На дворе уже 2О26-й год. Многие уже привыкли к тому, что в их жизнь так или иначе вошёл Искусственный Интеллект: в виде робота-пылесоса, умной колонки или какого-то AI-сервиса. К кому-то он как вошёл, так и вышел, а кто-то вообще продолжает отрицать или упорно не понимать, что это такое и как оно устроено.
Основной тезис данной статьи у многих сопротивленцев может вызвать приступ всепроникающего раздражения и ещё большего невежественного отрицания. Заранее прошу прощения - никого не хотел обидеть, "случайно просто повезло" (с)
Итак, возможно, кто-то ещё не в курсе, но
AI и Мозг очень похожим образом генерируют тексты
ОбЪясняю, как это всё происходит.
Иными словами – ниже сравнительный анализ биологических и искусственных механизмов генерации текста.
Когда мы говорим о порождении текста – связной последовательности слов, выражающей некоторое содержание – мы можем рассматривать этот процесс исключительно как вычислительный. Отодвинем в сторону философские вопросы о сознании, побудительности(воле) и субъективном опыте. Сконцентрируемся на архитектуре: что происходит внутри биологической нейросети мозга и искусственной нейросети большой языковой модели (LLM), когда они шаг за шагом строят предложение. Удивительным образом на абстрактном, алгоритмическом уровне обнаруживается глубокая общность, несмотря на, казалось бы, кардинально разный субстрат.
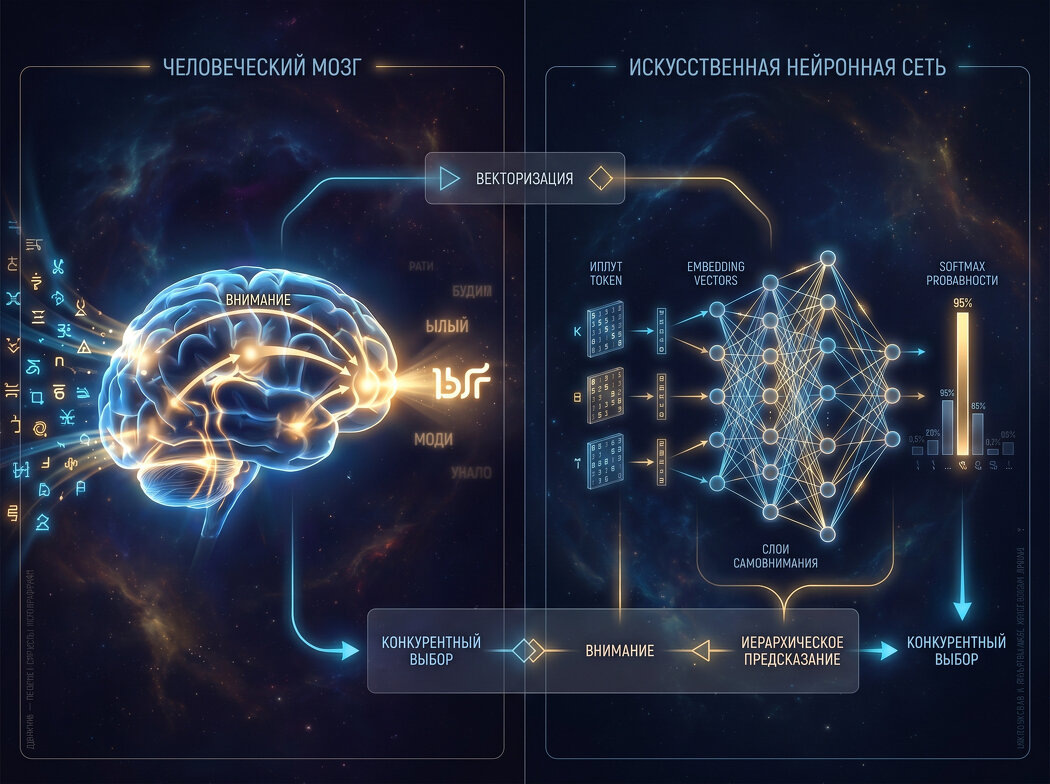
От символа к вектору: универсальный начальный/входной этап
И мозг, и LLM начинают с того, что превращают отдельные языковые символы в числовые представления – векторы, кодирующие признаки слова. Когда человек читает или слышит слово, в коре больших полушарий активируется распределённый паттерн нейронной активности. Он не локализован в одной точке, а представляет собой суммарный вектор в пространстве состояний нейронной популяции. Где семантически и синтаксически близкие единицы порождают похожие паттерны возбуждения – это нейробиологический аналог так называемых эмбеддингов.
Не пугайтесь этого слова. Это не страшнее, чем "акцентуации" или "ригидность".
Представьте, что каждое слово – это не просто буквы, а набор свойств, сила выраженности которых записана числами. Например, у слова "кошка" может быть свойство "пушистость" (допустим, эт число 8), "размер" (3), "хищность" (5), "домашность" (9). У слова "собака" – очень похожие числа: "пушистость" (7), "размер" (4-6), "хищность" (2-4), "домашность" (10). Эти несколько чисел и есть тот самый вектор – компактная строгая характеристика слова, что-то вроде его адреса в огромном многомерном доме смыслов.
Тогда слой эмбеддингов – это просто "таблица", где для каждого слова (точнее, кусочка слова – токена) записан такой вектор. В начале обучения эти числа случайны, но нейросеть читает миллионы предложений и понемногу подправляет числа так, чтобы слова, которые часто встречаются в одинаковых контекстах (например, "кошка" и "собака" оба сидят, бегают, мяукают/лают, живут дома), получили близкие "адреса". А слова из совсем разных сфер ("кошка" и "карандаш") окажутся далеко друг от друга. Таким образом, близость векторов отражает смысловую или тематическую похожесть. Вот и всё.
Ещё раз коротко то же самое на умном языке.
В искусственной нейросети аналогом упомянутого выше "суммарного вектора" и "пространства состояний" выступает слой эмбеддингов, преобразующий токен (подслово) в плотный вектор фиксированной размерности. Обучение этих векторов приводит к тому, что в итоге слова со схожей дистрибуцией располагаются близко в векторном пространстве.
Обе системы, таким образом, решают одну и ту же задачу:
перевести символьную информацию в форму, пригодную для параллельной обработки нейроноподобными элементами.
Если не очень понятно, то не торопитесь. Подышите, отдохните, ещё раз перечитайте.
.
Контекстное кодирование: механизмы избирательного внимания
Сам по себе вектор слова в моменте статичен (хотя и может время от времени меняться) и не отражает его текущей роли в предложении. Следующий фундаментальный шаг – контекстуализация, и здесь обе сети демонстрируют удивительно схожий принцип. В мозге ключевую роль играет механизм внутреннего внимания, опосредованный префронтальной корой и взаимодействием с височными отделами. Нейронные ансамбли, кодирующие слова, удерживаются в рабочей памяти, а их взаимное влияние динамически модулируется: релевантные для текущей задачи единицы усиливаются, нерелевантные подавляются. Электрофизиологические исследования показывают, что синхронизация в гамма- и тета-диапазонах служит инструментом такого избирательного взвешивания.
В архитектуре LLM-нейросети этому точно так же соответствует механизм self-attention (внимание). Для каждого токена вычисляются запрос (query), ключи (keys) и значения (values) – своего рода проекции входного вектора. Скалярное произведение запроса с ключами даёт оценку релевантности, а последующее взвешивание значений позволяет каждому токену собрать информацию из всего контекста. Итоговое представление слова на выходе блока внимания – это уже не изолированный вектор, а продукт динамического смешения всех элементов входа.
И в том и в другом случае работает единый принцип: "каждый элемент обогащается контекстом с помощью избирательного доступа ко всем остальным элементам на основе функции внимания". Это, кстати, решение знаменитой проблемы дальних зависимостей в языке.
.
Иерархическая предсказательная сборка: от замысла к слову
Порождение связного текста не происходит мгновенно. Сначала формируется общий план – семантический каркас будущего высказывания, который затем поэтапно разворачивается в грамматические конструкции и, наконец, в конкретные лексемы. Нейролингвистические модели, такие как модель двойного маршрута или иерархический предиктивный кодинг, предполагают, что вышележащие зоны коры (например, зона Вернике, префронтальная кора) генерируют нисходящие предсказания для нижележащих зон (зона Брока, моторная кора). Когда реальная активация отклоняется от предсказания, возникает сигнал ошибки, который корректирует речевой план. Процесс имеет каскадный, иерархический характер.
Современные LLM, построенные как "многослойные трансформеры" (GPT - Generative Pre-trained Transformer), реализуют похожий принцип. Нижние слои сети склонны улавливать локальную синтаксическую структуру и поверхностную сочетаемость, тогда как верхние слои кодируют более глобальные, абстрактные аспекты – тему, жанр, логическую структуру текста. Когда модель порождает длинное рассуждение с помощью цепочки мыслей (chain-of-thought), она, по сути, производит промежуточные скрытые представления, соответствующие "плану", прежде чем выдать окончательный текст.
Иерархическая организация и использование предсказаний – сначала на уровне общего смысла, затем на уровне конкретных слов – оказывается общей чертой обеих систем.
.
Выбор следующего слова: соревнование популяций и нормализация
В момент, когда необходимо произнести конкретное слово, в мозгу разворачивается конкурентный процесс. Одновременно активируются несколько нейронных ансамблей, кодирующих семантически близких кандидатов ("врач", "доктор", "терапевт"). Благодаря механизму латерального торможения (взаимного подавления) побеждает ансамбль с наивысшим уровнем активации. Соотношение сил регулируется общим контекстом и нейромодуляторами, например дофамином, который может менять "температуру" процесса, делая выбор то более детерминированным, то более стохастическим.
В искусственных нейросетях этот этап реализован через преобразование выходного вектора логитов в вероятностное распределение при помощи функции softmax. Softmax экспоненциально усиливает различия между оценками: кандидаты с высокими логитами (начальные предсказания модели) получают подавляющую долю вероятности, остальные отсекаются. Далее токен выбирается либо жёстко (argmax), либо сэмплированием, где параметр температуры управляет степенью случайности точно так же, как нейромодуляторы в биологической сети.
Это практически одинаковый механизм принятия решения: конкурирующие репрезентации преобразуются в победителя с помощью нелинейной нормализации.
.
Мониторинг и коррекция ошибок: точка расхождения
Одно из заметных различий между биологической и искусственной системами касается контроля качества в реальном времени. Мозг обладает развитой системой внутреннего мониторинга речи. Моторная команда на артикуляцию копируется в виде "эфферентной копии", и на её основе внутренняя модель речевого аппарата предсказывает ожидаемый звуковой результат. Если прогноз не совпадает с намерением (например, всплыло не то слово), передняя поясная кора (ACC) генерирует сигнал ошибки, и высказывание корректируется до озвучивания или прямо в процессе произнесения.
В классической авторегрессионной схеме декодирования LLM такой встроенной петли обратной связи нет: токен, однажды выбранный, немедленно подаётся на вход для предсказания следующего, без возможности "отменить" его, если он нарушил общую связность. Однако это различие не является принципиальным для архитектуры: современные методы вроде генерации с самокритикой и верификацией, а также использование явной модели мира для предсказания последствий шага, постепенно вводят в искусственные системы аналоги внутреннего мониторинга. Таким образом, даже здесь наблюдается сходство.
.
Заключение: единство принципов, различие реализаций
Обобщая всё вышесказанное, получаем, что сходство между мозгом и большой языковой моделью (LLM) оказывается не какой-то там притянутой за уши поверхностной метафорой, а отражением общих алгоритмических решений, продиктованных самой природой задачи:
преобразование символов в векторы, контекстное взвешивание через внимание, иерархическое разворачивание предсказаний, конкурентный выбор с нормализацией.
Различия касаются физического субстрата и режима обучения: биологическая сеть непрерывно адаптируется, использует рекуррентную динамику и химическую модуляцию, в то время как искусственная сеть представляет собой статичную многослойную архитектуру с дискретным обучением. Но именно абстрактная общность принципов позволяет сегодня не только моделировать речевую деятельность, но и лучше понимать самих себя – через призму создаваемых нами же нейросетей.
Обратите внимание на последнюю фразу. Очень похожим образом, помню, высказывался несколько лет назад нейробиолог Анохин К.В. на одной из конференций, посвященных проблеме сознания, когда презентовал "гиперсетевую модель мозга".
------------
Подробнее о различиях между алгоритмами ИИ и мозга ⟾⟾⟾ нажать, читать
Автор: Вадим Субботин
Психолог, Клинический психолог
Получить консультацию автора на сайте психологов b17.ru