⚡️ Liquid AI выпустила две retrieval-модели на 350M параметров
Вышли LFM2.5-Embedding-350M и LFM2.5-ColBERT-350M. Это первые двунаправленные модели в семействе LFM, сделанные на базе LFM2.5-350M-Base.
Главный фокус: быстрый мультиязычный поиск для RAG, FAQ, каталогов, саппорта и баз знаний. Поддерживаются 11 языков, включая арабский, японский, корейский и европейские языки.
Архитектурно Liquid взяли causal decoder и превратили его в bidirectional encoder: убрали causal mask, включили full attention и сделали короткие свёртки не-причинными. Теперь каждый токен видит контекст с двух сторон, что важно для retrieval.
Разница между моделями:
• LFM2.5-Embedding-350M даёт один dense vector на документ. Индекс компактный, поиск быстрый, хранение дешёвое.
• LFM2.5-ColBERT-350M хранит вектор на каждый токен и использует MaxSim late interaction. Качество выше, особенно на кросс-язычном поиске, но индекс тяжелее.
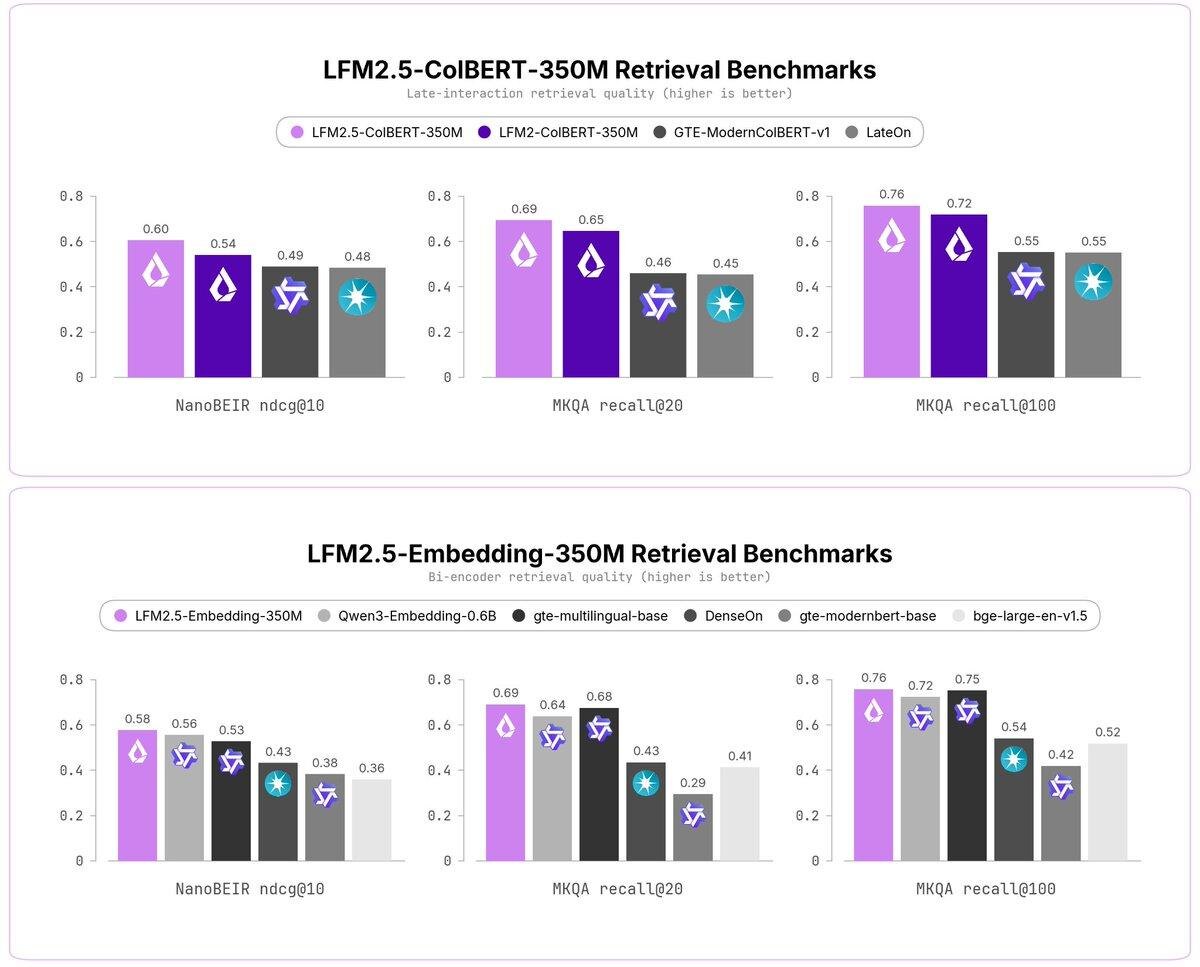
По NanoBEIR Multilingual:
- ColBERT: 0.605 NDCG@10
- Embedding: 0.577
- Qwen3-Embedding-0.6B: 0.556
- gte-multilingual-base: 0.528
На MKQA-11 обе LFM-модели дают около 0.69 Recall@20.
На H100 embedding запроса около 1.5 мс p50, ColBERT query + MaxSim около 2.5 мс p50. Есть GGUF под llama.cpp, на MacBook M4 Max около 7-8 мс p50.
Релиз для тех, кому нужен дешёвый мультиязычный retrieval без тяжёлых embedding-моделей.
https://www.liquid.ai/blog/lfm2-5-retrievers