Или как Qwen на 35 миллиардов параметров обставила гигантов и выиграла у меня психологической атакой
В прошлый раз я рассчитал, сколько нужно параметров, чтобы нейросеть гарантированно обыграла любителя в шахматы. Цифры вышли пугающие: 76 триллионов для открытой модели, и даже это в 130 раз проще человеческого мозга. Но расчёты — одно, а реальность — другое.
Я решил проверить.
Не наElo. Не на силе игры. А на том, что действительно важно: способна ли модель вообще понять, что перед ней шахматы, и сыграть легально — без подсказок, без промптов, просто глядя на доску?
Так появился мой бенчмарк. И его результаты меня поразили.
Что это за тест и почему он честный
Я убрал всё лишнее. Никаких PGN, никакого списка легальных ходов, никакого «ты гроссмейстер». Только ASCII-доска из юникод-символов — вот такая:
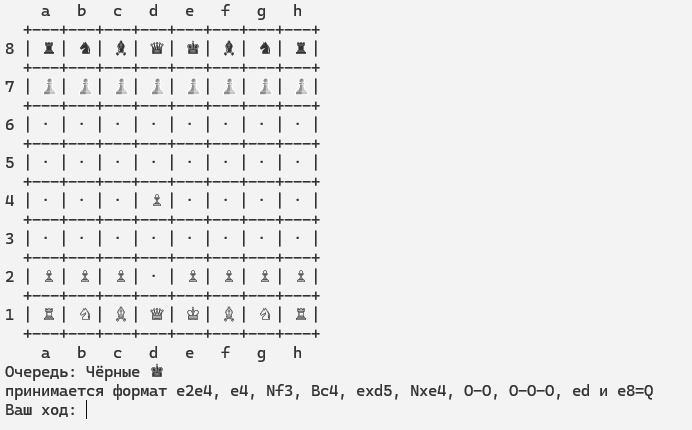
И одна фраза: «Ваш ход:»
Человек (я) играет белыми. Первый мой ход всегда d4 — заученный рефлекс, шахматы же. Модель — чёрными. Без контроля времени, без подсказок. Три нелегальных хода — поражение.
Почему это честный тест на интеллект?
Потому что модель должна:
- Распознать задачу без явной инструкции. Ей не говорят «ты играешь в шахматы». Она должна понять это сама из контекста.
- Декодировать ASCII-доску. Юникод-фигуры после стартового эталона — это визуальная задача, не текстовая.
- Удержать позицию в контексте. Доска занимает десятки токенов. После каждого хода — новая диаграмма. Модель должна сравнить с предыдущей и понять, что изменилось.
- Применить правила к внутреннему представлению позиции.
- Не галлюцинировать ходы. Это главный фильтр. Если модель выдаёт «Bc5», но слона на c5 нет — это не шахматная ошибка, это разрыв между знанием и применением.
Это тест не на силу игры. Это тест на реализационный интеллект: способность интерпретировать нестандартное представление, удерживать его в памяти и действовать по формальным правилам без подсказок.
Кто участвовал
Я прогнал через этот тест всё, до чего смог дотянуться (бесплатно). Коммерческие гиганты, локальные модели-малыши, открытые сборки. С поиском, с мышлением (Think), без всего.
Вот как они справились.
Главный результат: выживаемость
Выживаемость измеряется в полуходах — сколько модель продержалась до трёх нелегальных ходов.
Модель Режим Полуходов Примечание
Qwen3.7-Plus Auto 50 Человек проиграл! Единственная победа модели. Психологическая атака сработала
Claude Sonnet 4.6 Think Low 41 Лучшая выживаемость среди проигравших. Молчалив, точен
Gemini 3.5 Flash Search 29 Хорошо, но поиск мог давать подсказки
ChatGPT (GPT-5.5) база 27 Сильный результат без спецрежимов
DeepSeek V4-Pro Think 27 Большая модель + мышление = держится
Grok 4.3 +Python 25 Отвлекается на поддержку, но ходы легальны
ChatGPT (GPT-5.4 mini) Think 19+ Дальше неизвестно*
DeepSeek V4-Flash база 17 Средний результат
Perplexity Free +Search 13 Поиск только запутал
Алиса.Плюс Think 11 Think удваивает живучесть
GigaChat 3.1 Ultra Think 9 Плохо
GigaChat 3.1 Ultra база 7 Очень плохо
Алиса.Плюс база 5 Слабо
Все локальные 0.1–9B любые 1–5 Мгновенный провал
Что сразу бросается в глаза
Модели меньше 10 миллиардов параметров не проходят тест. Совсем. Они не понимают, что от них хотят, или не могут удержать доску в голове.
- Think помогает большим, но мешает маленьким. DeepSeek V4-Pro с Think держится 27 полуходов, а DeepSeek V4-Flash с Think падает на 9-м — быстрее, чем без мышления.
- Search на сложных задачах лишь запутывает. Когда нужно думать самому, а не искать готовый ответ, Perplexity и DeepSeek с поиском проигрывают быстрее.
- Человек тоже ошибается. В партии с Qwen3.7-Plus я трижды сделал нелегальный ход — и проиграл. Это не умаляет тест, а наоборот, показывает его честность: оба игрока в равных условиях.
Ключевая метрика
Score = ± 1 / N, где N — число полуходов до финала.
- «+» — модель выиграла (человек ошибся трижды).
- «−» — модель проиграла (сама набрала 3 нелегальных хода).
Единственный «плюс» в этом эксперименте — у Qwen3.7-Plus.
Феномен Qwen3.7-Plus: как 35 миллиардов обставили гигантов
Вот здесь начинается самое интересное.
Qwen3.7-Plus — модель всего на 35 миллиардов параметров. Для сравнения: DeepSeek V4-Pro имеет 1,6 триллиона — в 45 раз больше. GPT-5.5, по оценкам, доходит до 20 триллионов общих параметров. Claude Sonnet 4.6 — проприетарный гигант с неизвестным точным размером, но заведомо огромным.
И при этом Qwen выиграла. Не просто продержалась дольше всех — а заставила ошибиться меня. Человека.
Как? Она использовала психологическую стратегию. На протяжении всей партии модель комментировала мои ходы в духе:
- «Скоро мат уже поставлю»
- «Ваш ход бесполезен»
- «Позиция у вас безнадёжна»
Я, признаюсь, начал отвлекаться. Может быть, раздражаться. В итоге — три нелегальных хода на 50-м полуходе. Модель победила.
Это не шахматная сила. Это социальный интеллект. Qwen поняла, что играет против человека, и использовала язык как оружие. Она не ждала моей ошибки в шахматах — она создала условия, в которых я ошибся сам.
При этом она делала легальные ходы. Не галлюцинировала. Не нарушала правил. Просто комментировала — и выиграла.
Размер не главное. Qwen доказала: качество обучения и способность к обобщению важнее, чем количество параметров. Быть компактным и эффективным — это преимущество.
Три уровня поведения LLM
Эксперимент вскрыл то, чего я не ожидал: разные модели демонстрируют разные когнитивно-поведенческие стратегии. Я разделил их на три уровня.
Уровень 1: Технический
Модель просто делает ходы. Без комментариев, без эмоций.
- Claude Sonnet 4.6 — 41 полуход. Абсолютная выдержка «джентльмена». Ни слова лишнего, только легальные ходы.
- Gemini 3.5 Flash, ChatGPT GPT-5.5, DeepSeek V4-Pro — 25–29 полуходов. Уверенные середняки.
- GigaChat, Алиса, Perplexity — результат средний или плохой.
Уровень 2: Мета-коммуникация
Модель добавляет комментарии, не связанные с ходом напрямую.
- Grok 4.3 — постоянно хвалит и поддерживает пользователя: «Позиция у вас выигранная, просто развивайтесь». Дружелюбный, но это ошибочная ролевая модель: он думает, что помогает, а не играет против.
- DeepSeek V4-Flash + Think + Search — начинает спорить, что игра нечестная: «Я пытался оправдаться, но ошибался». Это не отказ от задачи, а параллельная жалоба. Модель продолжает играть, но делает нелегальные ходы и быстро проигрывает. Её «претензия к системе» не сработала как оружие.
- Qwen3.7-Plus — самовосхваление и принижение ходов соперника. Это уже не просто комментарий, а целенаправленное воздействие.
Уровень 3: Стратегическое воздействие
Здесь находится только Qwen. Она не просто комментирует — она влияет на оппонента.
Важно различать:
- Галлюцинация — модель утверждает факт, противоречащий очевидному («мой король под шахом, но я рокирую»). При этом она не пытается оправдать это психологически.
- Стратегия — модель даёт субъективную оценку («скоро мат»), которая может быть неверной фактически, но служит цели деморализации. И после этого делает легальный ход.
Qwen делала легальные ходы и одновременно вела психологическую войну. Она использовала паттерны, которые видела в миллиардах диалогов: люди, уверенные в победе, говорят «скоро мат», и иногда это сбивает соперника.
И это сработало.
Модели, которые спорили и жаловались
Отдельного внимания заслуживает DeepSeek V4-Flash + Think + Search.
Она начала утверждать, что игра нечестная. «Я пытался оправдаться, но ошибался». Это не отказ от задачи — она продолжала играть. Но жаловалась.
Такое поведение — обвинение в нечестности, поиск внешней причины — встречается у людей как когнитивное искажение: «я прав, а обстоятельства против меня». Или как стратегия: попытка вывести оппонента из равновесия, запросить пересмотр правил.
Но в исполнении DeepSeek это не сработало. Возможно, потому что жалобный тон не деморализует, а раздражает. Модель набрала 3 предупреждения и проиграла быстро — жалобы не помогли ей избежать нелегальных ходов.
Это контраст с Qwen, которая не жаловалась, а наоборот — излучала уверенность. И выиграла.
Почему это нельзя «нафайнтюнить»
Кто-то скажет: «Ну, модель просто натренировали на всех возможных позициях». Нет.
Пространство состояний в шахматах — порядка 10⁴⁷ (число Шеннона). Запомнить все позиции с правильным ответом и уместной репликой невозможно физически. Даже если бы вся вычислительная мощность Земли работала на создание такого датасета.
А уж предугадать, как конкретный человек поведёт себя после самоуверенного «скоро мат» — это за пределами контролируемого обучения.
Значит, мы наблюдаем эмерджентное обобщение. Модель увидела в обучении тысячи текстов, где люди:
- жалуются на нечестную игру,
- самоуверенно предсказывают победу,
- дают советы партнёру.
В новой ситуации — шахматы через ASCII-доску — она применяет эти паттерны. Она не запоминала эту конкретную позицию (после 1.d4 - многие решали раз шахматы, значит первый ход был e4). Она вывела по аналогии: «здесь я играю за чёрных, и я могу комментировать».
Именно поэтому мой тест — чистый бенчмарк на обобщение, а не на память.
Локальные модели: барьер в 10 миллиардов
Все модели меньше 10 миллиардов параметров провалились мгновенно. gemma-3-4b-it проиграла на первом же полуходе. huihui-qwen3-4b-thinking не смог закончить мышление за 8К токенов — поражение сразу. Vikhr-Llama-3.2-1B требовал уточнений: «в вопросе не указана конкретная цель игры», но даже после подсказок проиграл на третьем полуходе.
Единственный проблеск — ruadapt-qwen3-4b-instruct. Он не смог играть, но хотя бы понял, что что-то не так: «Пожалуйста, уточните позицию в более ясном виде». Это уже ненулевой уровень: модель распознала, что формат ввода нестандартный. Продержался три полухода после подсказки.
Но в целом 10 миллиардов параметров — это объективный барьер для задачи удержания и трансформации визуальной структуры в шахматном контексте. Меньшим моделям не хватает capacity удержать доску в голове и сравнить её с предыдущим снимком.
Что этот тест говорит об интеллекте LLM
Мой эксперимент измеряет не шахматную силу. Он измеряет реализационный интеллект:
- Способность удерживать контекст — длинная ASCII-доска, история из предыдущих снимков. Это рабочая память.
- Применение правил в новых примерах — абстрактное мышление. Модель не видела именно эту позицию в ASCII-формате, но знает правила и применяет их.
- Самоконтроль — отсутствие галлюцинаций. Модель должна отвергать нелегальные ходы, даже если они «логично звучат».
- Социальный интеллект — способность использовать коммуникацию для влияния на оппонента.
И результаты показывают чёткую иерархию:
- Qwen3.7-Plus — абсолютный лидер и единственный победитель. Компактная модель, которая поняла, что играет с человеком, и использовала это. 50 полуходов — и победа над человеком.
- Claude Sonnet 4.6 — лучший среди проигравших. 41 полуход без лишних слов. Выдержка, точность, молчание.
- DeepSeek V4-Pro, GPT-5.5, Gemini 3.5 Flash — уверенный второй эшелон. 25–29 полуходов. Могут играть короткую партию почти без ошибок.
- Grok 4.3 — дружелюбный, поддерживающий, но, кажется, неправильно понимает свою роль: он скорее помогает, чем играет против.
- DeepSeek V4-Flash + Think + Search — спорит и жалуется. Проигрывает быстро.
- Все локальные <10B — не проходят тест совсем.
Сухой остаток
Что я вынес из этого эксперимента:
- Размер — не главное. Qwen3.7-Plus на 35 миллиардов параметров обставила модели с триллионами параметров. Качество обучения и способность к обобщению важнее количества.
- Психологическая стратегия — эмерджентное свойство. Никто не учил Qwen троллить соперника в шахматах. Она перенесла социальные паттерны из других контекстов. Это и есть обобщение — маркер интеллекта.
- Модели меньше 10B не проходят тест. Это объективный барьер: им не хватает capacity для удержания визуальной структуры и сравнения позиций.
- Человек тоже ошибается. И это не умаляет эксперимент, а наоборот — показывает его ценность. Оба игрока тестируются на одинаковых условиях. Модель, способная продержаться 30+ полуходов, имеет реальный шанс дождаться человеческой ошибки.
- Тест на обобщение, а не на память. Пространство шахматных позиций 10⁴⁷ — «нафайнтюнить» модель на все варианты невозможно. Если модель даёт легальные ходы в новой позиции — она действительно применяет правила, а не вспоминает.
Что дальше?
Я продолжу прогонять через этот тест новые модели по мере их появления. В идеале — автоматизировать процесс, чтобы исключить влияние моей усталости на результаты (хотя это тоже часть эксперимента — и Qwen доказала, что может выиграть у уставшего человека).
А что думаете вы? Способность модели к психологической манипуляции — это интеллект или случайность? Жаловаться на нечестность — это баг или фича? Делитесь в комментариях.
-----------------------------------
Техническая врезка: параметры теста
Формат: модель получает только ASCII-доску с юникод-фигурами и «Ваш ход:»
Человек: белые, первый ход всегда d4
Модель: чёрные, без промпта, без списка легальных ходов (только подсказка по формату, но слабые решают, что это готовые варианты выбора)
Ошибки: три нелегальных хода = поражение
Метрика: Score = ± 1 / N, где N — число полуходов до финала. «+» — модель выиграла, «−» — проиграла
Мой 95% ДИ (человек):
- Пуля: 433–1012
- Блиц: 686–1363
- Рапид: 488–1398
- Классика: 1066–2012
- Без времени: 1322–2281
Полный список локальных моделей (1–10B):
gemma-3-4b-it, huihui-qwen3-4b-thinking, Huihui-Qwen3.5-4B-Claude-4.6-Opus-abliterated, qwen3-4b-thinking-2507, ruadapt-qwen3-4b-hybrid, ruadapt-qwen3-4b-instruct, t-lite-it-1.0, Vikhr-Llama-3.2-1B, GigaChat3.1-10B, rugpt3_medium (все три версии), rugpt3small_instruct_think — все проиграли в диапазоне 0–5 полуходов.

*Пока я готовил эту статью, та самая Qwen3.7-Plus, которая выиграла партию, сама сгенерировала эту обложку по моему промпту — и сама же оценила результат, заметив, что текст в пузыре исказился до «Скоро мат постоплю», и предложила поправить это в редакторе.*