У модели 3B параметров, но активируются только 500M. При этом она показывает новые SOTA-результаты на OmniDocBench v1.5 и v1.6. Главная фишка - Reference Sliding Window Attention. Модель держит в фокусе: • исходный документ • недавний контекст • следующие слова А всё лишнее постепенно «забывает», чтобы не раздувать вычисления. За счёт постоянного размера KV Cache и более дешёвого attention Unlimited OCR может распознавать 40+ страниц за один forward pass, не теряя контекст и не замедляясь. GitHub: https://github.com/baidu/Unlimited-OCR Hugging Face: https://huggingface.co/baidu/Unlimited-OCR
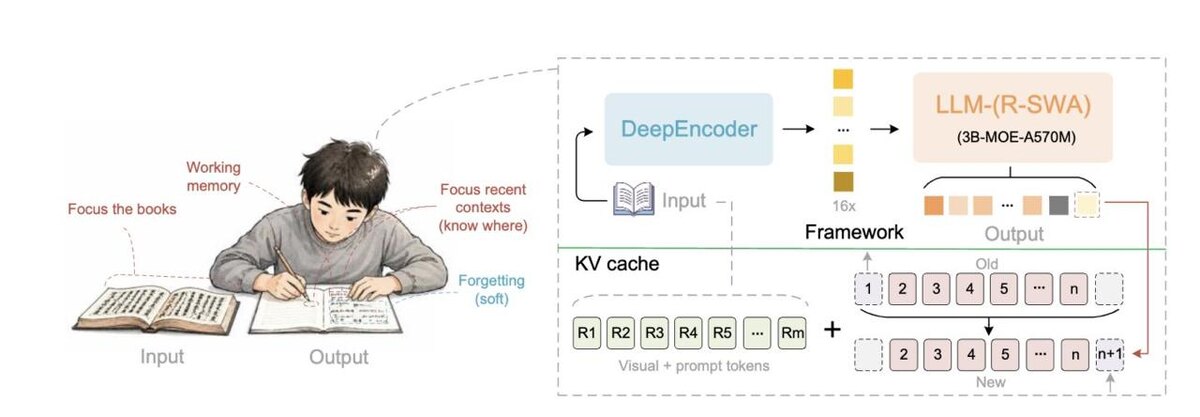
Следом Baidu выпустила Unlimited OCR - модель для распознавания длинных документов за один проход.
У модели 3B параметров, но активируются только 500M. При этом она показывает новые SOTA-результаты на OmniDocBench v1.5 и v1.6.
Главная фишка - Reference Sliding Window Attention.
Модель держит в фокусе:
• исходный документ
• недавний контекст
• следующие слова
А всё лишнее постепенно «забывает», чтобы не раздувать вычисления.
За счёт постоянного размера KV Cache и более дешёвого attention Unlimited OCR может распознавать 40+ страниц за один forward pass, не теряя контекст и не замедляясь.
GitHub: https://github.com/baidu/Unlimited-OCR
Hugging Face: https://huggingface.co/baidu/Unlimited-OCR