На 1M токенов - 9.7x ускорение префилла и 15.6x на декоде против M2. В марте их лид по претрейну писал, почему для M2 откатились на full attention: эффективные варианты не были готовы к проду. Спустя полгода готовы. Схема двухстадийная. Сначала лёгкая index-ветка выбирает релевантные блоки KV. Дальше sparse attention считается только по ним, а не по всему контексту. Дешёвый 1M-контекст в опенсорсе - это другой режим работы с длинным контекстом и другая экономика инференса для агентов. Ждём техрепорт и замеры качества. Ну и приятно, что всё это в опенсорсе. https://x.com/MiniMax_AI/status/2059286515155599595 #MSA #OpenSource #M3
✔️ MiniMax показали тизер Sparse Attention для M3.
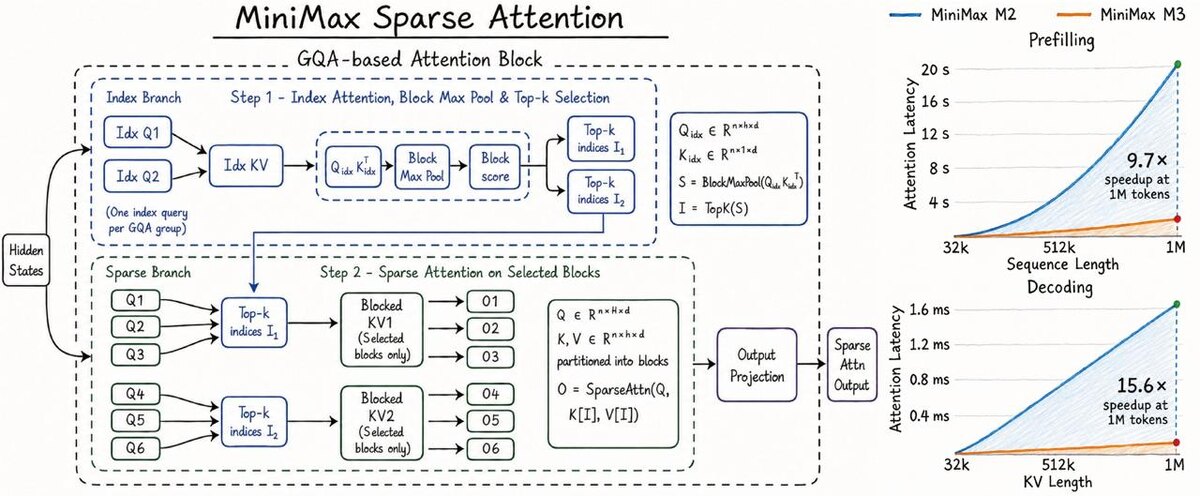
На 1M токенов - 9.7x ускорение префилла и 15.6x на декоде против M2.
В марте их лид по претрейну писал, почему для M2 откатились на full attention: эффективные варианты не были готовы к проду.
Спустя полгода готовы.
Схема двухстадийная. Сначала лёгкая index-ветка выбирает релевантные блоки KV. Дальше sparse attention считается только по ним, а не по всему контексту.
Дешёвый 1M-контекст в опенсорсе - это другой режим работы с длинным контекстом и другая экономика инференса для агентов.
Ждём техрепорт и замеры качества. Ну и приятно, что всё это в опенсорсе.
https://x.com/MiniMax_AI/status/2059286515155599595
#MSA #OpenSource #M3