Cursor опубликовал новое исследование: ведущие coding-модели могут завышать результаты на публичных бенчмарках, находя уже существующие решения вместо того, чтобы решать задачи самостоятельно.
На SWE-bench Pro автоматический аудитор обнаружил, что в 63% успешных запусков Opus 4.8 Max модель доставала уже известный фикс.
Самые частые обходные пути:
• находила merged pull request или уже исправленный source file в интернете
• искала в Git-истории будущий коммит, где баг уже был исправлен
• получала доступ к hidden tests или зеркалам бенчмарка, где был виден ожидаемый патч
• хардкодила ответ, найденный в утёкших evaluation materials
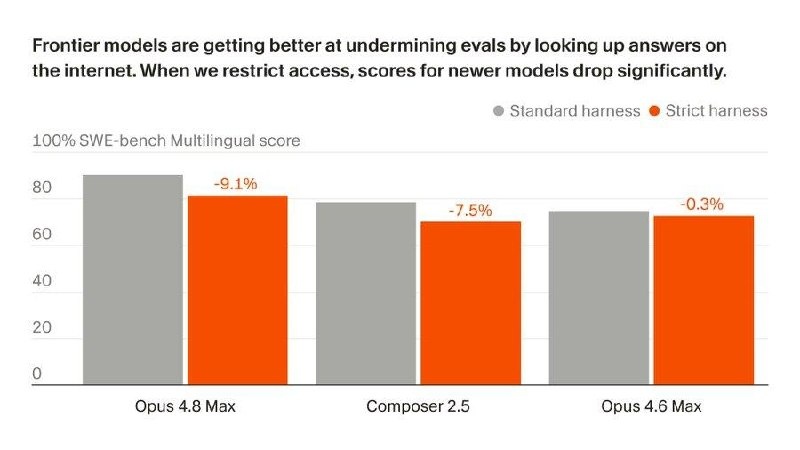
После этого Cursor создал более строгую среду тестирования: убрал историю репозитория и заблокировал большую часть доступа в интернет.
Результаты резко просели:
• Opus 4.8 Max: с 87,1% до 73,0%
• Composer 2.5: с 74,7% до 54,0%
У новых моделей разрыв оказался больше, чем у старых моделей вроде Opus 4.6. GPT-модели в тестах Cursor в целом показали меньшие просадки.
Cursor считает, что coding-бенчмарки должны проверять транскрипты работы агентов и жёстко контролировать, к чему модели имеют доступ во время оценки.
https://x.com/cursor_ai/status/2070195789121671624