
До сих пор речь всегда шла об одном-единственном потоке исполнения: кусок кода, который берёт память, лезет к железу, читает файл. Но на рабочем столе работают оконный менеджер, терминал, часы и десяток фоновых сервисов ядра, вроде бы все разом. А на одном процессорном ядре в каждый момент может работать только один поток. Трюк за этим стар и прост: молниеносное переключение.
Замечание сразу: тут речь о том, как происходит переключение задач (Task Switch). Какая задача будет выполняться следующй, то есть планировщик с его классами приоритетов и виртуальным временем, это тема сама по себе и получит отдельную часть. На этот раз только механика под капотом.
Процесс и поток
Два понятия надо развести.
Процесс, это программа со своим адресным пространством, своим каталогом страниц из статьи про память, своей приватной нижней половиной адресов, своими открытыми файлами, своим именем и своим PID.
Поток, это нить исполнения внутри процесса. Несколько потоков одного процесса делят его адресное пространство, то есть видят одну и ту же память, но у каждого свой стек и, главное, своё состояние процессора. У процесса есть главный поток, и он может обзавестись другими.
Важно понимать, что процессор выполняет не ПРОЦЕСС а поток! Процесс это просто структура данных в памяти с состояниями, параметрами, указателями на потоки. Но там нет ни одного выполняемого кода. Программа выполняется в потоке!
Отсуда вывод - процесс всегда имеет как минимум один поток.
typedef struct Process {
char name[64];
pid_t pid;
AddressSpace address_space; // своё адресное пространство (см. часть про память)
Thread* main_thread;
int thread_count;
fd_entry_t* fd_table; // открытые файлы
// ... сигналы, PID родителя, кольцо kcall ...
} Process;
А теперь поток или нить (кому как нравится)
typedef struct Thread {
Process* process; // какому процессу принадлежит поток
pid_t tid;
void* stack_base; // свой стек
Registers state; // сохранённое состояние процессора
uint32_t cpu_id; // на каком CPU работает
bool has_exited;
// ... поля планировщика: отдельная статья ...
} Thread;
Что такое поток, когда он не исполняется
Ровно один поток исполняется на ядро процессора. А остальные? Они существуют как структура данных, замороженные. Сердце этого, поле Registers state - полный снимок всех регистров процессора, регистров общего назначения, указателя инструкций (где поток только что был), указателя стека и флагов. Пока этот снимок существует, поток в любой момент можно вернуть к жизни, загрузив регистры обратно. Время для него просто остановилось.
Переключение контекста
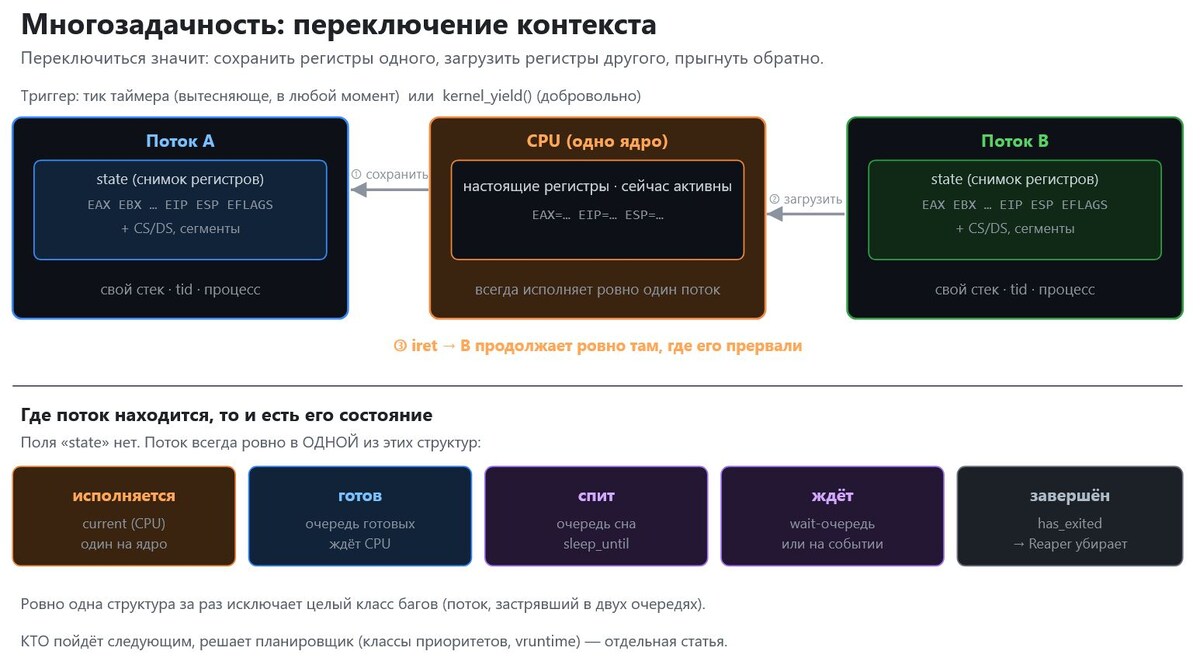
Переключение с потока A на поток B, это сердце многозадачности, и оно на удивление конкретно. Словами:
1. A исполняется, настоящие регистры CPU несут значения A.
2. Приходит триггер. Регистры A сохраняются в снимок state потока A.
3. Планировщик выбирает B (как, это отдельная часть).
4. Снимок state потока B загружается в настоящие регистры.
5. iret прыгает обратно, в середину кода B, ровно туда, где B в последний раз прервали.
В ассемблере последний кусок поразительно дословен, тут слегка сокращённо из кода переключения (esi указывает на state следующего потока):
push [esi + 56] ; EFLAGS ┐
push [esi + 52] ; CS ├ собрать кадр IRET
push [esi + 48] ; EIP ┘
mov ds, [esi + 16] ; восстановить сегментные регистры
mov edi, [esi + 24] ; ... загрузить все регистры общего назначения ...
mov esi, [esi + 28] ; ESI последним, он нужен нам до сюда
iret ; ПРЫГАЕТ в следующий поток
iret, это и есть сам прыжок: он берёт EIP, CS и EFLAGS со стека и возобновляет исполнение там. B не замечает, что его не было.
Два пути в переключение
Переключение задач запускается двумя способами.
Вытесняюще (preemptive) - вызывается прерыванием таймера, неважно, что делает A. Обработчик прерывания и так уже держит все регистры на стеке (это ровно снимок Registers) и вызывает preemptive_switch_task. Поток исполняется ровно столько, сколько ему отвел планировщик, никто не может держать CPU вечно, потому что таймер рано или поздно его прервёт.
Добровольно (cooperative) - поток вызывает kernel_yield() или ложится спать, или ждёт чего-то. Тогда он отдаёт CPU осознанно. kernel_yield сам строит снимок регистров из собственного контекста, после переназначения возвращается ровно к месту вызова и продолжает, как ни в чём не бывало.
Я использую в Триалогия оба варианта. Первый по таймеру, что бы планово переключать задачи. А второй вызывает задача, когда знает, что следующее время она ничего делать не будет. Типичный пример - ожидание с клавиатуры. С точки зрения пользователя, он печатает символы очень быстро, а со стороны програмы это выглядит как - пойду в зимнюю спячку залягу, разбудите по весне. Зачем держать CPU? И отдает его добровольно другому потоку.
Состояния потока
Любопытно, что у меня нет поля, которое говорит "исполняется", "готов" или "спит". Состояние следует из того, в какой структуре данных поток сейчас находится:
- исполняется - он, поток current какого-то CPU.
- готов - он стоит в очереди готовых и ждёт CPU.
- спит - он лежит в очереди сна (sleep queue), с моментом пробуждения sleep_until.
- ждёт/заблокирован - он висит в wait-очереди или на событии (например, потому что ждёт сообщения).
- завершён - выставлен has_exited, он ждёт, пока Thread Reaper его уберёт.
Важное правило за этим: поток всегда ровно в одной из этих структур, никогда в двух. Звучит банально, но исключает целый класс мерзких ошибок, поток, случайно застрявший в двух очередях, планируется дважды и разносит сам себя.
Несколько ядер SMP
На двух процессорных ядрах работает по одному потоку на каждом, то есть по настоящему два одновременно. Для этого у каждого CPU своя очередь готовых и свой поток current, а каждый поток помнит, на каком CPU он работает (cpu_id) и на каких ему вообще позволено (cpu_affinity). Это же ровно то место, где сидит большинство моих проблем со стабильностью, об этом сейчас.
Рождение и смерть - философия
Процесс создаёт create_process, свежее адресное пространство. Поток в том же процессе создаёт create_thread. При этом он получает стек ядра (из прошлой части, аллокатор стеков) и начальный снимок регистров: указатель инструкций показывает на его функцию входа, указатель стека, на верх его стека. Если он создан не приостановленным (sleep = false), он сразу уходит в очередь готовых и ждёт своего первого ломтика процессорного времени.
Когда поток (thread) умирает, он выставляет has_exited, выходит из всех очередей, а Thread Reaper позже убирает его стек и его аллокации в куче, через ровно тот учёт владельца, что встречался в статьях про память.
Чего здесь намеренно нет
Самый интересный вопрос я приберёг, кто пойдёт следующим? Это работа планировщика, и она совсем не тривиальна. Он знает классы приоритетов (реального времени, интерактивный, обычный, простой), он ведёт для каждого потока виртуальное время, чтобы никого не обделить, он состаривает ждущие потоки вверх, чтобы они не голодали, и балансирует нагрузку между ядрами. Это тема сама по себе и получит свою часть.
Честная часть или правда жизни
Переключение контекста, это самый деликатный код во всём ядре. Один неверно сохранённый или загруженный регистр, и поток в следующий раз продолжит с битым состоянием, а падение всплывёт совсем в другом месте и будет выглядеть как что угодно, только не как ошибка переключения. А на двух ядрах (а если их 8?) подстерегает самый мерзкий вариант- оба ядра в один и тот же миг выбирают один и тот же поток (double run), и он разносит собственное состояние, потому что два CPU разом пишут в одни и те же регистры и один и тот же стек. Именно такие гонки (race condition) и есть причина, по которой моя система спокойно работает на одном ядре и пока шатается на двух. Разрешить это, одна из больших открытых строек, о которых я говорил ещё в первой части.
◀ Предыдущая статья Содержание Следующая статья ▶
*Система не стоит на месте, поэтому в дальнейшем тексты могут не совпадать с реальным положением.