
В статье про память я его уже анонсировал: аллокатор, который выдаёт каждому потоку его 256 КБ в области стеков. Вот он. И это славный пример того, что нет одного правильного аллокатора, а требование выбирает инструмент.
Зачем
Каждому потоку, работающему в ядре, нужен свой стек: там лежат локальные переменные, адреса возврата вызовов функций и сохранённые регистры, когда планировщик переключается с одного потока на следующий. Двум потокам нельзя делить стек, иначе они затопчут друг другу данные. Значит, каждому новому потоку ядра нужен свежий стек, и именно их раздаёт этот аллокатор, из области с 0x80000000 по 0x88000000, размером 128 МБ.
Интересно тут не столько как, сколько почему. Поэтому пройдусь по решениям по порядку.
Решение 1: своя область, а не куча (heap)
Стеки можно было бы просто брать из кучи через kmalloc. Я намеренно так не делаю. У стеков своя область адресов, по трём причинам: они все одного размера, им нужна особая защита (об этом чуть ниже), и я хочу, чтобы они лежали предсказуемо. Своя область делает всё это простым и держит их чисто отдельно от множества мелких кусочков кучи из прошлой статьи.
Решение 2: фиксированный размер, и потому битмап
Это самая суть. Все стеки ровно по 256 КБ, без исключений. В статье про кучу размеры были произвольными, и именно поэтому куче нужен был связный список свободных с разрезанием и слиянием. Здесь всё одного размера, и это меняет всё: область распадается на 512 одинаковых слотов (128 МБ / 256 КБ), а свободен ли слот, говорит один-единственный бит.
#define KERNEL_STACK_SIZE_DEFAULT (256 * 1024) // 256 КБ на стек
#define MAX_KERNEL_THREADS 512 // 128 МБ / 256 КБ
static uint32_t stack_bitmap[MAX_KERNEL_THREADS / 32]; // 1 бит = 1 слот (512 бит)
static pid_t stack_owners[MAX_KERNEL_THREADS]; // кому принадлежит слот
Выдать стек теперь означает: найти первый свободный бит, выставить, готово. Адрес считается прямо из номера слота:
for (uint32_t i = 0; i < MAX_KERNEL_THREADS; i++) {
if (!(stack_bitmap[i/32] & (1 << (i%32)))) { // слот свободен?
stack_bitmap[i/32] |= (1 << (i%32)); // занять
stack_owners[i] = tid;
void* stack_base = KERNEL_STACK_REGION_START + i * KERNEL_STACK_SIZE_DEFAULT;
...
}
}
Никакого обхода списка, никакого слияния, никакого заголовка перед каждым блоком. Здесь битмап, это правильный инструмент, именно потому что размер фиксирован, тогда как в куче он был бы неправильным.
А почему 256 КБ? Цепочки вызовов в ядре бывают глубокими: драйвер зовёт файловую систему, та зовёт менеджер памяти, а между делом может вызваться вложенное прерывание и запустить свою цепочку. 256 КБ достаточно щедро, чтобы никакой нормальный путь вызовов это не переполнил, и достаточно мало, чтобы 512 потоков всё же влезли в 128 МБ.
Решение 3: страница-страж против переполнения
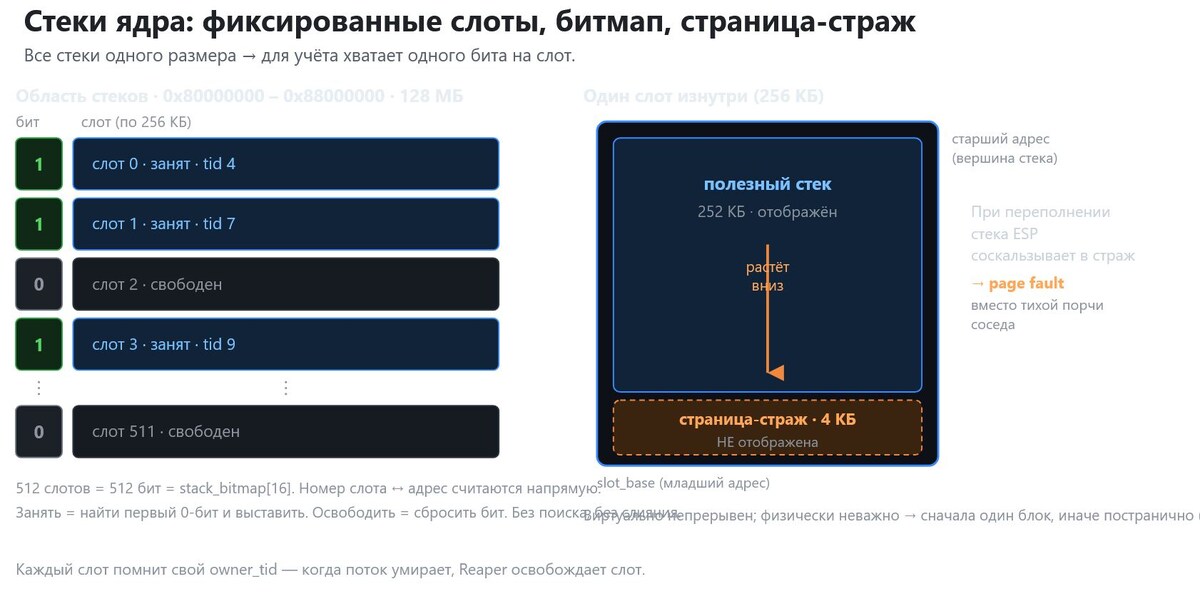
Что будет, если стек всё-таки переполнится, если цепочка вызовов станет глубже этих 256 КБ? Стек растёт вниз, так что он начал бы писать в слот ниже, в стек другого потока. Это худшая из ошибок: тихая порча, которая когда-нибудь вызовет необъяснимое падение совсем в другом месте.
Против этого, страница-страж. Самая нижняя страница (4 КБ) каждого слота намеренно остаётся не отображённой:
#define KSTACK_GUARD_PAGES 1
// полезный стек начинается только ПОСЛЕ страницы стража:
void* mapped_start = stack_base + KSTACK_GUARD_PAGES * PAGE_SIZE;
size_t mapped_pages = (KERNEL_STACK_SIZE_DEFAULT / PAGE_SIZE) - KSTACK_GUARD_PAGES;
Если стек теперь переполнится, указатель стека соскользнёт в эту неотображённую зону, и следующий доступ сразу поднимет page fault, с адресом ошибки ровно в области стража. Тихая порча превращается в ясное, мгновенное падение ровно в нужном месте. Цена 4 КБ на стек, полезными остаются 252 из 256 КБ. Дёшево.
Решение 4: виртуально непрерывно, физически неважно
Стек должен быть непрерывным блоком в виртуальном адресном пространстве, иначе глубокую цепочку вызовов разорвало бы прямо в прыжке. А вот физически за ним он непрерывным быть не обязан, процессору при доступе всё равно, страничная память всё равно собирает страницы вместе. Этим я пользуюсь двухступенчатой стратегией:
// ступень 1 (быстро): один непрерывный физический блок
phyaddr paddr = alloc_phys_pages(mapped_pages);
if (paddr != -1 && map_pages(kernel_page_dir, mapped_start, paddr, mapped_pages, ...) >= MAP_OK)
mapped_ok = true;
// ступень 2 (запасная): постранично, если цельного блока больше нет
if (!mapped_ok) {
for (size_t done = 0; done < mapped_pages; done++) {
phyaddr p1 = alloc_phys_pages(1); // хватит одной страницы
void* va = mapped_start + done * PAGE_SIZE;
map_pages(kernel_page_dir, va, p1, 1, ...);
}
}
Эту вторую ступень я добавил не ради изящества, а из-за одной из самых упрямых ошибок, что у меня были. Раньше был только быстрый путь, тот один непрерывный блок. Физический аллокатор из статьи про память, это first-fit, и он отдаёт только цельные блоки. На двух CPU параллельные аллокации фрагментировали список свободных при каждой загрузке чуть по-разному, и иногда цельного блока в 252 КБ больше не было, хотя в сумме памяти хватало. Тогда alloc_kernel_stack падал, поток так и не создавался, загрузочный сервис не поднимался, и система просто висла, вообще без сообщения о падении. Постраничный запасной путь это устранил: одна свободная страница находится почти всегда.
Решение 5: каждый слот знает своего хозяина
Как и у кучи (heap), каждый занятый слот записывает в stack_owners[] идентификатор потока (thread id). Когда поток умирает, Thread Reaper проходит по битмапу и освобождает все слоты этого потока. Освобождение при этом, это точная противоположность занятию: посчитать из адреса номер слота, сбросить бит, вернуть отображённые страницы.
bool free_kernel_stack(void* stack_base) {
uint32_t slot = ((uint32_t)stack_base - KERNEL_STACK_REGION_START) / KERNEL_STACK_SIZE_DEFAULT;
stack_bitmap[slot/32] &= ~(1 << (slot%32)); // освободить слот
// вернуть отображённые страницы по одной (страж никогда не был отображён)
...
}
Честная часть
512 потоков, это жёсткий потолок, 128 МБ делить на 256 КБ, больше слотов нет. Пока я ни разу даже близко не подходил, но это число, которое надо держать в голове.
А та ошибка с фрагментацией осталась для меня поучительной: код не был неправильным, он работал месяцами. Он просто был недостаточно устойчив к ситуации, которая возникла лишь тогда, когда два CPU одновременно потянули физическую память. Именно такие ошибки, которые не "неправильны", а недостаточно устойчивы к случаю, о котором никто не подумал, и есть настоящая причина, по которой я пишу эту серию. Найти их, это и есть работа, а не набор текста.
◀ Предыдущая статья Содержание Следующая статья ▶
*Система не стоит на месте, поэтому в дальнейшем тексты могут не совпадать с реальным положением.