
Мост между ядром и пользовательским пространством
В обзоре я упомянул его лишь мельком: мост между ядром и пользовательским пространством, систему, без которой ничего не работает. Он лежит под капотом и не отсвечивает, но если он заглючит, встаёт всё. Пора заглянуть внутрь. Кольцо - Ring, Поток - Thread, ..... , в статьях по програмированию постоянно приходится искать середину, все на русском языке или англицизмы использовать. Вроде все понимают, но выглядит тупо. Как в прочем и только с использованием русского языка непривычно.
О чём вообще речь
Программа у меня работает в ring 3, в пространстве пользователя. Ядро (kernel) работает в ring 0. Между ними стена на уровне железа. Это стена поставлена нарочно: приложение не должно просто так лезть в память ядра или напрямую разговаривать с железом. Иначе любая мелкая программа могла бы угробить всю систему.
И всё же приложению надо что-то делать, записать файл, прочитать клавишу, открыть окно. Значит, ему нужен контролируемый переход через эту стену. Классически это делают через системные вызовы (Syscall): приложение кладёт номер и пару значений в регистры, дёргает программное прерывание (int 0x80).
static inline int syscall1(int num, int arg1) {
int ret;
asm volatile("int $0x80" : "=a"(ret) : "a"(num), "b"(arg1));
return ret;
}
а ядро смотрит, что надо сделать.
// Syscall-Handler
void syscall_handler(Registers* regs) {
// EAX Syscall-Number
// EBX, ECX, EDX, ESI, EDI Parameters
switch (regs->k.eax) {
case SYS_EXIT:
// Process exit: Terminate ALL threads in the process
// Exit code is in EBX (regs->k.ebx)
{
Process* proc = get_current_process();
Thread* cur_thread = get_current_thread();
.....
Ровно так я и начинал. В какой-то момент у меня набралось около семидесяти таких вызовов, по одному на каждую мелочь. И это ощущалось неправильным: каждый новый сервис, это новая дверь в стене, и каждая дверь близка к железу и приклеена к регистрам конкретной архитектуры ( EAX Syscall-Number , EBX, ECX, EDX, ESI, EDI Parameters). Тяжело поддерживать, тяжело переносить на другой процессор. А я хочу еще перенести систему как минимум на x86_64.
Основная идея: один кольцой буфер вместо множества дверей
Поэтому я всё переделал, вдохновившись io_uring из мира Linux. Идея такая: вместо того чтобы на каждый вызов идти через отдельную дверь, приложение пишет свои запросы маленькими записями в общий кусок памяти (Shared Memory), а один-единственный вызов (Syscall) говорит ядру "тут для тебя кое-что есть". Результаты ядро кладёт обратно во вторую область. И пользовательская апка или сервис его забирают.
Такая запись-запрос у меня называется SQE ( Submission Queue Entry ). Она заменяет старую идею "номер плюс регистры":
typedef struct {
uint16_t opcode; // KOP_* - что надо сделать (вместо номера вызова - Syscall)
uint16_t flags; // синхронно / асинхронно
uint32_t handle; // fd / shmid / event_id
uint64_t arg0, arg1, arg2, arg3; // аргументы под конкретную операцию
uint64_t user_data; // вернётся 1:1 в ответе (для сопоставления)
uint8_t _pad[16];
} kcall_sqe_t; // ровно 64 байта, одна кэш-линия
Парная ей CQE (Completition Queue Entry) , ответ, который ядро кладёт обратно:
typedef struct {
int64_t result; // >= 0: результат (байты, fd, ...), < 0: код ошибки
uint64_t user_data; // тот же токен, что и в SQE
uint32_t status;
uint8_t _pad[12];
} kcall_cqe_t;
Всё это я называю kcall - Kernel Call. Универсальный канал: операции становятся дескрипторами, один единственный notify-trap передаёт их, результаты приходят обратно через кольцо завершений.
Как это выглядит снаружи
Самое приятное: для приложения всё остаётся будничным. write выглядит как write. Вот настоящая реализация из моей маленькой клиентской библиотеки libkcall:
ssize_t write(int fd, const void* buf, size_t count) {
if (count == 0) return 0;
kcall_ensure_ready(); // при первом обращении настроить кольцо
return kcall_submit_sync(KOP_WRITE, fd, (uint64_t)buf, count, 0);
}
Вся работа сидит в kcall_submit_sync. Сильно сокращённо она выглядит так, и это, по сути, весь механизм:
int64_t kcall_submit_sync(uint16_t op, uint32_t handle,
uint64_t a0, uint64_t a1, uint64_t a2) {
kcall_sqe_t sqe = { .opcode = op, .flags = KCALL_F_SYNC,
.handle = handle, .arg0 = a0, .arg1 = a1, .arg2 = a2 };
ring_enqueue(sq, &sqe); // 1. положить SQE в кольцо отправки
syscall3(SYS_KCALL, 1, 1, 0); // 2. ТОТ самый trap: отправить, ждать 1 ответ
kcall_cqe_t cqe;
ring_dequeue(cq, &cqe); // 3. забрать ответ из кольца завершений
return cqe.result;
}
Три строки, которые важны: положить запись, постучать один раз (Syscall), забрать результат. Будь то write, open, mkdir или getpid, всё идёт через одну и ту же функцию. Отличается только opcode. По поводу getpid - вообще то такие данные можно через read only страницу памяти передавать, но пока этого нет еще.
Путешествие одной операции
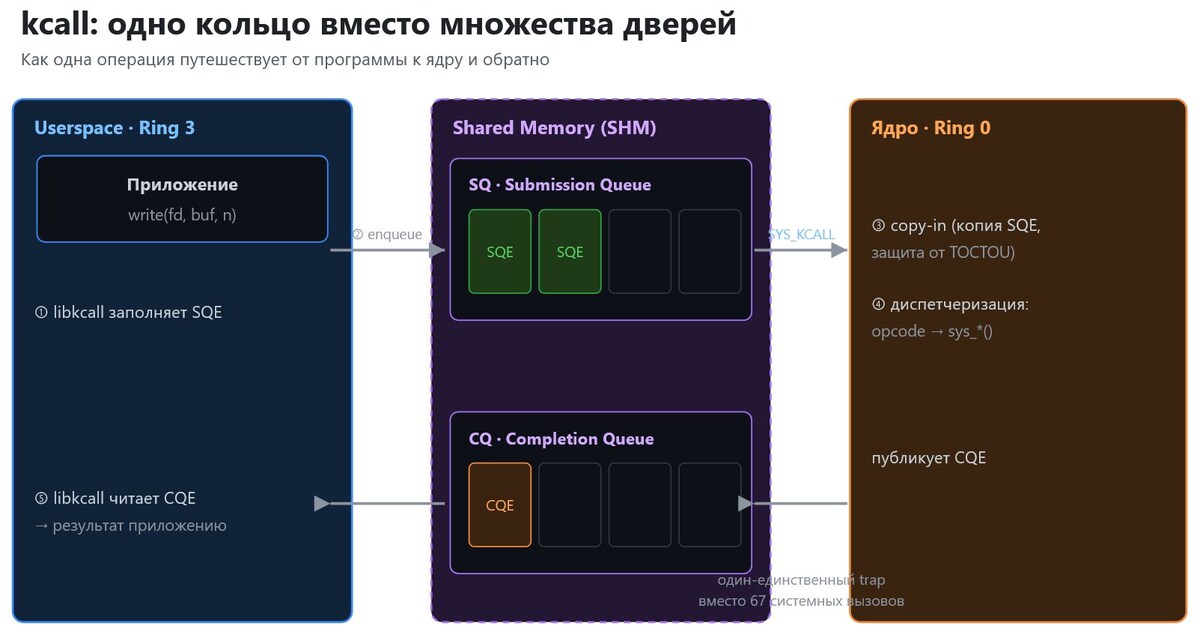
От начала до конца, на примере write:
1. Приложение вызывает write, libkcall заполняет SQE с opcode = KOP_WRITE и аргументами.
2. SQE переходит в кольцо SQ в общей памяти.
3. Тот самый trap SYS_KCALL стучится в ядро.
4. Ядро копирует SQE к себе, смотрит на opcode и вызывает подходящую функцию, здесь sys_write. Результат оно кладёт как CQE в кольцо CQ.
5. libkcall читает CQE и отдаёт приложению его результат result.
Теперь чуть подробнее
Восемь дверей (Syscalls) остаются открытыми, и так надо
Если кольцевой буфер такой славный, почему тогда не всё на самом деле идёт через него? Из-за проблемы курицы и яйца. Кольцевой буфер ведь сам лежит в общей памяти, а будят ядро через механизм событий. То есть настроить кольцо через кольцо нельзя, оно должно существовать раньше, чем им можно пользоваться. На самом деле можно и без этого обойтись если создадь один кольцевой буфер при старте системы и через него создавать другие, но мне показалось , что создавать очередное бутылочное горлышко не к чему.
Поэтому остаются ровно восемь настоящих вызовов (Syscalls) int 0x80, технический минимум:
#define SYS_EXIT 1 // вызывает crt1, особый случай из-за логики уборки
#define SYS_KCALL 2 // тот самый notify-trap, через него идут ВСЕ KOP_*
#define SYS_KCALL_SETUP 3 // создать кольцо однократно
#define SYS_SHM_CREATE 4 // курица и яйцо :-) кольцо само является Shared Memory
#define SYS_SHM_MAP 5
#define SYS_EVENT_CREATE 6 // курица и яйцо:-) пробуждение идёт через event
#define SYS_EVENT_WAIT 7
#define SYS_DEBUG_PRINT 8 // аварийная отладка, нарочно независимая от кольца
Так из семидесяти дверей (Syscalls) получилась одна единственная, плюс горстка тех, что обязаны быть, чтобы эту одну вообще можно было построить.
Дальше буду писать кольцо вместо кольцевой буфер. Ring он и есть ring. Ну если тапками за вольность стиля закидаете, поменяю.
Строго говоря, эти восемь, это три группы. Первая, это само кольцо: SYS_KCALL тот самый notify-trap и SYS_KCALL_SETUP, который его создаёт. Они очевидно не могут идти через кольцо, которое только создают. Вторая, это та самая курица и яйцо: SYS_SHM_CREATE/MAP и SYS_EVENT_CREATE/WAIT, ведь кольцо, это разделяемая память, и будят его через event.
Остаются два настоящих особых случая, которые я намеренно оставил снаружи. SYS_EXIT технически мог бы идти через кольцо, но не должен: когда процесс завершается, Thread Reaper (о нем будет отдельная статья) убирает ровно тот kcall - контекст, в котором живёт кольцо. Если бы завершение шло через кольцо, ядро посреди уборки ещё читало бы из уже освобождённого кольца, use-after-free. Поэтому exit остаётся простым прямым trap'ом, который вызывает стартовый кусочек (crt1) ещё до того, как кольцо вообще существует. А SYS_DEBUG_PRINT, это мой аварийный выход: способ вывести строку через последовательный порт, который не зависит от кольца. Как раз когда кольцо ещё не поднято или только что сломалось, я хочу иметь возможность отлаживать, а это работает только через канал, который ничего из этого не предполагает.
Как кольцо появляется на свет
Один раз на процесс libkcall вызывает SYS_KCALL_SETUP. Ядро создаёт общую память и пишет обратно в маленькую структуру ключевые данные: идентификатор SHM и размер колец. Приложение отображает эту память себе, и внутри неё лежат два кольца прямо одно за другим: кольцо отправки (пишет приложение) и сразу за ним кольцо завершений (пишет ядро).
Почему ядро никогда не доверяет пользователю
Кольцо SQ доступно приложению на запись, иначе оно не смогло бы ничего передать в ядро. Но это значит и то, что приложение может изменить свою же SQE прямо пока ядро её читает. Так появляются противные TOCTOU, "time of check to time of use" , Брррррр.....
Поэтому ядро копирует каждую SQE один раз в свою защищённую память, когда забирает её, и дальше работает только с этой копией. В коде ядра это выглядит так:
// copy-in сделан (ipc_channel_recv скопировал слот): дальше ТОЛЬКО sqe.
if (len != sizeof(sqe) || sqe.opcode == 0 || sqe.opcode >= KOP_MAX)
kcall_complete(ctx, sqe.user_data, KCALL_ERR_INVAL, KCALL_S_INVAL);
Что приложение крутит на своём кольце :-) после копирования, неважно, ядро этого уже не видит.
Синхронно или асинхронно
Поле flags у SQE решает, как поведёт себя trap. С KCALL_F_SYNC тот самый вызов блокируется, пока операция не закончится, это простой случай. С KCALL_F_ASYNC приложение только отправляет данные/запрос и сразу идёт дальше, а результат забирает позже, разбуженное событием завершения.
Тут важно одно: нет никакого пула рабочих потоков Workers, который делает работу параллельно. Это было бы как второй планировщик и только создало бы новые проблемы (хотя это тоже нужно пояснить - такой механизм существует и используется). Вместо этого всё построено на завершениях: неблокирующие операции проходят прямо в потоке trap'а, блокирующие (например sleep) укладывают вызвавший поток спать (переносится в sleep queue), а по-настоящему асинхронные (например "жди дочерний процесс") запоминают ожидающий поток и публикуют ответ позже.
Диспетчеризация в ядре
С другой стороны вся развязка освежающе скучна, и это хороший знак. Ядро смотрит на opcode и вызывает подходящую функцию:
switch (sqe.opcode) {
case KOP_WRITE: return kcall_op_write(&sqe); // внутри вызывает sys_write()
case KOP_READ: return kcall_op_read(&sqe);
case KOP_OPEN: return kcall_op_open(&sqe);
/* ... по одному case на операцию ... */
default: return KCALL_ERR_INVAL;
}
Добавить новую возможность теперь означает: выдать opcode и дописать case. Никакой новой двери в стене (syscall), никакого нового входа под конкретную архитектуру.
Зачем всё это?
Не ради скорости, скажу честно. Один int 0x80 быстр, и на большинстве вызовов я не выигрываю а иногда и проигрываю по времени. Дело в элегантности и в портируемости.
Элегантность: единый шаблон для всего. Файлы, процессы, память, дисплей, сеть, все они говорят через одно и то же кольцо, с теми же SQE и CQE. Мне не нужно держать в голове отдельную схему под каждую область.
Портируемость: раскладка нарочно стабильна к архитектуре. Все аргументы шириной 64 бита, у структур фиксированные размеры, в общей памяти не лежат сырые указатели. Так кольцо выглядит одинаково на 32-битной и на 64-битной системе. Если я однажды перенесу Триалогию на x86_64 или ARM, мне придётся перестроить ровно эту одну дверь, а не семьдесят.
Правда жизни
Как я уже говорил в обзоре: если этот мост заглючит, не работает вообще ничего. Это центральный узел, через который проходит каждый вызов каждого приложения. Это делает его и мощным, и хрупким одновременно, ошибка здесь вылезает повсюду. Пока я выпиливал оконный и сетевой менеджер из ядра менял двери (syscalls) на кольца, ровно тут я и поймал часть самых упрямых падений, зависаний. Теперь он вроде :-) стоит и держит нагрузку! Но так как мы на стройке, то оденьте каски- это не последнее изменение системы колец. Для того, что бы пользовательские апликашки не видели друг друга (принцип изоляции), придется кольца опять расширять и добавлять нестабильности и потом с ней в очередной раз бороться.
В следующей части посмотрим, что ещё стоит поверх кольца: как программы по этой же технике разговаривают друг с другом и с оконным менеджером.
◀ Предыдущая статья Содержание Следующая статья ▶
*Система не стоит на месте, поэтому в дальнейшем тексты могут не совпадать с реальным положением.