NVIDIA Blackwell (SM100) — это крупнейшее изменение микроархитектуры GPU за поколение. Формальных белых книг мало, поэтому практическое понимание приходит через микробенчмарки на уровне PTX/SASS. Ниже — краткий, но глубоко практичный разбор ключевых открытий по памяти, тензорным ядрам (MMA/TMA), кластерным особенностям и их влиянию на DL-ядра.
Ключевые архитектурные изменения
- TMEM: аккумуляторы MMA вынесены в явную «tensor memory». Результат ММА не принадлежит отдельному потоку — TMEM управляется на уровне MMA.
- tcgen05: теперь операции выдаёт один поток от имени CTA, а не warp/warpgroup. Это меняет паттерны выдачи CuTe-атомов.
- 2SM MMA (cta_group::2): парные CTA могут совместно выполнять MMA, шаря операнды и SMEM между собой — это даёт новые границы по размеру инструкции.
- Под-байтовые типы, CLC и PDL: поддержка микрошкалирования типов и динамических запусков, что открывает новые оптимизации в persistent-CTA паттернах.
- Кластеры и GPC: CTA-кластеры ко-планируются в GPC; если размер кластера не делит число SM на GPC — часть SM простаивает. В Blackwell введены preferred/fallback размеры кластеров, чтобы смягчить эту квантованность.
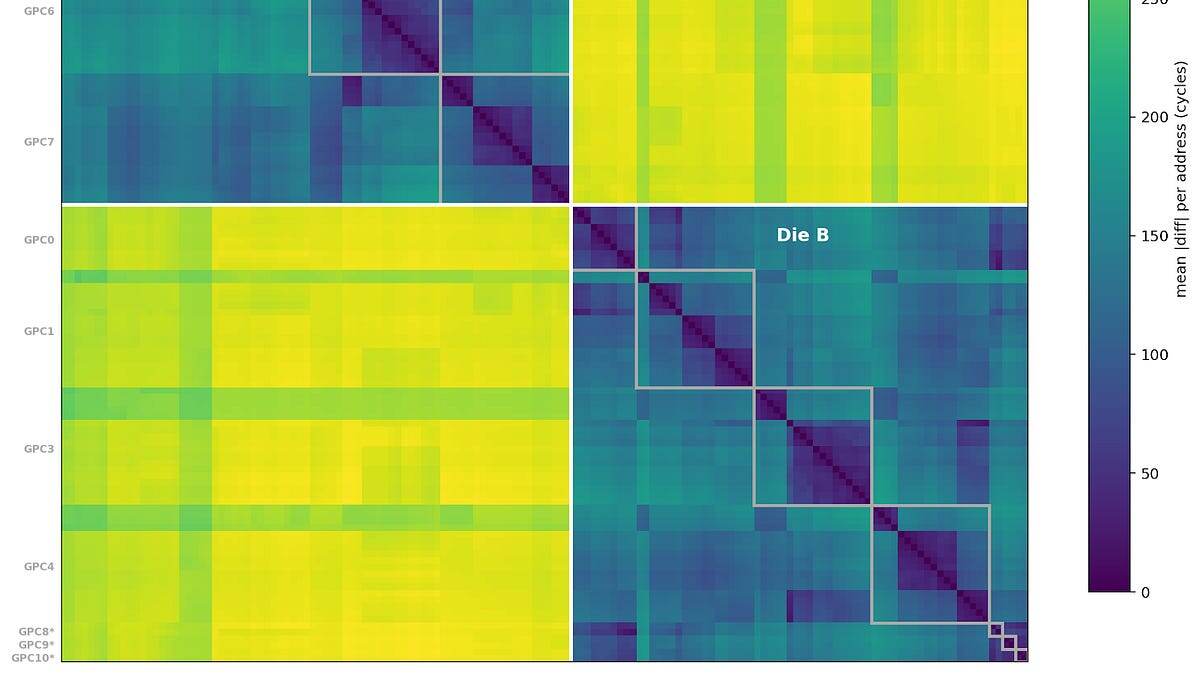
Топология, yield и задержки die-to-die
Физический расклад SM внутри GPC не обязан совпадать с логическим представлением. По pointer-chase замерам видно два набора SM, разделённых ~300 циклов — это пенальти при переходе между кристаллами в B200. Вывод: на уровне производительности возможна детерминированность, зависящая от физического yield и того, какие SM-ы включены в логические GPC.
Память: LDGSTS (cp.async) vs TMA (cp.async.bulk.tensor)
- LDGSTS (асинхронный глоб→SMEM): хорош для нерегулярных паттернов, пишет прямо в SMEM, снижая давление на регистры. В наших тестах 16-байт загрузки дают лучшее соотношение throughput/ресурсы; насыщение достигается ≈6.6 TB/s при ~32 KiB in-flight. Базовая латентность ~600 нс и удваивается при >8 KiB in-flight из-за MIO-throttle.
- TMA (tensor memory accelerator, UTMALDG/UBLKCP): оптимизирован для больших регулярных блоков, может масштабироваться до ~128 KiB in-flight и достигает пиков позже, но устойчиво выше в больших объёмах. Для малых объёмов (<32 B в-flight) иногда async copy быстрее; при больших — TMA выигрывает.
Мультicast и L2 Request Coalescer
TMA поддерживает явный multicast (копирование в SMEM нескольких CTA). L2 Request Coalescer (LRC) пытается коалесцировать запросы и снижать L2-трафик. В явном multicast L2-трафик практически исчезает (идея 1/cluster_size), но и в неявном сценарии LRC хорошо срабатывает: SMEM-fill throughput близок к идеалу, хотя при больших объёмах в implicit случае L2 нагружается сильнее.
Distributed Shared Memory (DSMEM)
DSMEM позволяет CTA внутри кластера читать общую SMEM; но такие загрузки пакетизуются, похожи на глобальные, и пропускная способность заметно ниже локального SMEM (128 B/clk). Важная оптимизация: ld.shared (локальная) даёт лучший throughput, чем ld.shared::cluster; при больших объёмах лучше использовать cp.async.bulk / UBLKCP, чтобы увеличить bytes per instruction.
MMA: формы, узкие места и 2SM MMA
- Форма инструкций сильно влияет. MMA становится всё более shape-зависимым: при M=64 мы видим ~50% от теоретического пика, при M=128 — близко к 100%. Причина — SMEM-ограничение: ниже N≈128 операции SMEM-bound, затем переход в compute-bound.
- 2SM MMA даёт практически идеальное слабое масштабирование: при увеличении ресурсов в 2× достигается ~2× ускорение, особенно для больших M/K. Для ABLayout=SS малые N были SMEM-bound, и 2SM помогла разрезать шину SMEM.
- Микрошкалирование типов (FP8, MXF4/8, S8) показывает схожую пропускную способность при одинаковой битовой ширине; накладные расходы микрошкалирования минимальны.
Латентности и in-flight MMAs
Латентность одиночной MMA растёт линейно с N; скачок при переходе к N=256 заметен. На практике ядра используют 1-4 in-flight MMA: при 4 in-flight мы наблюдали plateau ≈78-80% «Speed-of-Light» (максимальной практической пропускной способности). Большие N дают более высокий процент SoL.
Рекомендации для разработчиков DL-ядер
- Для больших регулярных блоков и стабильных паттернов используйте TMA; для динамических/неправильных паттернов — LDGSTS.
- Используйте самые большие доступные формы MMA, которые помещаются в SMEM-тайл — это максимизирует пропускную способность.
- Включайте fallback-кластеры (1 или 2) при persistent-CTA, чтобы избежать простоев из-за делимости кластера.
- Для DSMEM при больших объёмах применяйте cp.async.bulk/UBLKCP;
- Тестируйте на реальных нодах с включёнными счётчиками (NCU) — физический yield и расположение SM могут давать существенные различия между картами.
Заключение
Blackwell даёт богатый набор новых инструментов: TMEM, 2SM MMA, мощный TMA и развитые кластерные механики. Но аппаратные лимиты (SMEM-полоса, L2, die-to-die latency и кластерная квантованность) определяют, какие паттерны будут работать лучше. Практическая работа с PTX/SASS и микробенчмарки по-прежнему необходимы, чтобы получить близкую к пику производительность в реальных ML-ядрах.