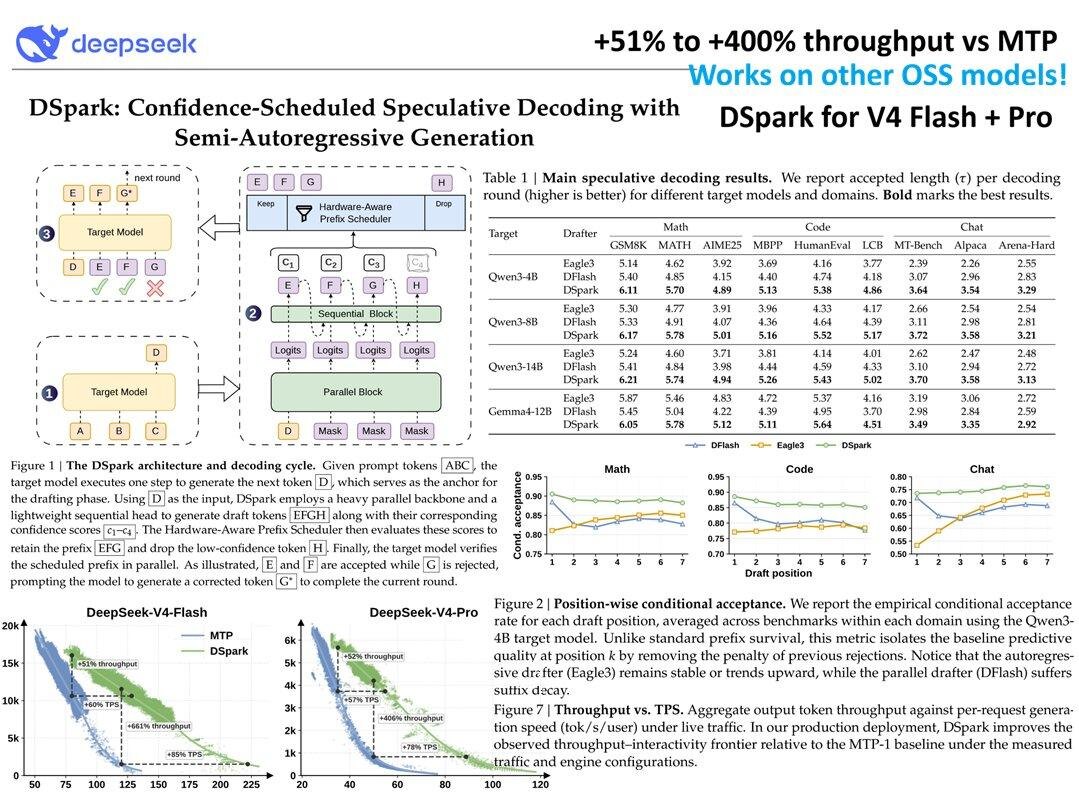
✔️ DeepSeek выложила DSpark - новый метод speculative decoding для V4 Flash и V4 Pro.
Заявленный прирост throughput: от 51% до 400% в зависимости от модели и случаев использования.
Смысл speculative decoding простой: маленькая или более быстрая модель заранее предлагает несколько следующих токенов, а основная модель проверяет их пачкой. Если предсказание совпадает, генерация идёт быстрее, потому что дорогих проходов большой модели становится меньше.
DeepSeek показывает ускорение не только на своих V4 Flash и Pro, но и на других моделях, включая Gemma и Qwen.
Это потенциально довольно полезный inference-подход для разных open-weight моделей.
Для продакшена это важная история.
Если качество ответа остаётся близким, а throughput растёт в разы, можно обслуживать больше запросов на том же железе или снижать стоимость генерации.
GitHub:
https://github.com/deepseek-ai/DeepSpec
Paper:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
HF:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark