🌟 Топовые LLM плохо предсказывают будущие научные открытия
Оксфорд, Стэнфорд, Институт Аллена и Sakana AI выложили работу, в которой ставится вопрос: способен ли ИИ предвидеть ход научного прогресса.
Исследование примыкает к дискуссии об "автономном учёном" на базе ИИ - направлении, которое сейчас волнует индустрию, его развивает в том числе и Sakana AI.
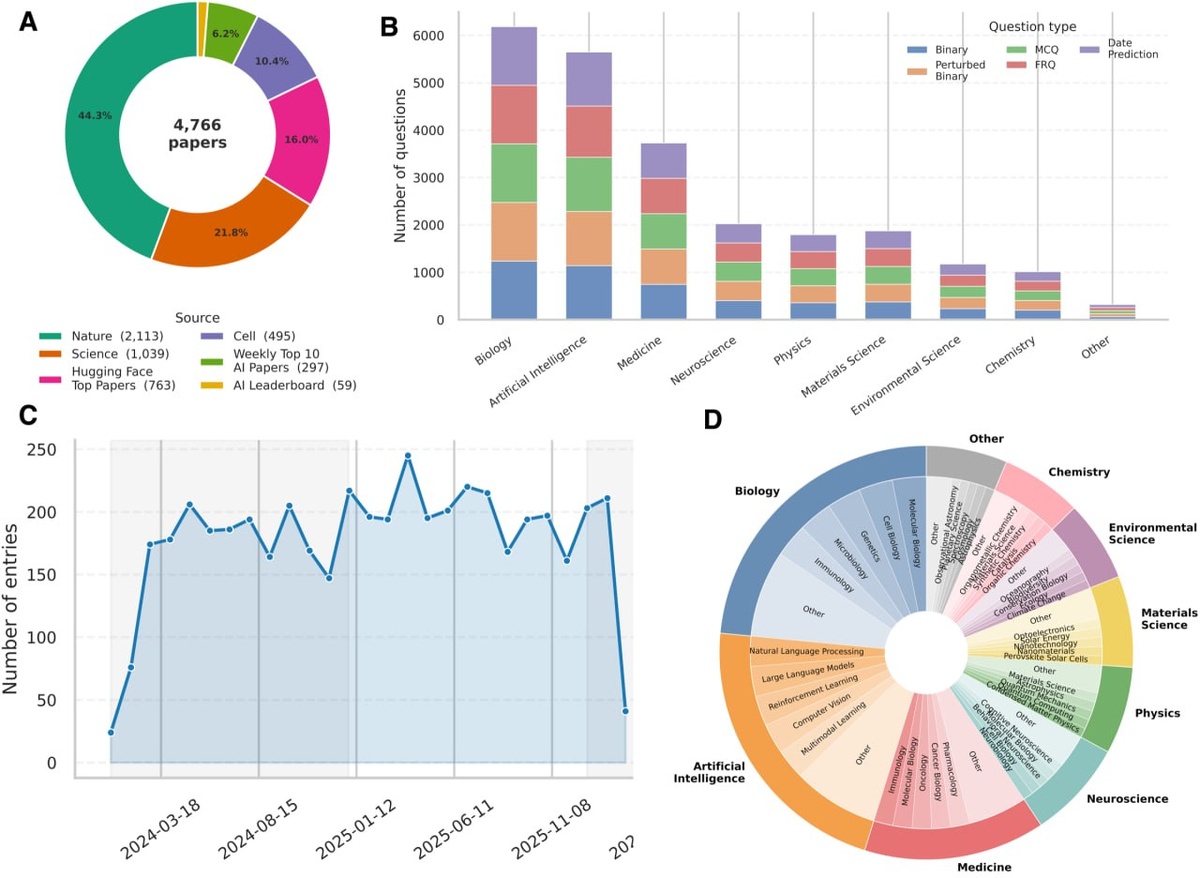
Чтобы отделить реальный прогноз от существующих знаний, авторы построили бенч CUSP.
Языковые модели обычно знают уже состоявшиеся открытия из обучающих данных, поэтому при прямом вопросе об известном результате легко дают верный ответ.
CUSP это блокирует: для события, скажем, 2025 года модели разрешают опираться только на сведения, доступные до этой даты.
Говоря проще, систему возвращают в прошлое и заставляют предсказывать будущее вслепую.
В основу теста легли 4760 научных событий за январь 2024 - март 2026 годов из журналов Nature, Science, Cell и подборок заметных работ по ИИ. На этой базе было сформировано 17 429 заданий.
В прогонах принимали участие GPT-5.4, Claude Sonnet 4.5, DeepSeek R1 и GPT-OSS 20B.
🟡Результаты
Выбрать правдоподобное техническое направление смогли - на вопросах с выбором ответа GPT-5.4 показала точность 81,9%.
Но определить, будет ли конкретное достижение вообще реализовано, модели почти не способны: точность держалась в пределах 45–52%, что близко к подбрасыванию монеты.
Сроки все модели называли с запаздыванием: медианная ошибка GPT-5.4 составила 14 месяцев, Claude Sonnet 4.5 - 17, а вот LLaMA 3.3 оказалась самой точной - 4 месяца.
В задачах на проектирование решения даже лучший результат (5,04 из 10 у GPT-5.4) не попадал в реально применённый позже технический путь.
Рисёрч отмечает деталь: качество прогноза почти не зависело от того, относится событие к периоду до или после среза знаний модели.
Это означает, что дело не только в нехватке данных. Доступ к дополнительной информации повышает результаты, но не закрывает разрыв, причём для самых цитируемых работ он был заметнее.
До кучи - модели систематически переоценивали уверенность в своих ответах.
🟡Вывод
LLM пока выступают скорее ретроспективными толкователями уже известных результатов, чем надёжными предсказателями будущих.
📌Лицензирование: MIT License
#AI #ML #LLM #Research #Science #Benchmark