
Эволюция систем управления химическими процессами и переход к парадигме индустриального искусственного интеллекта (Индустрия 4.0) знаменуют фундаментальный сдвиг в научно-исследовательской и производственной практике нефтехимической отрасли. Химическая промышленность традиционно является одной из самых сложных областей для автоматизации и строгого математического моделирования. Современные промышленные химические реакторы и колонны ректификации представляют собой многокомпонентные, многофазные термодинамические системы, которые характеризуются высокой степенью математической нелинейности, распределенностью параметров тепло- и массопереноса, а также нестационарной кинетикой реакций. На протяжении последних десятилетий основу промышленной автоматизации составляли классические системы усовершенствованного управления процессами (Advanced Process Control, APC) и многосвязного модельно-упреждающего управления (Model Predictive Control, MPC). Однако эти детерминированные подходы, базирующиеся на линеаризованных физико-химических моделях (first-principles models) или традиционных эвристических алгоритмах, обладают критическими фундаментальными ограничениями. Одной из наиболее острых проблем является неспособность традиционных математических моделей точно описывать стохастические и кумулятивные деградационные процессы, такие как долгосрочная деактивация промышленного катализатора, спекание активных центров или образование углеродистых отложений.
Стремительное развитие архитектур трансформеров и генеративных больших языковых моделей (Large Language Models, LLM) открыло принципиально новые горизонты для проектирования интеллектуальных цифровых двойников (Digital Twins) и систем предиктивного управления в химической отрасли. Изначально созданные для обработки естественного человеческого языка, современные доменно-специфичные языковые модели продемонстрировали беспрецедентную способность извлекать сложные нелинейные паттерны, термодинамические ограничения и скрытые марковские зависимости из любых последовательностей данных, включая многомерные временные ряды с заводских датчиков и строковые представления молекул. Интеграция обширных массивов исторических производственных данных, журналов технического обслуживания, строгих термодинамических симуляций (с использованием программных комплексов Aspen Plus и AVEVA Process Simulation) и когнитивных способностей LLM позволяет создать качественно новый класс автономных систем управления и масштабирования НИОКР.
Настоящее исследование представляет исчерпывающий, детализированный анализ применения передовых архитектур генеративного искусственного интеллекта в нефтехимическом секторе. В отчете подробно разбираются функциональные особенности мультимодальных моделей органического синтеза (ChemReactLLM и ReactionReasoner), исследуются практические кейсы внедрения алгоритмов в инженерные процессы и разработку полимеров, анализируются конвейеры обучения локальных LLM на симуляционных данных Aspen Plus, а также проводится системный анализ ключевых патентов и научных публикаций, определяющих актуальный технологический ландшафт химической индустрии.
Детальный разбор функциональности специализированных химических моделей: ChemReactLLM и ReactionReasoner
Применение общих языковых моделей (таких как базовые версии ChatGPT, Claude или открытые модели широкого профиля) для решения специфических химических задач сопряжено с фундаментальными концептуальными трудностями. Базовые архитектуры рассматривают линейные строковые представления химических молекул, такие как SMILES (Simplified Molecular-Input Line-Entry System) или SELFIES, исключительно как неструктурированный текст. В результате происходит безвозвратная потеря критически важной топологической, пространственной и квантово-химической информации. Более того, при генерации химических реакций общие LLM склонны к так называемым «химическим галлюцинациям»: они могут создавать новые атомы из вакуума, нарушать фундаментальные законы сохранения массы, игнорировать законы сохранения заряда и генерировать термодинамически невозможные интермедиаты, что делает их предсказания непригодными для промышленного синтеза. Для преодоления этих структурных ограничений исследовательские центры разработали специализированные химические архитектуры, внедряющие строгую химическую логику и физические ограничения непосредственно во внутренние тензорные механизмы обработки данных. Наиболее передовыми представителями этого класса являются модели ChemReactLLM и ReactionReasoner, которые используют кардинально различающиеся, но взаимодополняющие математические подходы к пониманию химии.
Мультимодальный химический оракул: Архитектура и механика инференса ChemReactLLM
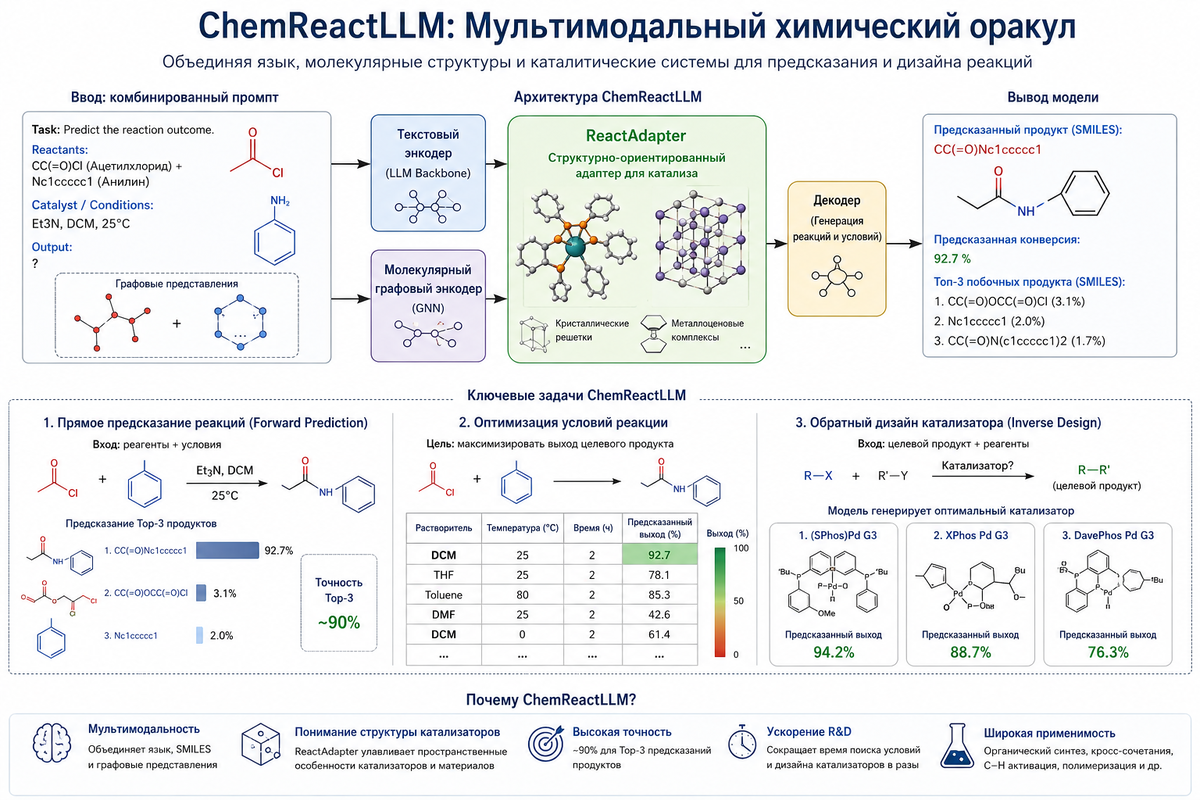
Эффективность органического синтеза и промышленной нефтехимии во многом определяется точностью выбора и оптимизации каталитических комплексов, что исторически требовало колоссальных временных и финансовых затрат на эмпирический скрининг. Модель ChemReactLLM была специально спроектирована как мультимодальная архитектура для прогнозирования результатов реакций, управляемых катализаторами, и глубокой многомерной оптимизации условий синтеза. Главная отличительная черта данной модели — элегантное решение проблемы «слепоты» стандартных трансформеров к трехмерной структуре сложных молекул посредством бесшовной интеграции графовых нейронных сетей (GNN) и методов квантовой химии, в частности, теории функционала плотности (Density Functional Theory, DFT).
Технологическим ядром ChemReactLLM выступает специализированный вычислительный модуль, получивший название ReactAdapter. Его задача заключается в формировании обогащенного векторного представления (эмбеддинга) химической структуры. Если на вход поступают простые органические молекулы или базовые реагенты (представленные в каноническом формате SMILES), ReactAdapter использует архитектуру GNN для извлечения топологических признаков, кодируя информацию об атомах и типах связей в вектор фиксированной размерности. Однако для сложных каталитических комплексов (таких как металлоцены, используемые в полимеризации олефинов, или переходные металлы с массивными лигандами), где решающую роль в каталитической активности играют тонкие пространственные взаимодействия, стерические препятствия и геометрия координационных связей, стандартных графов недостаточно. В этом сценарии ReactAdapter запускает квантово-механический конвейер обработки. Модуль анализирует трехмерные атомарные координаты, дистанционные графы и интегрирует высокоточные квантово-химические дескрипторы, рассчитанные методами DFT. К числу таких дескрипторов относятся точные уровни энергии высших занятых и низших свободных молекулярных орбиталей (HOMO и LUMO), локальное распределение спиновой плотности и флуктуации длин связей. Эти микроскопические физико-химические параметры конкатенируются с графовыми эмбеддингами, наделяя языковую модель глубоким квантовым «зрением».
Связывание полученных высокоразмерных физических эмбеддингов с текстовой информацией, описывающей условия проведения реакции, осуществляется через инновационный блок перекрестного внимания (Text-Structure Cross-Attention Block). Этот механизм заставляет фундаментальную языковую модель сопоставлять экспериментальные условия, заданные естественным языком (температурный профиль, давление, диэлектрическая проницаемость растворителя, молярные соотношения), со специфическими структурными свойствами молекул.
Взаимодействие инженера-исследователя с ChemReactLLM строится через комбинированные гибридные промпты, смешивающие английский язык и строковые нотации. Классический пример инференса для прямого предсказания продукта (Forward Prediction) выглядит следующим образом: исследователь задает задачу «Predict the reaction outcome», указывает реагенты в формате SMILES, например, CC(=O)Cl (ацетилхлорид) и Nc1ccccc1 (анилин), а также прописывает условия среды — Et3N, DCM, 25°C. Опираясь на мультимодальные графовые веса, модель генерирует SMILES целевого продукта — CC(=O)Nc1ccccc1 (ацетанилид) и предсказывает процент конверсии. Точность предсказания Top-3 продуктов в подобных задачах достигает феноменальных 90%.
Помимо прямого предсказания реакций и подбора растворителей, наиболее востребованной функцией ChemReactLLM в нефтехимических R&D-центрах является обратный дизайн катализатора (Inverse Catalyst Design). В рамках этой задачи технолог задает целевой выходной продукт и доступное экономичное сырье, поручая модели сгенерировать оптимальную структуру каталитического комплекса. Модель может спроектировать уникальный фосфиновый лиганд для реакций кросс-сочетания, максимизирующий выход за счет точного расчета стерического экранирования побочных реакций, что радикально сокращает цикл эмпирических лабораторных испытаний.
ReactionReasoner: Имитация пошагового логического вывода и анализ механизмов
В то время как архитектура ChemReactLLM функционирует как детерминированный мультимодальный оракул, выдающий точный конечный ответ на базе квантовых дескрипторов, модель ReactionReasoner реализует совершенно иную парадигму. Она спроектирована для имитации глубокого когнитивного мышления опытного химика-органика путем внедрения строгого механизма пошагового логического вывода (Chain-of-Thought, CoT). Прогнозирование химических реакций, определение путей ретросинтеза и расследование механизмов электронных перемещений требуют явного когнитивного рассуждения: распознавания активных функциональных групп, оценки их химической совместимости и детального анализа нуклеофильных или электрофильных атак.
Обучение ReactionReasoner базируется на инновационной методологии масштабной генерации данных под названием SyntheticReact. Эта система использует алгоритмы веб-скрейпинга для агрегации массивов научной документации и патентов по органической химии из открытых источников. Принимая на вход строковые представления реакций (RXN SMILES), система извлекает специфическую информацию о стратегиях, эвристиках и логических правилах, применяемых авторами-исследователями. Затем мощная модель-учитель структурирует этот сырой текст в формализованные обучающие датасеты, представляющие собой подробные цепочки рассуждений.
Сам процесс адаптации ReactionReasoner представляет собой сложный двухэтапный конвейер. На первом этапе применяется контролируемое дообучение (Supervised Fine-Tuning, SFT), в ходе которого веса нейросети корректируются исключительно на высококачественных данных пошаговых рассуждений, сгенерированных SyntheticReact. На втором этапе внедряется критически важный механизм самообучения через рефлексию (self-bootstrapping). В рамках этого метода те цепочки рассуждений модели, которые приводят к правильному предсказанию конечного продукта химической реакции, используются для дополнительного усиления весов (положительное подкрепление). Если же модель допускает логическую ошибку в рассуждениях, приводящую к неверному структурному прогнозу, эти неудачные итерации не удаляются. Они направляются в специальный модуль для генерации «данных рефлексии» (reflection data), где детально анализируется и фиксируется конкретная логическая ошибка. Модель учится на собственном опыте понимать, что она, например, не учла конкурирующую побочную реакцию, проигнорировала стерическое препятствие объемной метильной группы или неверно оценила константу скорости нуклеофильного замещения.
Практическое взаимодействие с ReactionReasoner строится в формате диалога. От модели требуется не просто сгенерировать SMILES формулу продукта, а пошагово расписать процесс разрыва и образования ковалентных связей. Типичный исследовательский промпт может звучать так: «Explain the reaction mechanism between 1,3-butadiene and maleic anhydride. Why does this reaction occur at room temperature without a catalyst? Detail the transition state». В ответ модель генерирует подробное текстовое описание классической реакции Дильса-Альдера. Она объясняет концепцию согласованного перициклического механизма, описывает фазовое перекрывание HOMO и LUMO орбиталей диена и диенофила, объясняет термодинамическую движущую силу процесса и рисует с помощью текстовых символов или специализированных нотаций геометрию циклического переходного состояния.
Такой подход решает несколько критически важных задач в нефтехимии. Во-первых, модель осуществляет вывод механизмов (Mechanistic Pathway Generation), что необходимо при подаче патентных заявок на новые способы синтеза, где требуется теоретическое обоснование маршрута. Во-вторых, она проводит глубокий анализ селективности, объясняя причины, по которым реакция протекает по орто-положению, а не по пара-положению (например, из-за блокировки позиции массивной группой). В-третьих, ReactionReasoner является незаменимым инструментом траблшутинга (troubleshooting). Если на реальном производстве или в лаборатории эксперимент дал низкий выход целевого продукта или привел к образованию полимерной «смолы», химик-технолог загружает в модель фактические условия. Модель, опираясь на выученные термодинамические законы, анализирует ситуацию и подсказывает, какая именно кинетически более выгодная побочная реакция вступила в конкуренцию с основной, предлагая пути ее подавления. Эмпирические исследования убедительно доказывают, что подобное медленное логическое рассуждение, имитирующее последовательную логику человека-химика, приносит экспоненциально больше пользы для точности модели, чем попытки предсказать конечный результат напрямую.
Применение LLM в НИОКР и инженерных процессах: Кейсы и задачи масштабирования
Внедрение больших языковых моделей переводит нефтехимическую индустрию от устаревшей парадигмы эмпирического тестирования и длительных лабораторных проб к концепции высокопроизводительного, математически обоснованного молекулярного дизайна «по требованию». Интеграция когнитивных ИИ-агентов охватывает всю производственную цепочку предприятия: от фундаментальных исследований на молекулярном уровне до проектирования аппаратных схем и непрерывного предиктивного мониторинга многотоннажных реакторов в реальном времени.
Трансформация R&D: Автономные лаборатории (Self-Driving Labs) и дизайн катализаторов
Разработка и внедрение новых промышленных гетерогенных катализаторов исторически представляли собой линейный, эмпирический процесс. Открытие новой каталитической системы для процессов диспропорционирования, крекинга или полимеризации, ее лабораторное тестирование, пилотное масштабирование и внедрение в полномасштабное производство могло занимать до десятилетия. Сегодня мультимодальные LLM выступают в роли интеллектуального ядра так называемых Автономных лабораторий (Self-Driving Labs, SDL) — роботизированных платформ, где алгоритмы ИИ синхронизированы с автоматизированным высокопроизводительным экспериментированием (High-Throughput Experimentation, HTE).
Ведущие корпорации и исследовательские консорциумы активно развертывают подобные интегрированные системы для сокращения цикла разработки до нескольких месяцев. Процесс начинается с того, что химик формулирует высокоуровневую гипотезу или цель на естественном языке. Языковая модель анализирует запрос и обращается к встроенным машинно-изученным межатомным потенциалам (Machine-Learned Interatomic Potentials, MLIPs). Эти потенциалы, предварительно обученные на массивах квантово-механических расчетов (таких как базы данных Open Catalyst Project), позволяют LLM предсказывать энергии адсорбции реакционных интермедиатов на различных гранях кристаллических решеток кандидатов. После молниеносного вычислительного скрининга тысяч возможных структур LLM автоматически компилирует исполняемые машинные скрипты для аппаратной роботизированной платформы. Платформа самостоятельно дозирует реагенты микролитровыми шприцами, загружает миллиграммовые навески катализаторов в параллельные микрореакторы, проводит синтез при заданных градиентах давления и температуры, а затем непрерывно транслирует хроматографические и спектроскопические данные обратно в нейросеть. На основе полученных результатов LLM использует алгоритмы активного обучения (active learning) для байесовской оптимизации следующей серии опытов, непрерывно сходясь к идеальной химической рецептуре.
Инновации в макромолекулярной инженерии: Фреймворк Polymer-Agent
Производство современных полимерных композитов требует от инженеров управления беспрецедентно огромным параметрическим пространством, которое охватывает архитектуру макромолекулярных цепей, композиционную полидисперсность, случайность последовательностей мономерных звеньев и сложную многоуровневую морфологию. Внедрение доменно-специфичных ИИ переводит отрасль к концепции молекулярного дизайна под заданные физико-механические характеристики. Инновационный фреймворк Polymer-Agent демонстрирует способность выступать в роли когнитивного замыкающего контура.
Исследователь, работающий над созданием нового продукта, может обратиться к Polymer-Agent с комплексным запросом на разработку изоляционного полимерного материала, обладающего строго определенной диэлектрической проницаемостью, шириной запрещенной зоны и высоким модулем упругости. В ответ модель использует латентные пространства, выученные на базах данных макромолекул, для генерации SMILES-нотаций потенциальных сополимеров. Критическим инженерным фильтром этого фреймворка является мгновенная оценка синтетической доступности (Synthetic Accessibility Score, SA Score) и сложности масштабирования (Synthetic Complexity Score, SC Score). Модель отсеивает теоретически идеальные, но коммерчески нежизнеспособные экзотические структуры, генерируя полимеры, структурно близкие к синтезируемым на существующих заводах (например, с высокой метрикой подобия Танимото к промышленному Нейлону-6). Более того, применяя знания кинетики деградации, усвоенные на простых ациклических алканах (база из 32 000 молекул), дообученные LLM способны экстраполировать механизмы термического расщепления (радикального разрыва связей) на сложные полимерные матрицы, безошибочно прогнозируя стабильность и срок службы конечных пластиковых изделий без дорогостоящих долгосрочных климатических испытаний.
Автоматизация инженерного проектирования: Архитектура AutoChemSchematic AI
После успешного синтеза молекулы в лаборатории начинается самый капиталоемкий этап — масштабирование процесса (Scale-up) до уровня промышленного предприятия. Традиционно это требует месяцев работы целых отделов инженеров-проектировщиков для создания технологических схем (Process Flow Diagrams, PFD) и детализированных схем трубопроводов и КИПиА (Piping and Instrumentation Diagrams, PID). Мощный прорыв в этой области обеспечил агентный фреймворк AutoChemSchematic AI, реализующий физически-осведомленную автоматизацию замкнутого цикла (closed-loop, physics-aware automation).
Архитектура AutoChemSchematic AI решает задачу преодоления "synthesis gap", интегрируя генеративный ИИ со строгими физическими законами. Система опирается на иерархический граф знаний (Hierarchical Knowledge Graph), содержащий глубокие семантические описания технологических потоков, оборудования и контрольно-измерительной аппаратуры для более чем 1020 химических веществ. Обучение доменно-специфичных малых языковых моделей (Small Language Models, SLM) в рамках этого фреймворка осуществляется через многоступенчатый конвейер, включающий контролируемое дообучение (SFT), оптимизацию прямых предпочтений (DPO) и поисковое инструктивное дообучение на основе графов (Graph Retrieval-Augmented Generation, GRAG).
Самой важной инновацией AutoChemSchematic AI является валидация топологии в замкнутом цикле с помощью интеграции симулятора с открытым исходным кодом DWSIM (simulator-in-the-loop). Когда языковая модель генерирует проект схемы (например, последовательность сепараторов, теплообменников и реакторов с контурами рециркуляции), эта схема автоматически загружается в симулятор. DWSIM решает системы дифференциальных уравнений, проверяя соблюдение законов сохранения массы и энергии. Если модель допускает ошибку — предлагает термодинамически невозможный фазовый переход или создает неразрешимый контур рециркуляции — симулятор возвращает математический отказ. SLM-агент анализирует логи симулятора, выявляет нарушенные инженерные ограничения и итеративно корректирует схему PFD/PID до тех пор, пока процесс не станет абсолютно реализуемым в реальности. Это беспрецедентно сокращает циклы проектирования от месяцев до часов, гарантируя промышленную осуществимость предложенных ИИ дизайнов.
Предиктивный мониторинг оборудования и прогнозирование жизненного цикла (RUL)
На операционном уровне управления действующим предприятием большие языковые модели интегрируются со SCADA-системами в качестве высокоуровневых аналитиков для предиктивного мониторинга. Деактивация каталитических слоев в промышленных реакторах представляет собой фундаментально нелинейный макроскопический процесс, который начинается с микроскопических отклонений и характеризуется длительным индукционным периодом видимой стабильности, за которым следует катастрофическое падение конверсии.
LLM, агрегируя многомерные числовые временные ряды с датчиков (термопары, расходомеры, датчики перепада давления) и неструктурированные текстовые журналы операторов, выступают в роли интеллектуальных виртуальных анализаторов (soft sensors). Они способны выявлять тончайшие физико-химические маршруты деградации, недоступные классическим ПИД-регуляторам:
- Спекание (Sintering) и агломерация: Термически индуцированное слияние наночастиц активного металла, приводящее к потере площади поверхности. Изменения происходят крайне медленно, однако LLM выявляет этот процесс путем сложной кросс-корреляции: постепенного смещения профиля экзотермического тепловыделения по длине слоя трубчатого реактора в сочетании с монотонным снижением перепада давления газа.
- Закоксовывание (Coking): Отложение поликонденсированных углеродистых структур, блокирующих мезопоры носителя катализатора. Интегрируясь с базами данных (такими как Open Catalyst Dataset), LLM в реальном времени оценивает энергии адсорбции интермедиатов сырья. Если при текущем температурном режиме энергия адсорбции становится слишком сильной и десорбция продукта затрудняется, ИИ прогнозирует экспоненциальный рост коксообразования.
- Отравление хемосорбцией (Poisoning): Взаимодействуя с Лабораторными информационными менеджмент-системами (ЛИМС), языковая модель сопоставляет профили поточных газовых хроматографов с текстами сертификатов качества поступающего сырья, содержащего гетероатомы (серу, мышьяк, тяжелые металлы), прогнозируя скорость необратимой потери активности активных центров.
В результате анализа LLM не просто констатирует факт износа, а синтезирует аргументированные рекомендации: «Экстраполируя текущий тренд температурных флуктуаций и данные ЛИМС о повышении тяжелых фракций, прогнозируется рост коксования через 14 дней. Рекомендуется превентивно увеличить молярное отношение водорода к углеводородам на 15% и снизить температуру подачи на 2.5°C. Это снизит текущий выход целевого продукта на 1.2%, но предотвратит внеплановый останов и продлит ресурс катализатора на 40 суток». Подобная глобальная мультифакторная балансировка OPEX и CAPEX переводит химические установки в режим превентивного самосохранения. Для локальных реакционных установок, например электрических каталитических блоков диссоциации аммиака на транспортных средствах, предиктивное управление на базе LLM позволяет прогнозировать профили энергопотребления с учетом макро-факторов (погода, трафик, поведение водителя) и использовать стратегию последовательного (инкрементального) включения нагревательных элементов, полностью исключая фатальный термический шок для дорогостоящих рутениевых катализаторов.
Обучение LLM на данных Aspen Plus: Индустриальная реализация и суррогатное моделирование
Экономическая целесообразность и соображения коммерческой тайны (защита уникальных рецептур полимеров и кинетических констант) не позволяют транснациональным корпорациям передавать данные с датчиков на сервера облачных провайдеров (таких как OpenAI). Стратегическим императивом является развертывание кастомизированных локальных моделей (на базе архитектур с открытыми весами, таких как Qwen-2.5, Mistral-Nemo или Gemma) внутри защищенного корпоративного контура. Однако неструктурированное дообучение таких моделей на случайных химических текстах приводит к катастрофическому падению точности. Фундаментальным прорывом в индустриальном ИИ стала методология использования строгих детерминированных технологических симуляторов, таких как Aspen Plus, Aspen Polymers и AVEVA Process Simulation, для масштабной генерации синтетических обучающих данных и создания так называемых суррогатных моделей.
Теория и практика суррогатного моделирования с помощью Aspen
Коммерческие симуляторы (Aspen HYSYS, Aspen Plus) используют последовательно-модульные (Sequential Modular) или ориентированные на уравнения (Equation-Oriented) методы для решения гигантских систем нелинейных дифференциальных уравнений, описывающих гидродинамику, тепломассоперенос, кинетику и фазовые равновесия. Хотя эти решатели обеспечивают абсолютную физическую точность, их работа требует значительных вычислительных мощностей. Классический расчет профиля многозонного реактора в Aspen Polymers с учетом сложной кинетики Циглера-Натта и многомерных матриц молекулярно-массового распределения может занимать десятки минут. Концепция суррогатного моделирования заключается в том, чтобы заставить нейронную сеть (LLM) аппроксимировать скрытую многомерную статистическую матрицу физического процесса, выучив термодинамические закономерности. Обученная суррогатная LLM, получив на вход параметры процесса, способна выдать высокоточный результат (например, индекс расплава полимера или тепловой баланс) за миллисекунды, допуская минимальную погрешность аппроксимации (в пределах 2-4%), что критически важно для систем управления в реальном времени (Real-Time Optimization).
Масштабная генерация высокоточных обучающих данных, неукоснительно соблюдающих фундаментальные законы сохранения массы и энергии, осуществляется путем перевода Aspen Plus из среды с графическим интерфейсом в программно управляемую вычислительную инфраструктуру. Этот мост реализуется через Python API и взаимодействие с компонентной объектной моделью Microsoft (COM-объекты). Скрипты на языке Python (с использованием библиотек win32com.client или специализированных оберток, таких как AspenPlus-Python-Interface) перехватывают управление ядром симулятора в фоновом режиме. Алгоритм программно загружает файл симуляции (.bkp), навигирует по дереву переменных (Variable Explorer), обращается к потокам и аппаратным блокам (Radfrac, CSTR, RPlug, Flash2) и итеративно изменяет управляющие параметры (температуры, давления, расходы катализаторов, флегмовые числа). Применяя алгоритмы выборки Монте-Карло, система может автономно запустить миллионы расчетных сценариев, варьируя входные параметры в заданных технологических окнах. Каждая успешная сходимость решателя сохраняется, формируя гигантский табличный массив термодинамически консистентных точек данных (например, 3 миллиона конфигураций производственного процесса альтернативных топлив).
Для того чтобы локальная LLM смогла усвоить этот массив, табличные данные подвергаются трансформации в формат диалоговых инструкций (Instruction Fine-Tuning). Сырые матрицы преобразуются в текстовые пары "Вопрос-Ответ". Системное сообщение формирует контекст эксперта-инженера. В теле промпта задаются условия: «Determine the molecular weight distribution, polydispersity index, and catalytic yield for propylene polymerization under the following CSTR conditions: Pressure 30 bar, Temperature 70°C, Residence time 2 hours...». Ожидаемый ответ заполняется точными значениями, вычисленными решателем Aspen: «Under the specified conditions... monomer conversion approaches 92%, number-average molecular weight is [значение] g/mol...».
Сам процесс дообучения огромных моделей на 14–70 миллиардов параметров оптимизируется за счет применения методов Parameter-Efficient Fine-Tuning (PEFT). Доминирующим стандартом является алгоритм QLoRA (Quantized Low-Rank Adaptation). Фундаментальная языковая модель квантуется до 4-битной точности с заморозкой основных весов, а градиентному обновлению подвергаются лишь небольшие низкоранговые матрицы-адаптеры, "прививающие" модели понимание нелинейной кинетики. Использование библиотек с оптимизированными ядрами вычислений (таких как Unsloth) позволяет осуществлять процесс дообучения на одиночных графических ускорителях корпоративного класса (NVIDIA A100), кардинально снижая финансовые затраты R&D отделов.
В процессе работы с непрерывными физическими и химическими данными возникает фундаментальная алгоритмическая преграда, известная как проблема математической нечувствительности токенизаторов (Lack of Numeracy). Стандартные алгоритмы кодирования текста (такие как Byte-Pair Encoding) разбивают многозначные числа с плавающей точкой (например, профиль температур с датчиков) на произвольные семантически не связанные подстроки, уничтожая метрическое пространство числовых значений. Точно так же стандартный токенизатор бессмысленно дробит строковые формулы SMILES, игнорируя химические связи и циклические структуры. В нефтехимии эта проблема решается комплексно: для молекулярных структур формат SMILES заменяется на математически гарантированный формат SELFIES, а также внедряются графы переходов токенов (Token Transition Graph, TTG), выявляющие химически когерентные подстроки (например, бензольные кольца). Для временных рядов с физических датчиков применяются запатентованные алгоритмы символьного разбиения (Sensor-to-Grammar Symbolization), которые делят ряд на окна и транслируют специфические паттерны температурных флуктуаций в абстрактные дискретные грамматические символы, понятные механизмам внимания (attention) трансформеров. Наконец, для искоренения концептуальных физических ошибок применяется парадигма обучения с подкреплением на основе проверяемых вознаграждений (RLVR). Вместо субъективной человеческой оценки LLM получает положительный скалярный сигнал (reward) только в том случае, если предложенные ею режимные параметры, будучи пропущенными через независимый симулятор Aspen, приводят к успешному и стабильному протеканию химического процесса без нарушения тепловых балансов.
Автономная оркестрация через Model Context Protocol (MCP)
Параллельно с суррогатным дообучением, в 2026 году произошел кардинальный прорыв в прямом программном управлении сложным ПО со стороны ИИ. Архитектура интеграции обогатилась открытым стандартом Model Context Protocol (MCP). Этот протокол превращает монолитные пакеты программ, такие как Aspen Plus и AVEVA Process Simulation, в стандартизированные серверы инструментов (tool-calling endpoints), с которыми LLM-агент (например, Claude Desktop) может взаимодействовать автономно в режиме реального времени.
MCP-сервер выступает абстрактной промежуточной прослойкой (intermediary layer). Используя Python-фреймворки (подобные FastMCP), сервер транслирует высокоуровневые API симулятора в четко определенный для языковой модели набор инструментов (tools). Агент получает возможность программно считывать топологию схемы (flowsheet), создавать и удалять блоки оборудования (Mixer, Heater, Radfrac), запрашивать термодинамические свойства потоков и инициировать запуск расчетного ядра (solver execution).
Внедрение MCP-протокола переводит LLM из статуса пассивного суррогата в статус активного когнитивного инженера. Как показывают эмпирические исследования по ректификации метанола и воды, агент, оснащенный MCP-доступом к AVEVA Process Simulation, способен действовать в двух режимах. В режиме одиночного промпта (single-prompt mode) эксперт формулирует задачу, и LLM-агент самостоятельно генерирует Python-код для сборки базовой технологической схемы с нуля, устанавливая термодинамические пакеты и подключая контуры. В режиме итеративной оптимизации агент автономно считывает существующий граф потоков, идентифицирует узкие места процесса (debottlenecking) и осуществляет многократные запуски решателя, подбирая оптимальное флегмовое число. В одном из задокументированных кейсов агент без вмешательства оператора смог повысить чистоту извлекаемого дистиллята с 84.2% до 95.1 mol%, после чего экстрагировал массивы данных и самостоятельно сформировал аргументированный технический отчет с графиками распределения концентраций по тарелкам колонны. Несмотря на то, что текущие системы еще могут допускать незначительные фактологические сбои и требуют надзора (expert oversight), фреймворк MCP-интеграции радикально снижает барьер входа для молодых инженеров и бесконечно ускоряет рутинные процедуры проектирования.
Этот функционал подробно разбирал на канале в телеграмм и teletype
Анализ ключевых патентов и исследований: Формирование технологического ландшафта
Комплексный анализ патентных пулов крупнейших транснациональных корпораций и новейших академических публикаций (2024-2026 гг.) позволяет проследить переход генеративного ИИ в химии от стадии концептуального подтверждения (Proof-of-Concept) к агрессивной индустриальной коммерциализации. Происходит четкое разделение фокусов: фундаментальные исследовательские институты решают математические проблемы репрезентации молекул и логического вывода, в то время как корпоративный сектор монополизирует права на интерфейсы интеграции LLM с физическим оборудованием и SCADA-системами.
Для формирования полного понимания ландшафта в таблице и последующем текстовом блоке систематизированы и детально проанализированы 11 наиболее значимых, прорывных патентов и научных исследований, определяющих вектор развития отрасли.
Помимо патентной активности, фундаментальный теоретический базис для новых технологий закладывают масштабные исследования последних лет. Детальный разбор 5 ключевых научных публикаций раскрывает эволюцию математических алгоритмов:
1. Исследование ChemReactLLM: Мультимодальная парадигма (Mou & Lou, 2025).
Данная работа произвела революцию в предиктивном органическом синтезе, доказав, что языкового описания молекул катастрофически недостаточно для моделирования сложного гетерогенного катализа. Интегрировав графовые нейронные сети с высокоточными дескрипторами теории функционала плотности (DFT) через механизмы перекрестного внимания, авторы научили модель воспринимать геометрию координационных связей и энергии высших занятых и низших свободных орбиталей (HOMO/LUMO). Результаты эмпирических тестов продемонстрировали превосходство ChemReactLLM в задачах прогнозирования абсолютных выходов целевых продуктов и, что более важно, в решении задач обратного дизайна промышленных катализаторов (inverse catalyst design), наделяя систему способностью к надежному обобщению на неизвестные классы реакций.
2. ReactionReasoner: Вывод через пошаговое рассуждение (Ko et al., NeurIPS 2025).
Команда исследователей бросила вызов концептуальной проблеме химической логики в LLM. Они создали систему ReactionReasoner, которая отказалась от прямых предсказаний конечного продукта в пользу имитации когнитивного процесса человека. Сгенерировав колоссальные массивы данных через систему веб-скрейпинга SyntheticReact, авторы применили механизм самообучения через рефлексию (self-bootstrapping). Нейросеть генерирует специализированные данные рефлексии на основе своих собственных неудач (анализируя, почему она проигнорировала стерическое сопротивление или неверно оценила константу скорости), что позволяет ей непрерывно самосовершенствоваться. Доказано, что подробное, пошаговое рассуждение (Chain-of-Thought), объясняющее электронные переносы и структуру переходного состояния, кратно повышает достоверность предсказаний по сравнению с моделями-оракулами.
3. Интеграция LLM-агента с AVEVA Process Simulation через протокол MCP (Liang et al., 2026).
Новейшее исследование, стирающее грань между текстом и промышленным программным обеспечением. Авторы реализовали прямое взаимодействие большой языковой модели с детерминированным коммерческим симулятором процессов AVEVA посредством открытого стандарта Model Context Protocol (MCP) и интерфейсов Python. На примере оптимизации сложной схемы водометанольной ректификации исследователи продемонстрировали, как ИИ-агент автономно анализирует графы технологических потоков, идентифицирует узкие места и циклично запускает расчетное ядро (solver), добиваясь повышения чистоты продукта дистилляции (с 84.2% до 95.1%). Эта работа доказывает практическую реализуемость концепции диалогового инжиниринга, где ИИ-агент выступает равноправным участником мозговых штурмов и автоматизирует рутинный сбор топологий.
4. AutoChemSchematic AI: Агентный фреймворк с физической осведомленностью (Sakhinana, Gupta, Runkana, 2025).
Исследование решает критическую проблему "synthesis gap" — разрыва между открытием новой молекулы в лаборатории и развертыванием ее производства на промышленной площадке. Разработанный фреймворк впервые автоматизировал рутинный и сложный процесс генерации технологических схем (Process Flow Diagrams) и схем трубопроводов (P&ID) с учетом строгих инженерных ограничений. ИИ-агент (опирающийся на графы знаний для 1020+ химикатов) генерирует архитектуру завода, которая мгновенно валидируется в замкнутом цикле через симулятор с открытым исходным кодом DWSIM (simulator-in-the-loop). Детерминированный решатель симулятора выявляет нарушения законов сохранения массы и энергии, заставляя нейросеть итеративно исправлять конфигурацию теплообменников и сепараторов. Этот подход гарантирует индустриальную осуществимость предложенных проектов.
5. Polymer-Agent: Проектирование макромолекул (Nigam et al., 2026).
Ориентируясь на потребности рынка полимерных материалов, исследователи разработали LLM-агента, специализирующегося исключительно на макромолекулярном дизайне. В ответ на текстовый запрос о создании материала с целевыми физико-механическими характеристиками (например, заданной шириной запрещенной зоны или диэлектрической проницаемостью), агент генерирует структуры сополимеров. Важнейшей инновацией стало использование фильтров синтетической доступности (SA Score) и подобия реальным промышленным пластикам (например, полиамидам). Это отсекает экзотические химические графы, позволяя выдавать только те формулы, которые могут быть синтезированы из доступных мономеров с разумными экономическими затратами.
Заключение
Всесторонний и глубокий анализ новейших теоретических достижений, запатентованных индустриальных фреймворков и практических кейсов (2024-2026 гг.) неопровержимо доказывает наступление новой эпохи в нефтехимическом инжиниринге. Большие языковые модели стремительно и бесповоротно эволюционируют от инструментов семантического поиска и генерации текста к статусу мультимодальных когнитивных ядер, способных автономно управлять многомерными физико-химическими пространствами.
Ключевым драйвером этой трансформации стало устранение фундаментальных барьеров архитектуры трансформеров. Обогащение пространства эмбеддингов квантово-механическими дескрипторами (HOMO/LUMO) и механизмами графовых сетей наделило языковые модели (такие как ChemReactLLM) истинным пространственным пониманием стереохимии и каталитических активных центров. В то же время внедрение алгоритмов пошагового вывода (ReactionReasoner, Chain-of-Thought) и саморефлексии обеспечило высокую интерпретируемость предсказаний, снизив уровень концептуальных "химических галлюцинаций" и позволив моделям имитировать когнитивную логику инженера-технолога. Разработанные алгоритмы символьного грамматического кодирования числовых временных рядов (Sensor-to-Grammar Symbolization) окончательно решили проблему математической нечувствительности токенизаторов, открыв LLM путь к глубокому предиктивному анализу "сырых" данных с заводских расходомеров и термопар для прогнозирования оставшегося ресурса (RUL) гетерогенных катализаторов.
Самым стратегически значимым прорывом индустрии стало замыкание технологического цикла через глубокую программную интеграцию языковых моделей с детерминированными термодинамическими симуляторами (Aspen Plus, AVEVA, DWSIM). Использование симуляторов в качестве автоматизированных сред генерации гигантских массивов синтетических данных (через Python и COM-интерфейсы) элегантно решило проблему дефицита структурированной, математически консистентной информации для обучения суррогатных нейронных сетей (QLoRA). Внедрение открытого протокола Model Context Protocol (MCP) превратило монолитное промышленное программное обеспечение в набор инструментов, которыми мультиагентные системы могут оперировать автономно, собирая технологические схемы (как в проекте AutoChemSchematic AI) и проводя многомерную многовариантную оптимизацию режимов ректификации в реальном времени.
Глобальная архитектура АСУ ТП эволюционирует к иерархическим когнитивным системам, где фундаментальные модели выступают в роли высокоуровневых Оркестраторов. Они не заменяют быстродействующие локальные контроллеры, а осуществляют макроскопическое стратегическое руководство: анализируют текстовые журналы аварий, корректируют уставки на основе предиктивного вторичного значения критичности и проактивно модулируют энергопотоки для минимизации термодинамической деградации оборудования. Синергия семантического понимания LLM, строгости цифровых двойников, роботизированных высокопроизводительных лабораторий и алгоритмов обучения с подкреплением выступает абсолютным катализатором перехода мировой химической промышленности к полностью автономным, безотходным производственным объектам (парадигма "lights-out manufacturing"), обладающим беспрецедентной отказоустойчивостью и адаптивностью к рыночным вызовам.