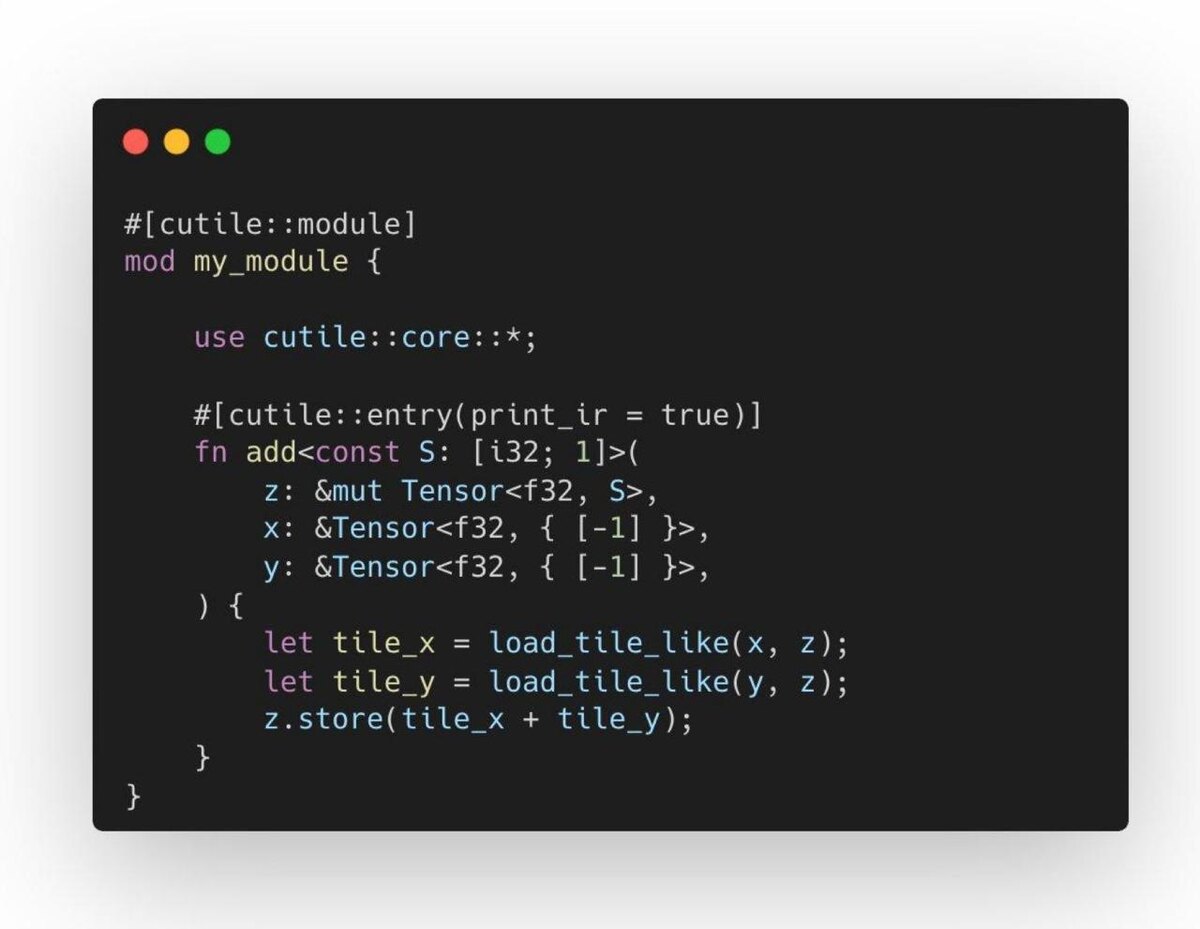
Исследователи NVIDIA перенесли модель владения Rust в GPU-kernels.
Paper: “Fearless Concurrency on the GPU”. В нём представлен cuTile Rust.
Проблема была в том, что при написании кастомных GPU-ядер на Rust разработчикам фактически приходилось выходить за пределы гарантий безопасности Rust.
cuTile Rust пытается это исправить:
* mutable outputs разбиваются на непересекающиеся части
* запуск kernels сохраняет правила ownership от host до device
* при необходимости остаются локальные opt-out механизмы для низкоуровневого контроля
Производительность тоже держится на уровне:
* 7 TB/s для element-wise операций на NVIDIA B200
* 2 PFlop/s для GEMM, это 96% от cuBLAS
* результат сопоставим с cuTile Python в пределах погрешности измерений
Авторы также собрали Grout, inference engine поверх cuTile Rust, и прогнали реальные модели:
* 171 tokens/s для Qwen3-4B на RTX 5090
* 82 tokens/s для Qwen3-32B на B200
* конкурентный уровень рядом с vLLM и SGLang
Итог - безопасный и идиоматичный Rust почти на полной CUDA-производительности.
Для Rust в ML-инфраструктуре это большой шаг.
http://arxiv.org/abs/2606.15991
#Rust #RustLang #GPU #CUDA #MachineLearning #SystemsProgramming #NVIDIA