
Диффузионную модель уровня FLUX только что запустили целиком на iPhone — без облака, без API, без интернета. 512×512 за 9,4 секунды прямо на iPhone 17 Pro Max. Сделала это калифорнийская PrismML, и трюк, которым они этого добились, — не магия, а очень аккуратная инженерия: веса диффузионного трансформера ужали до одного бита (и до троичного «полутора битов»). Давайте разберём, что там под капотом на самом деле, потому что за бойкими цифрами из новости прячется довольно красивая история про два уровня сжатия, надетых друг на друга.
Что именно выкатили
26 мая 2026 года PrismML — стартап, выросший из Калтеха (CEO — профессор Babak Hassibi), при поддержке Khosla Ventures, Cerberus и вычислительных грантов Google — выложила семейство Bonsai Image 4B. Два варианта, оба под Apache 2.0, веса и код открыты на Hugging Face:
🟦 1-bit (бинарный) — веса трансформера принимают значения {−1, +1}. Максимальное сжатие, трансформер ужимается до 0,93 ГБ (в 8,3 раза). Это вариант «когда память и место важнее всего».
🟨 Ternary (троичный) — веса {−1, 0, +1}. Лишнее состояние «ноль» даёт модели больше свободы, поэтому качество выше. Трансформер — 1,21 ГБ (в 6,4 раза меньше оригинала).
📱 На iPhone 17 Pro Max полноразмерный FLUX.2 Klein 4B просто не влезает в бюджет памяти, а обе версии Bonsai — работают на устройстве. И ещё к запуску выкатили приложение Bonsai Studio для iOS.
Откуда растут ноги: FLUX.2 Klein
Bonsai Image — не модель «с нуля». Это сжатая версия FLUX.2 [klein] 4B от Black Forest Labs (тех самых, что вышли из Stability AI). И вот тут начинается самое интересное, потому что Klein сам по себе — уже продукт сжатия.
Смотрите на цепочку:
🧬 У Black Forest Labs есть флагман FLUX.2 [dev] — это 32 миллиарда параметров, ему нужен дата-центр и видеокарта класса H100.
✂️ В январе 2026-го BFL выпустили FLUX.2 [klein] («klein» по-немецки — «маленький»): через дистилляцию большую модель «научили» выдавать похожий результат всего за 4 шага денойзинга вместо десятков. Версия 4B влезает в ~13 ГБ видеопамяти потребительской карты и лежит под Apache 2.0.
🔬 А PrismML взяла этот уже ужатый Klein 4B и применила вторую, совершенно другую технику сжатия — экстремальную квантизацию весов. Архитектуру не трогали вообще, поменяли только то, как хранятся числа в весах трансформера.
То есть две ортогональные идеи сложили стопкой: сначала дистилляция (меньше параметров и меньше шагов), потом квантизация (меньше бит на каждый параметр). Klein-4B как база подобран идеально ещё и юридически — Apache 2.0 у основы, Apache 2.0 у производной, никаких лицензионных мин.
Как ужать вес до одного бита
Обычная модель хранит каждый вес как 16-битное число (FP16) — это плавная точка, куча оттенков. Идея 1-битной и троичной квантизации звучит почти издевательски: а давайте оставим у веса всего два или три возможных значения.
Это не выдумка PrismML — это прямое продолжение волны, которая началась с языковых моделей. Microsoft в феврале 2024-го показала BitNet b1.58, где веса LLM сидят в троичном наборе {−1, 0, +1}. Откуда взялись «1,58 бита»? Чистая математика: чтобы закодировать три состояния, нужно log₂(3) ≈ 1,585 бита на вес. PrismML до этого уже сделала 1-битные языковые модели Bonsai (март 2026), а теперь перенесла тот же подход на диффузионный трансформер — а это куда более капризный зверь, чем текстовая модель.
Тонкость, которую новости опускают: «1 бит» — это маркетинговое округление. На самом деле:
⚙️ у бинарной версии — 1,125 эффективного бита на вес. Само значение {−1, +1} — это 1 бит, но к группе весов добавляется один общий масштабирующий коэффициент в FP16 (group-wise scaling), и он размазывается по всей группе.
⚙️ у троичной — 1,71 эффективного бита на вес по той же причине.
⚙️ примерно 5% весов — самые чувствительные «проекционные слои» — вообще оставили в FP16. Их трогать нельзя, иначе качество рушится. Именно поэтому бинарные слои дают ~14-кратное сжатие, а итоговый трансформер — «всего» 8,3-кратное: эти 5% весят непропорционально много.
Само по себе тупо округлить FP16-веса до {−1, 0, +1} нельзя — модель развалится. За такими цифрами почти всегда стоит дообучение (quantization-aware training / дистилляция), когда сеть заранее «привыкает» жить в условиях, где у весов всего пара значений. Это и есть та самая «секретная начинка», ради которой существует PrismML.
Почему режут именно трансформер, а не всю модель
Диффузионная генерация — это итеративный денойзинг: модель пошагово «вычищает» шум, превращая его в картинку. И ключевой момент — на каждом шаге заново вызывается весь трансформер. Klein делает 4 шага, более тяжёлые модели — десятки. Поэтому размер трансформера бьёт сразу по трём фронтам: сколько памяти он занимает, сколько байт нужно гонять из памяти на каждом шаге и как быстро всё это считается.
Отсюда логика, что резать надо именно его:
🔋 диффузионный трансформер — самая жирная часть пайплайна и единственная, что крутится в цикле;
🎨 VAE (декодер, превращающий латентное представление в пиксели) оставили в FP16 — он маленький и критичен для качества картинки;
📝 текстовый энкодер сжали, но не до экстрима, и — внимание, красивая деталь — после кодирования промпта его вообще выгружают из памяти, он больше не нужен в цикле денойзинга.
Вот почему «средняя активная память» получается даже меньше, чем размер всех весов на диске:
📊 на 512×512 в среднем активны 1,5 ГБ (бинарь) и 1,96 ГБ (троичная) против 11,74 ГБ у оригинального FLUX.2 Klein — это в 7,8 и 6,0 раза меньше;
📊 на 1024×1024 — 1,95 ГБ и 2,38 ГБ против 14,39 ГБ.
Полный «деплой-пакет» (трансформер + сжатый текстовый энкодер + FP16 VAE) — 3,42 ГБ для бинарной версии и 3,88 ГБ для троичной. У полноразмерного Klein — 15,97 ГБ. Разница между «помещается в телефон» и «не помещается» ровно здесь.
Что под капотом на устройстве
Тут есть нюанс, который легко упустить: процессор айфона не умеет нативно перемножать 1-битные матрицы. Хранить веса в виде {−1, +1} — полдела; нужно ещё быстро на них считать. Поэтому PrismML тащит за собой низкоуровневые ядра под конкретное железо:
🍎 на Apple Silicon (iPhone, iPad, Mac) — пути через MLX, нативный для Apple фреймворк для тензорных вычислений;
🟩 на CUDA-видеокартах — низкобитные GEMM-ядра GemLite (GEMM — это перемножение матриц, фундамент любого инференса).
Узкое место на телефоне — даже не объём памяти, а её пропускная способность. Низкобитные веса — это банально меньше байт, которые надо тащить из памяти на каждом из шагов денойзинга. Отсюда и скорость: на Mac M4 Pro Bonsai Image оказывается до 5,6 раза быстрее стандартного полноточного пайплайна MFLUX, выдавая 512×512 примерно за 6 секунд. На iPhone 17 Pro Max — 9,4 секунды.
А что с качеством
Сжатие имеет смысл, только если картинки остаются нормальными. PrismML гоняла модель по трём бенчмаркам: GenEval (правильно ли собраны объекты и их свойства), HPSv3 (эстетика и человеческие предпочтения) и DPG-Bench (насколько точно модель следует длинному промпту). Вот как это выглядит в сравнении:
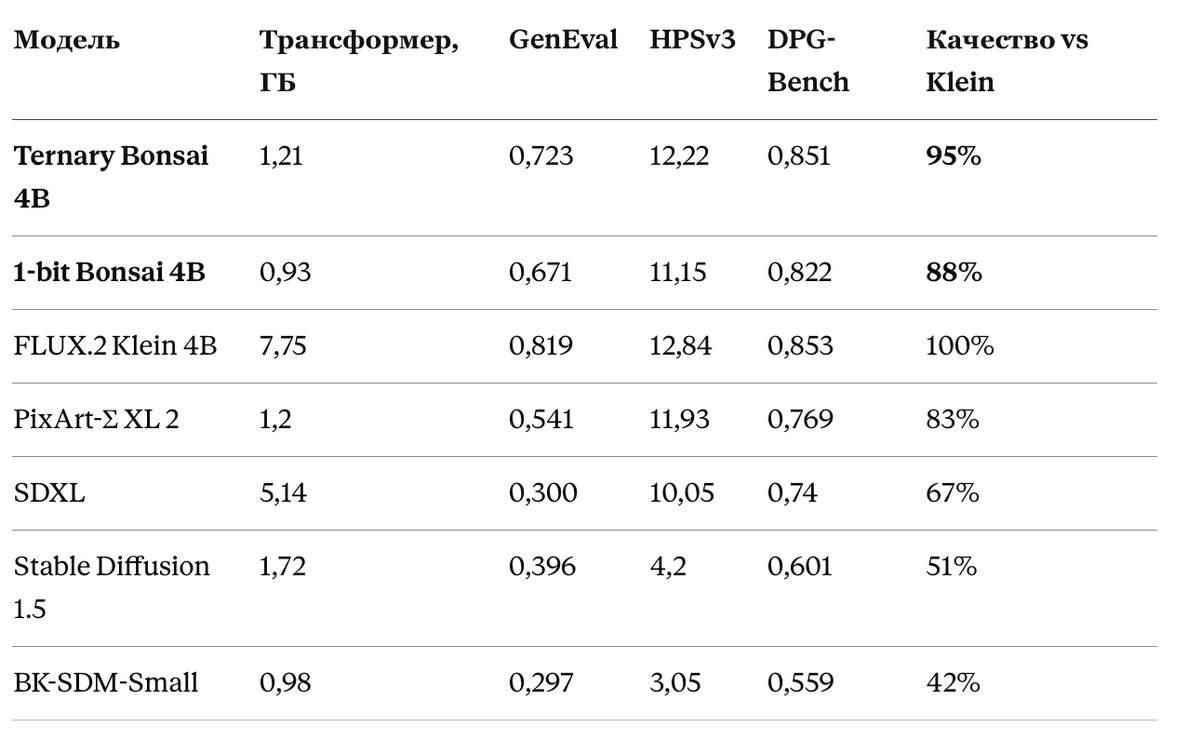
Что здесь по-настоящему важно — это сдвиг кривой Парето. Посмотрите на SDXL: он весит 5,14 ГБ, в четыре с лишним раза больше троичной Bonsai, а набирает жалкие 67% против её 95%. А модели сопоставимого размера (PixArt-Σ при 1,2 ГБ, BK-SDM при 0,98 ГБ) троичная Bonsai просто переезжает. То есть в карман к вам кладут поведение современного 4B-трансформера в том объёме памяти, где раньше жили заметно более слабые модели.
Честно: разрыв между троичной и бинарной версиями реальный (95% против 88%), и на мелких деталях/тексте в картинке он будет виден. Троичная — это «качество», бинарная — «лишь бы влезло».
Почему это вообще важно
Генерация картинок — задача не только про качество модели, но и про способ доставки. Облако останется правильным выбором для многих продуктов, но у облачной генерации есть встроенные издержки: каждый промпт — это удалённый запрос, каждая итерация — деньги, каждое нажатие — round-trip-задержка.
А генерация картинок по своей природе итеративна. Никто не останавливается на первом результате: люди правят промпт, сравнивают, плодят варианты, выкидывают неудачи и пробуют снова. Когда каждая попытка — это серверная задача с ценником и ожиданием, творческий цикл превращается в нечто, что приходится дозировать. Локальный инференс это ломает:
⚡ нет задержек — всё считается на устройстве, можно крутить варианты сколько угодно;
💸 нет платы за запрос — лимиты и биллинг просто исчезают как класс;
🔒 приватность — промпты и сгенерированные ассеты не покидают устройство;
🧰 для разработчиков — готовая основа, чтобы встроить генерацию прямо в офлайн-приложение, а не оборачивать чужой API.
Моё мнение
Меня в этой истории цепляет не «вау, картинка на айфоне» (это уже вопрос времени было), а то, что 1-битная революция перекинулась с языковых моделей на диффузию. Текстовые BitNet-модели показали, что в один-полтора бита можно ужать LLM без катастрофы. Перенести это на диффузионный трансформер сложнее: ошибка квантизации накапливается через десятки матричных умножений на каждом шаге денойзинга, и итеративная природа процесса её усиливает. То, что троичная версия удержала 95% качества при шестикратном сжатии трансформера, — это сильно.
И отдельно красиво, что это не закрытый демо-черри-пик, а Apache 2.0 с весами, кодом, вайтпейпером и приложением в App Store. Хочешь — берёшь и встраиваешь в свой продукт, хоть в коммерческий. Для индустрии, уставшей от «у нас потрясающая модель, вот вам платный API», это глоток свежего воздуха.
Трезвая оговорка: 9,4 секунды — это пока 512×512, не 4K, и качество всё-таки на пару процентов ниже базы. Это не «убийца облачного FLUX», а первая рабочая ступень к тому, чтобы серьёзная генерация жила у вас в кармане.
Что дальше
Прогноз короткий. Во-первых, низкобитная квантизация теперь пойдёт по диффузионным моделям волной — раз получилось с FLUX-классом, повторят и на других, и почти наверняка дотянут до 1024×1024 на флагманских телефонах за вменяемое время. Во-вторых, ждите встроенную офлайн-генерацию в обычных мобильных приложениях — не в специализированных «AI-арт» утилитах, а в мессенджерах, редакторах, заметках. И в-третьих, общий вектор: связка «дистилляция + экстремальная квантизация» становится стандартным рецептом, как затащить модель датацентрового класса на устройство, которое уже лежит у вас в кармане. Bonsai Image — ровно такой кейс, и, судя по открытой лицензии, далеко не последний.
Источники
Оригинальная новость
🔗 PrismML — Introducing 1-bit and Ternary Bonsai Image 4B
🔗 Telegra.ph — Bonsai Image 4B: как 1-бит и троичная логика запустили FLUX-класс картинки на iPhone
Первоисточники и материалы (проверено)
📄 Bonsai Image 4B — Whitepaper (PrismML, GitHub)
🤗 Коллекция Bonsai Image на Hugging Face (открытые веса)
📰 Пресс-релиз PrismML на PR Newswire
🧬 Black Forest Labs — анонс FLUX.2 [klein] (модель-основа)
⚙️ FLUX.2 [klein] 4B на Hugging Face