Я обожаю шахматы. И, как многие, следил за успехами больших языковых моделей. Казалось, ещё чуть-чуть — и машина начнёт мыслить как человек, если не лучше. Но однажды мне стало интересно: а насколько современные LLM на самом деле близки к живому уму? И можно ли измерить это в числах?
Я взялся за эксперимент, который превратился в почти детективное расследование. Результат заставил меня пересмотреть всё, что я думал об искусственном интеллекте, его эффективности и сроках появления AGI.
Боль и гипотеза
Меня раздражало, что все разговоры о «супер-ИИ» крутятся вокруг бенчмарков, которые мало говорят о реальной силе мышления в конкретной, сложной игре с полной информацией — в шахматах. Захотелось получить точную формулу: как параметры модели (размер, архитектура, способность к рассуждению) влияют на её шахматную силу против обычного человека-любителя.
Моя гипотеза была проста: вероятно, зависимость линейна или близка к ней, и уже условная GPT-5 где-то рядом с уровнем «надёжно сильнее человека». Я ожидал, что порог доминирования будет достигнут при разумных десятках или сотнях миллиардов параметров.
Теперь, забегая вперёд: я ошибался. Причём драматически.
Что я сделал (простыми словами)
Я собрал данные о нескольких десятках моделей — открытых и условно-закрытых, разного размера, с разным временем на «размышления» (ризонинг) и без него. Для каждой определил метрики: размеры скрытых слоёв, число активных параметров, длину контекста и т.д. Целевой переменной стал ожидаемый счёт партии против любителя уровня 1200-1400. Чем выше score, тем лучше играет машина.
Дальше — классический регрессионный анализ. Я построил формулы, предсказывающие минимально возможный (minScore) и максимально возможный (maxScore) счёт. Средняя абсолютная ошибка (MAE) получилась всего 0.24–0.26. Это значит, модель предсказывала силу с хорошей точностью. Если взять удвоенную MAE как грубый 95% интервал, то предсказание попадало в коридор ±0.5 очка. Вполне прилично.
Что влияло на шахматную силу?
- Логарифмы размеров (чем больше модель, тем умнее, но с убывающей отдачей).
- Отношения размеров скрытых компонентов (чем «закрытее» модель, тем лучше).
- Самое интересное — наличие ризонинга (Think). Он давал дополнительный буст, но по-особенному: умножался на логарифм размера.
Всё это вылилось в довольно компактные, хоть и страшноватые на вид формулы. Для энтузиастов я оставлю их в конце, а пока — главное.
Момент истины: сколько нужно, чтобы победить гарантированно?
Формулы у меня в руках. Что делает любой уважающий себя исследователь? Правильно — экстраполирует.
Я задал себе вопрос: какого размера должна быть модель, чтобы в 95% случаев (то есть с учётом ошибки предсказания) гарантированно побеждать любителя, скажем, за 21 ход? Чтобы нижняя граница предсказанного счёта ушла выше нуля и даже в худшем случае противник не имел шансов.
И тут началось.
По моим расчётам выходило, что если масштабировать Qwen3.7-Plus (FP16/BF16), её придётся увеличить в 2195 раз —до чудовищных 76.8 триллионов параметров. Но даже эта цифра на два порядка меньше, чем оценочная информационная ёмкость человеческого мозга (порядка 10 000T в int4). Мозг, который легко умещается в черепной коробке и потребляет 20 ватт, всё ещё на два порядка сложнее, чем гипотетический трансформер, требующий под себя дата-центр для одного пользователя.
И тут я задумался: если даже чудовищный (по нынешним меркам) трансформер на 76.8 триллионов параметров в 130 раз проще человеческого мозга, но всё ещё не гарантирует победы над любителем — может, дело вовсе не в количестве? Может, архитектура живого мозга устроена принципиально иначе — и именно поэтому какая-нибудь зверушка с мозгом меньше нашего способна на удивительные вещи?
Так в моём эксперименте появился биологический бенчмарк. Я пересчитал свои формулы в «синаптический эквивалент», используя оценки информационной ёмкости одного синапса (от 1 до 5 бит, по данным нейробиологов) и переведя всё в int3/int4.
Неожиданный поворот: дельфин-гроссмейстер и капуцин-шахматист
Что оказалось? Для гарантированной победы за 21 ход на уровне гроссмейстера биологической системе нужно около 39.7T синапсов при 6.4T активных на раздумья (в int3). И знаете, кто идеально вписывается в эти параметры?
Гринда, он же чёрный дельфин.
Да-да, дельфин с мозгом, близким по объёму к человеческому, при условии длительного мотивированного обучения (например, давать ему рыбу за каждый верный ход) потенциально способен стать шахматным гроссмейстером. У него даже есть запас по числу синапсов. И это не фантастика: гринд обучаемы, социальны и решают сложные задачи в дикой природе. Просто представьте: дельфин, который за 21 ход ставит мат вашему бате.
Но и это ещё не самое поразительное. Я спустился ниже по лестнице интеллекта и посмотрел, кто способен просто побеждать любителя. Оказалось, для этого хватает 11.8T синапсов при 346B активных (int4). Под эти цифры идеально подходит… капуцин.
Обезьянка-капуцин. С мозгом в 200 раз меньше человеческого. Если ей выдавать лакомство за правильные ходы, она, согласно расчётам, сможет играть наравне с человеком-любителем. Не разгромит его, не будет стабильно побеждать — а именно выйдет на равные. С рейтингом в районе 1200–1400. С тем, кто знает дебютные принципы, но зевает тактику и не умеет считать глубоко. Капуцин, который ходит в шахматную школу, способен составить ему достойную конкуренцию.
Глубинный вывод: эффективность против масштаба
Вот здесь меня и накрыло осознание, ради которого, наверное, всё затевалось.
Мы гонимся за гигантскими языковыми моделями, строим дата-центры, сжигаем мегаватты — а эволюция уже миллионы лет назад создала «процессор», который решает ту же задачу в компактном объёме черепной коробки и с энергопотреблением, как у лампочки. Капуцин, чей мозг в 200 раз меньше нашего, и в тысячу раз «легче» гипотетического 76.8T-трансформера, выходит на равные с человеком-любителем. Гринда с мозгом, сопоставимым с человеческим, потенциально способен к гроссмейстерству.
Это значит, что нынешние LLM архитектурно неоптимальны в сотни, если не тысячи раз. И проблема не в железе, не в данных, не в деньгах. Проблема в самом принципе. Мы пытаемся взять объёмом там, где природа взяла изяществом.
Современный трансформер похож на паровоз, который везёт один вагончик с углём: работает, но КПД удручает. А биологический мозг — это спортивный электрокар: меньше, тише, быстрее, и заправляется от розетки.
Отсюда простой, но жёсткий вывод: если судить по открытым данным и текущим архитектурам, до AGI ещё очень далеко. Простое масштабирование упирается в потолок задолго до того, как модель сравняется хотя бы с капуцином по эффективности. Нужно что-то принципиально иное.
Два взгляда в будущее: Тяжеловоз против Спринтера
И вот тут мой внутренний голос раскололся на два рупора. Оба кричат убедительно.
Пессимист-тяжеловоз устало облокачивается на серверную стойку и говорит:
«Твои расчёты — приговор. Чтобы доминировать над любителем, нужны десятки триллионов параметров, дата-центр на одного пользователя и архитектура, которая в сотни раз хуже биологической. Мы не просто далеки от AGI — мы вообще не там ищем. Трансформеры никогда не станут по-настоящему умными, пока мы не пересоберём их по лекалам живой природы. А это займёт десятилетия, если не поколения».
Оптимист-спринтер врывается с противоположной стороны:
«А ты учитываешь то, чего не видишь? За закрытыми дверями лабораторий уже существуют модели, которые мы с тобой не можем протестировать. Mythos и Fable, по слухам, играют на уровне любителя при гораздо более скромных размерах — и их уже запретили в США. OpenAI заявила, что теперь знает, как построить AGI. Anthropic даёт более 60% вероятности на системы с рекурсивным самоулучшением уже к 2028 году. Возможно, секрет не в объёме, а в ультра-эффективных алгоритмах, которых мы просто ещё не видели в открытом доступе. Прогресс идёт по экспоненте, просто ты смотришь на старые графики».
Я слушаю обоих — и понимаю, что истина, скорее всего, где-то посередине. Публичные данные действительно рисуют картину архитектурного кризиса. Но темпы закрытых разработок и намёки из лабораторий заставляют держать в уме вариант, что спринтер уже разогревается за кулисами.
Сухой остаток
Что я вынес из этого эксперимента — и что, надеюсь, заберёт с собой читатель:
- Масштабирование ради масштабирования — тупик. Современные LLM требуют на порядки больше «вычислителей», чем биологический мозг, для решения тех же задач. Нужна новая архитектура.
- Живой ум всё ещё недосягаем по эффективности. Капуцин с мозгом в 200 раз меньше нашего играет наравне с любителем. Гринд потенциально способен стать гроссмейстером. Эволюция решила задачу, которую мы пока решить не можем.
- AGI не просматривается на горизонте текущих подходов. Если только за закрытыми дверями не происходит то, о чём нам не рассказывают.
- Возможно, секрет кроется в алгоритмах, а не в железе. Биология подсказывает: ультра-эффективные, малоактивные, нейроморфные системы могут быть ответом. Именно туда, судя по всему, смотрят ведущие лаборатории.
Что дальше?
Я продолжу копать. Мой следующий шаг — попытаться учесть в расчётах модели с принципиально иной архитектурой: Liquid AI, нейроморфные чипы, может быть, гибридные системы. В конце концов, если капуцин может — значит, вопрос лишь в том, как именно организовать вычисления.
А что думаете вы? Ждать нам AGI в этом десятилетии или признать, что мы пока строим цифровых динозавров, пока эволюция где-то на задворках посмеивается со своим дельфином-гроссмейстером? Делитесь в комментариях — мне правда важно услышать ваш взгляд.
-------------------
Техническая врезка для гиков: основные формулы и цифры
B - количество параметров всего (в миллиардах)
A - активных одновременно
Size - размер в ГБ
Think - reasoning 0/1 (или 0..1 для None/Low/Auto/High/Max(Think))
Score = 1/количество_полуходов при выигрыше и -1/количество_полуходов при проигрыше (три нелегальных хода = проигрыш)
min/max — границы диапазона
minScore = -0.395058 + (-0.045591) * ( (minSize/(maxSize+1e-9) — 0.561922) / 0.440681 ) + 0.035599 * ( (ln1p(minA) — 2.110085) / 1.267073 ) + 0.032693 * ( (ln1p(maxSize) — 4.296995) / 3.324634 ) + 0.031105 * ( (ln1p(maxA) — 2.495968) / 1.678919 ) + 0.031016 * ( (ln1p(maxB) — 3.658531) / 2.678091 ) + 0.030505 * ( (ln1p(minB) — 3.384278) / 2.485328 ) + 0.028912 * ( (ln1p(minSize) — 3.138865) / 2.262121 ) + (-0.017158) * ( (minB/(maxB+1e-9) — 0.870329) / 0.282739 ) + (-0.016873) * ( (minA/(maxA+1e-9) — 0.836211) / 0.333065 ) + 0.014380 * ( (Think*ln1p(maxSize) — 1.600648) / 2.712394 ) + (-0.014184) * ( (Think — 0.409315) / 0.479297 ) + 0.013214 * ( (Think*ln1p(maxA) — 0.895989) / 1.235917 ) + 0.010269 * ( (Think*ln1p(maxB) — 1.355918) / 2.225481 )
maxScore = -0.377411 + (-0.044432) * ( (minSize/(maxSize+1e-9) — 0.561922) / 0.440681 ) + 0.035577 * ( (ln1p(minA) — 2.110085) / 1.267073 ) + 0.030690 * ( (ln1p(maxA) — 2.495968) / 1.678919 ) + 0.029835 * ( (ln1p(maxSize) — 4.296995) / 3.324634 ) + 0.029186 * ( (ln1p(maxB) — 3.658531) / 2.678091 ) + 0.028555 * ( (ln1p(minB) — 3.384278) / 2.485328 ) + 0.025504 * ( (ln1p(minSize) — 3.138865) / 2.262121 ) + (-0.018603) * ( (minB/(maxB+1e-9) — 0.870329) / 0.282739 ) + (-0.017716) * ( (Think — 0.409315) / 0.479297 ) + (-0.017505) * ( (minA/(maxA+1e-9) — 0.836211) / 0.333065 ) + 0.014825 * ( (Think*ln1p(maxSize) — 1.600648) / 2.712394 ) + 0.012466 * ( (Think*ln1p(maxA) — 0.895989) / 1.235917 ) + 0.009924 * ( (Think*ln1p(maxB) — 1.355918) / 2.225481 )
MAE для minScore = 0.244, для maxScore = 0.263. Удвоенная MAE как примерный 95% интервал: ±0.49 для min и ±0.53 для max.
Зависимости отдельных переменных (пример):
- ln1p(minA) vs minScore: y = -0,0445x² + 0,4258x — 1,024, R² = 0,4961
- ln1p(minA) vs maxScore: y = 0,2976*ln(x) — 0,5148, R² = 0,4187
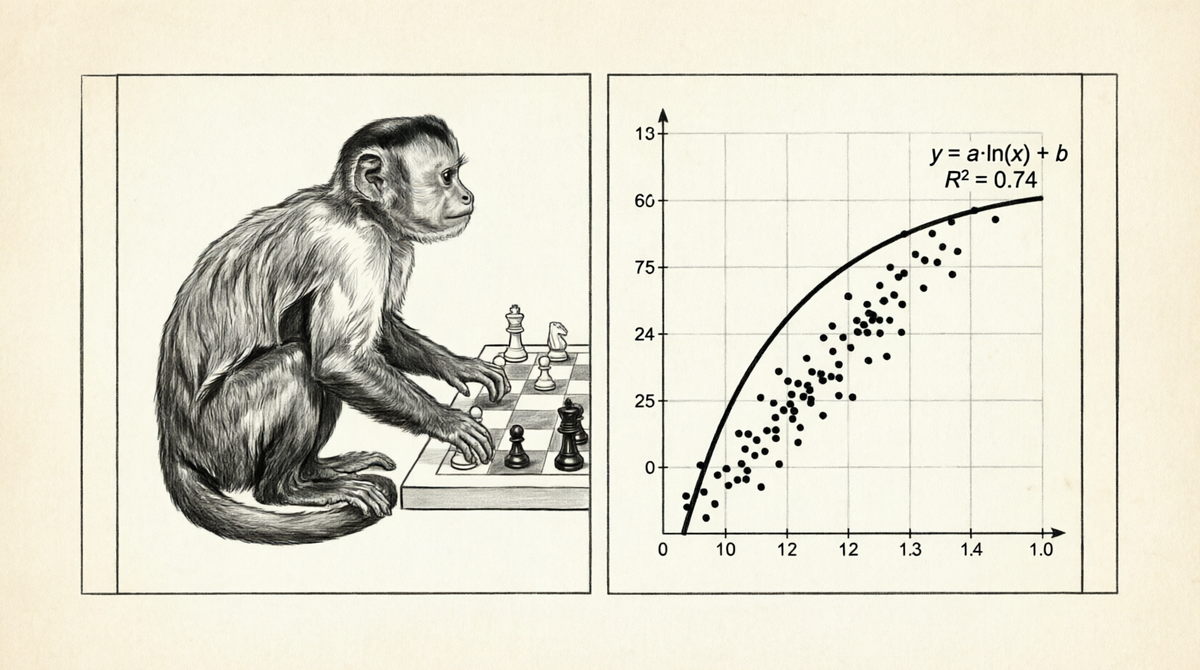
- ln1p(maxSize) vs maxScore: y = 0,3205*ln(x) — 0,7107, R² = 0,5794
- ln1p(maxSize) vs minScore: полином 4-й степени, R² = 0,7422
Экстраполяция:
- Гарантированная победа за 21 ход (Stockfish 8) против любителя:
Либо Qwen3.7-Plus FP16/BF16, масштабированная в 2195 раз — 76.8T параметров.
Либо проприетарная плотная модель 16.3T+ fp47 с обязательным ризонингом. - Биологический эквивалент гроссмейстерского уровня: гринда 39.7T A6.4T (int3).
- Биологический эквивалент уровня «наравне с любителем»: капуцин 11.8T A346B (int4).
Человеческий мозг: ~10 000T int4, A100-1600T.