6) Ожидаемый результат
Часто удобно фиксировать expected на ключевых шагах, а не только в конце.
7) Постусловия (опционально)
Например: “создан заказ”, “событие аналитики отправлено”, “запись появилась в БД”.
Что в описании бага, что в описании тест-кейса - некоторые пункты могут отстутствовать. Некоторые наоборот могут быть добавлены (например ссылка на требования или задачу, заинтересованные лица, "метки" (например нашли_сами, нашли_автотесты, нашли_пользователи), эпик в рамках которого задача тестируется). Зависит от договоренностей в команде.
4) Чек-лист vs тест-кейс: что когда
Чек-лист — когда нужно быстро и широко:
— sanity/смоук
— регресс перед релизом
— первичное знакомство с фичой
— “времени мало, но хочется покрыть максимум”
Тест-кейсы — когда нужно стабильно и повторяемо:
— критичные сценарии (оплата, авторизация, оформление заказа)
— тесты выполняют разные люди
— планируется автоматизация (кейсы — отличная база)
Практический подход:
критичные флоу — тест-кейсами, остальное — чек-листами + исследовательское тестирование.
5) И что именно проверять? (тест-дизайн)
“Проверить всё” невозможно. Поэтому тестировщик выбирает проверки умно.
Тест-дизайн — это набор техник, которые помогают выбрать минимальный, но эффективный набор тестов.
С чего начинать (когда нет времени)
1) Критичные пользовательские сценарии
“зашёл → сделал целевое действие → получил результат”
пример: “нашёл товар → оплатил → заказ создался”
2) Самые рискованные места
— новая логика
— сложные условия
— интеграции (платежи, доставки, сторонние API)
— всё, что меняли в этом релизе
3) Ошибки и “края”
— пустые значения
— большие значения
— неверные форматы
— нестабильная сеть/таймауты
— повторные нажатия/дубли запросов
4) Регресс “рядом”
Что могло сломаться вокруг изменения.
Основные техники тест-дизайна (прикладной минимум)
подробнее про тест-дизайн можно прочитать в статье Тест-дизайн: что это, откуда взялся и как работает на практике
1) Классы эквивалентности
Разбиваем данные на группы, внутри которых поведение одинаковое.
Пример: поле “возраст” - от 14 до 17 лет - одно поведение системы, от 18-25 другое, от 26-60 третье и т.д.
2) Граничные значения
Самые частые баги живут на краях.
Пример для предыдущих классов эквивалентности: 13/14/17/18/25/26/60/61.
3) Таблицы решений
Когда много условий “если…, то…”.
Пример: скидка зависит от тип клиента × сумма × промокод × регион.
пример в виде таблички (просто чтобы представлять):
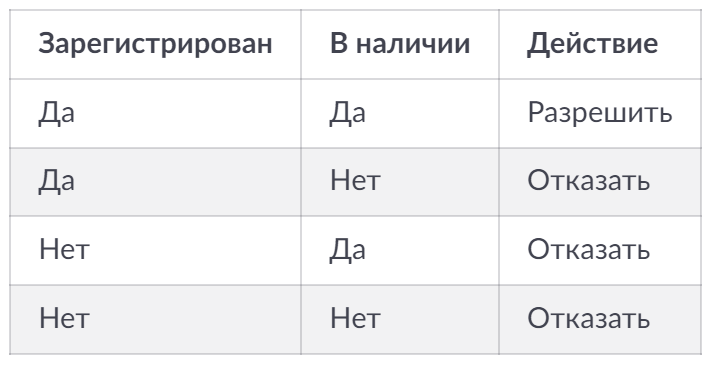
4) Переходы состояний
Когда важна последовательность.
Пример: заказ: создан → оплачен → собран → в доставке → доставлен
Плюс отмены, возвраты, повторная оплата.
5) Попарное тестирование (pairwise)
Когда комбинаций слишком много: браузеры × ОС × способы оплаты × доставки.
Вместо полного перебора покрываем все пары параметров.
6) Исследовательское тестирование
Это не “тыкать куда попало”, а проверка по цели.
Пример цели: “исследовать оформление заказа при нестабильной сети и повторных нажатиях”.
Как быстро выбрать технику под задачу
— если много данных и диапазонов → классы эквивалентности + границы
— если много условий “если/то” → таблица решений
— если важна последовательность → состояния
— если слишком много комбинаций → pairwise + риск-ориентированное отсечение
6) Отдельно: нагрузочное тестирование (тут другой подход)
В нагрузке цель не “найти баг в кнопке”. Цель — понять:
— выдержит ли система нужную нагрузку
— где узкое место
— что будет при деградации
— выполняются ли SLO/SLA (например, p95 по времени ответа)
Что выбирать/проверять в нагрузочном тестировании (по шагам)
Шаг 1. Профиль нагрузки (workload model)
— какие действия составляют 80% трафика
— какие есть пики (вечер, распродажа, зарплата)
— доли сценариев: например 60% просмотр каталога, 30% поиск, 10% оформление
Шаг 2. “Транзакции” (ключевые сценарии)
Обычно берут 3–7 основных:
— логин (если нужен)
— поиск/каталог
— карточка товара
— добавление в корзину
— оформление/оплата
— история заказов
Шаг 3. Метрики успеха
— latency: p50/p95/p99
— throughput: RPS/TPS
— error rate
— ресурсы: CPU/RAM/DB connections/queue lag
— бизнес-метрики: “заказ создан”, “платёж подтверждён”
Шаг 4. Типы нагрузочных тестов
— Load: как работает при ожидаемой нагрузке
— Stress: где ломается
— Spike: резкий скачок
— Soak/Endurance: не течёт ли память/ресурсы на длинной дистанции
— Capacity: сколько максимум выдержим при заданных SLO
Шаг 5. Данные и окружение
Без реалистичных данных нагрузка часто “ненастоящая”.
И если стенд далеко от прода — выводы будут неправильными.
Что почитать/посмотреть по нагрузке
— k6 docs (подход и метрики)
— “Performance Testing Guidance” (любая хорошая методичка про p95/p99, виды тестов)
— принципы SLO/SLA и почему “среднее время ответа” почти всегда обманывает
7) Отдельно: тестирование безопасности (общие принципы и что читать)
В безопасности ты проверяешь не “что система делает”, а “можно ли заставить её сделать то, что нельзя”.
Как выбирать, что тестировать
1) От данных и угроз
— какие данные защищаем (персональные, платежные, токены)
— кто атакующий (обычный пользователь, злоумышленник)
— какие входные точки (формы, API, загрузка файлов, интеграции)
2) От стандартов и чек-листов
Самое полезное на старте:
— OWASP Top 10 (веб)
— OWASP API Security Top 10 (API)
— OWASP ASVS (эталон требований безопасности)
3) Базовые классы проблем, которые тестировщик должен понимать
— авторизация/права: можно ли получить доступ к чужим данным (IDOR), обойти роль
— сессии/токены: хранение, срок жизни, logout
— инъекции: SQL/NoSQL, command injection
— XSS (для веб)
— SSRF (если есть интеграции/загрузка по URL)
— загрузка файлов: опасные типы, path traversal
— rate limiting: brute force, подбор кодов, злоупотребление API
— утечки: логи/ошибки/ответы сервера не должны отдавать секреты и лишние данные
— конфигурация: CORS, HTTPS, security headers
Важный нюанс
Во многих командах QA делает базовый security-check и эскалирует на security/пентест, если:
— продукт обрабатывает деньги/персональные данные
— есть внешнее API
— высокий риск злоупотреблений
Что почитать по безопасности (чтобы быстро прокачаться)
— OWASP Top 10 и OWASP API Security Top 10
— OWASP ASVS (не обязательно весь сразу, но как “шпаргалка требований” — топ)
— PortSwigger Web Security Academy (много практики и объяснений)
— база: HTTP, cookies, OAuth2/OIDC (на уровне понимания потоков)
Домашнее задание
1) Выбери любой сервис (доставка/маркетплейс/банк) и составь чек-лист на 15–25 проверок для одного ключевого сценария (например, “оформление заказа”).
2) Выдели 3 проверки, которые ты оформил бы именно тест-кейсами (пошагово, с данными и expected).
3) Найди любой баг и оформи его по шаблону: заголовок, окружение, шаги, actual/expected, доказательства.
Следите за новым разделом — уроки по тестированию. Он подойдёт тем, кто учится на QA с нуля, и тем, кто уже работает, но хочет систематизировать знания: тест-дизайн, API, автотесты, SQL/данные, CI/CD и практики командной разработки.
Подписывайтесь, добавляйте в закладки в браузере, чтобы ничего не пропустить: QA Helper - справочник тестировщика