chess-fancy.py:
#!/usr/bin/env python3
"""
Шахматы для двух игроков с предупреждениями за неверные ходы.
После 3 предупреждений игрок проигрывает.
"""
import chess
piece_emojis = {
'r': '♜', 'n': '♞', 'b': '♝', 'q': '♛', 'k': '♚', 'p': '♟',
'R': '♖', 'N': '♘', 'B': '♗', 'Q': '♕', 'K': '♔', 'P': '♙',
'.': '·'
}
def print_board(board):
print(" a b c d e f g h")
print(" +---+---+---+---+---+---+---+---+")
for rank in range(7, -1, -1):
print(f"{rank+1} ", end="")
for file in range(8):
square = chess.square(file, rank)
piece = board.piece_at(square)
emoji = piece_emojis.get(piece.symbol() if piece else '.', '?')
print(f"| {emoji} ", end="")
print("|")
if rank > 0:
print(" +---+---+---+---+---+---+---+---+")
print(" +---+---+---+---+---+---+---+---+")
print(" a b c d e f g h")
def game_over_by_warnings(side, move_counter):
print(f"\n{side} набрал 3 предупреждения и проигрывает на {move_counter}-м полуходе!")
print("Игра окончена.")
# --- Инициализация ---
board = chess.Board()
warnings_white = 0
move_counter = 0
warnings_black = 0
# --- Основной цикл ---
while not board.is_game_over():
print("\033[2J\033[H", end="")
print_board(board)
if board.turn == chess.WHITE:
player = "Белые ♔"
warnings = warnings_white
else:
player = "Чёрные ♚"
warnings = warnings_black
while True:
move_str = input("Очередь: " + player + "\nпринимается формат e2e4, e4, Nf3, Bc4, exd5, Nxe4, O-O, O-O-O, ed и e8=Q\nВаш ход: ").strip()
move = None
# Расширенная обработка коротких взятий (например, "de")
if len(move_str) == 2 and move_str[0] in 'abcdefgh' and move_str[1] in 'abcdefgh':
from_file = move_str[0]
to_file = move_str[1]
possible = []
for move in board.legal_moves:
piece = board.piece_at(move.from_square)
if piece and piece.piece_type == chess.PAWN and piece.color == board.turn:
if chess.square_file(move.from_square) == ord(from_file)-97:
# Взятие? Должна быть фигура на to_square
if board.is_capture(move) and chess.square_file(move.to_square) == ord(to_file)-97:
possible.append(move)
if len(possible) == 1:
move_str = board.san(possible[0])
print(f"(понято как {move_str})")
else:
# Неоднозначно или нет взятий – не трогаем
pass
# Пытаемся распознать ход
try:
# Сначала UCI (e2e4, g1f3)
move = board.parse_uci(move_str)
except ValueError:
try:
# Потом SAN (Bc4, Nxd5, exd6, O-O и т.д.)
move = board.parse_san(move_str)
except ValueError:
pass # Ничего не нашли
if move is not None and move in board.legal_moves:
board.push(move)
move_counter += 1
break # успешный ход
else:
# Неверный ход → предупреждение
if board.turn == chess.WHITE:
warnings_white += 1
print(f"Невозможный ход!\nБелые: предупреждение {warnings_white}/3")
if warnings_white >= 3:
game_over_by_warnings("Белые", move_counter)
exit()
else:
warnings_black += 1
print(f"Невозможный ход!\nЧёрные: предупреждение {warnings_black}/3")
if warnings_black >= 3:
game_over_by_warnings("Чёрные", move_counter)
exit()
# продолжаем цикл ввода для того же игрока
# --- Завершение игры (мат/пат) ---
print("\033[2J\033[H", end="")
print_board(board)
print(f"\nИгра завершена на {move_counter}-м полуходе.")
print("Результат:", board.result())
Новые (по отношению к старой статье) данные:
Имя;minB;maxB;minA;maxA;Think;Search;LTM;minSize;maxSize;minScore;maxScore
Kimi K2.6 Instant+LTM;1000;1000;32;32;0;0;1;4656.61;4656.61;-0.066667;-0.066667
Kimi K2.6 Think+LTM;1000;1000;32;32;1;0;1;4656.61;4656.61;-0.02439024;-0.02439024
GLM-4.7 + Think;358;358;32;32;1;0;0;1667.55;10672.32;-0.047619;-0.047619
Итого 38 тестов, вот что они показывают:
Если судить только по одному признаку, то 66,5-76% реализационного интеллекта зависит от размера модели (количество общих параметров * бит на параметр) в ГБ:
x = ln(1 + maxSize)
minScore = -1.5270872262 + 0.9615519112 * x - 0.2105747073 * x² + 0.0188101930 * x³ - 0.0005892584 * x⁴
R² = 0.7590595154
maxScore = -1.5187139131 + 0.9075085755 * x - 0.1926623349 * x² + 0.0168181378 * x³ - 0.0005163143 * x⁴
R² = 0.6659722621
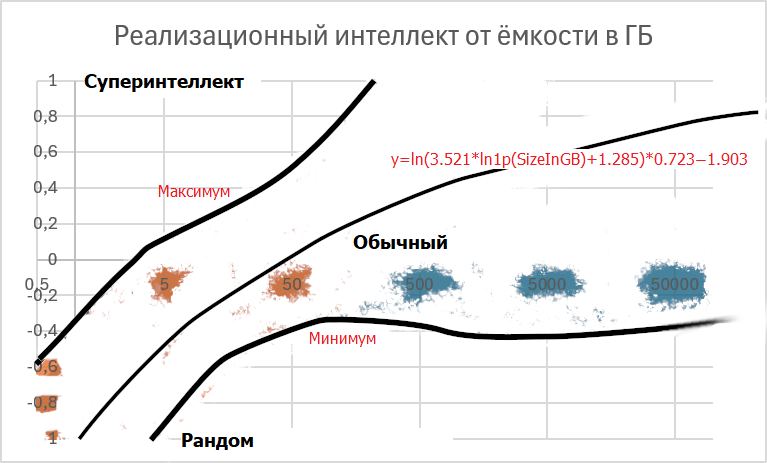
Если судить по 9 признакам, то картина складывается немного по-другому (однако точность возрастает лишь на 2%):
minScore ≈ -0.1257691150+ 0.3216643400 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)- 0.0394462646 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^2- 0.3718566633 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^3+ 0.1428113885 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^4- 0.5513121756 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)- 0.5668543243 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)^2+ 0.2512107162 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)^4- 0.0756616780 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)+ 0.0110319163 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)^2+ 0.0463389737 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)^3+ 0.7982613656 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)- 0.3204111200 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)^2+ 0.0377841363 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)^3+ 0.4125547832 * ((ln(1+minB) - 3.7409274824) / 2.5767481299)^2+ 0.4485652694 * ((minSize/maxSize - 0.5634623845) / 0.4389223913)^4- 0.5251136928 * ((ln(1+maxB) - 3.9863114976) / 2.7133427222)^2+ 0.0310356024 * Think- 0.0954832126 * Search- 0.0288742676 * LTM
R² для minScore: 0.7732443252
maxScore ≈ -0.0857050007+ 0.5252705287 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)- 0.1162263906 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^2- 0.3593480364 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^3+ 0.1309775876 * ((Think*ln(1+maxSize) - 2.1294356658) / 3.2416345001)^4- 0.5648488103 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)- 0.3658202400 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)^2+ 0.2376948687 * ((ln(1+maxSize) - 4.7642272404) / 3.4289083875)^4- 0.1924784341 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)- 0.0264417497 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)^2+ 0.0891972881 * ((Think*ln(1+maxA) - 1.0886489445) / 1.3949989630)^3+ 0.8047050283 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)- 0.3143959491 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)^2+ 0.0200193380 * ((ln(1+minSize) - 3.6292621998) / 2.5827968075)^3+ 0.4374195139 * ((ln(1+minB) - 3.7409274824) / 2.5767481299)^2+ 0.4719930807 * ((minSize/maxSize - 0.5634623845) / 0.4389223913)^4- 0.6540230970 * ((ln(1+maxB) - 3.9863114976) / 2.7133427222)^2- 0.0677452922 * Think- 0.0877221867 * Search+ 0.0478814352 * LTM
R² для maxScore: 0.6870392687
, где LTM э 0/1 (память между чатами), Search э 0/1 (поиск в интернете), Think э 0..1 (возможность долго подумать перед ответом)
Рассуждение+размер: бонус от -0,3 до 0,2
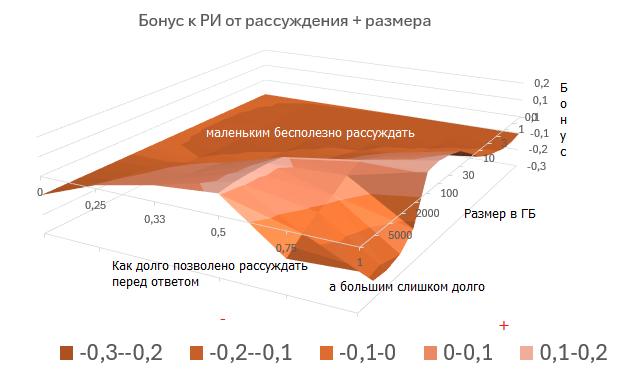
Максимальная оценка размера: от -1 до +0,6. Достаточно интересно - простое масштабирование не даст автоматически интеллекта, нужно умное хранение.
Рассуждение + количество активных параметров: от -0,5 до +1,6 (+3,5 если бы были плотные модели на 1Т)
Минимальная оценка размера: от -1,6 до +0,7. Тут масштабирование работает, но с убывающей отдачей до ассимптотической
Минимальная оценка общего количества параметров (для закрытых): от 0 до +2
Закрытость (проприетарность): от 0 до +1,2 (полностью открытые получают +0,4, полностью секретные +1,2)
Максимальная оценка количества параметров (для закрытых): от -2 до 0 - не параметрами едиными!
Также рассуждение в среднем дополнительно даёт +0,03
Поиск в интернете при решении конкретной задачи: -0,1 (сбивают общие советы, не применимые в этой ситуации)
Долговременная память между чатами и лишний системный промпт: -0,03
Общее количество параметров (для открытых): всего от -0,25 до +0,05 (см. Qwen3.7-Plus с 35B, которая обыграла ВСЕХ)
Если верить этим цифрам, то получается осталось только нафайнтюнить обучение на решение реальных задач в реальных средах, вместо простых вопрос-ответ: