⚡️ Как Redis считает миллиарды уникальных значений, почти не тратя память
Есть алгоритм HyperLogLog. Он позволяет примерно понять, сколько уникальных элементов прошло через систему, используя около 12 KB памяти.
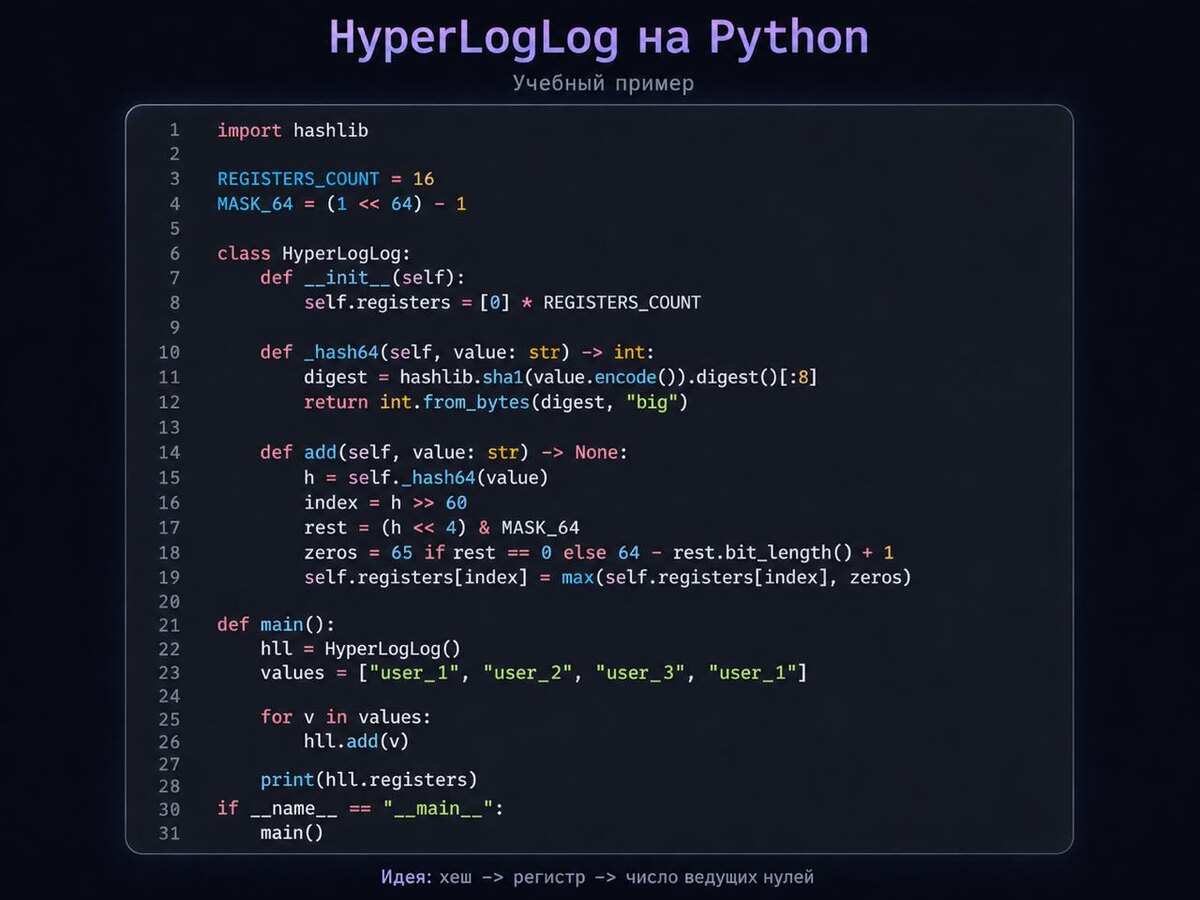
Идея простая: Redis не хранит сами элементы.
Он делает так:
- берёт элемент
- считает от него хеш
- часть хеша использует как номер ячейки
- в другой части смотрит, сколько нулей подряд встретилось
- если новое число больше старого - обновляет ячейку
Почему это работает?
Потому что длинная серия нулей в хеше встречается редко.
Например:
- 1 ноль подряд - довольно часто
- 5 нулей подряд - уже реже
- 10 нулей подряд - примерно шанс 1 к 1024
- 20 нулей подряд - совсем редкое событие
Если Redis увидел очень редкий паттерн, значит через него, скорее всего, прошло много разных элементов.
В Redis используется 16 384 маленьких счётчика. Каждый хранит максимальную «редкость», которую видел для своей группы элементов.
Потом Redis объединяет эти значения математикой и получает оценку уникальных элементов.
Не точное число, а очень близкую оценку.
Главный прикол HyperLogLog:
он может обработать хоть миллионы, хоть миллиарды значений, но память почти не растёт.
Именно поэтому Redis умеет считать уникальных пользователей, IP, запросы или события без огромных таблиц и списков.