
Мы пытались научить ИИ подбирать мебель по архитектурным чертежам.
Задача выглядит почти идеальной для современных моделей: есть план помещения, есть каталог с сотнями шкафов — просто сопоставь одно с другим.
На практике всё оказалось сильно сложнее.
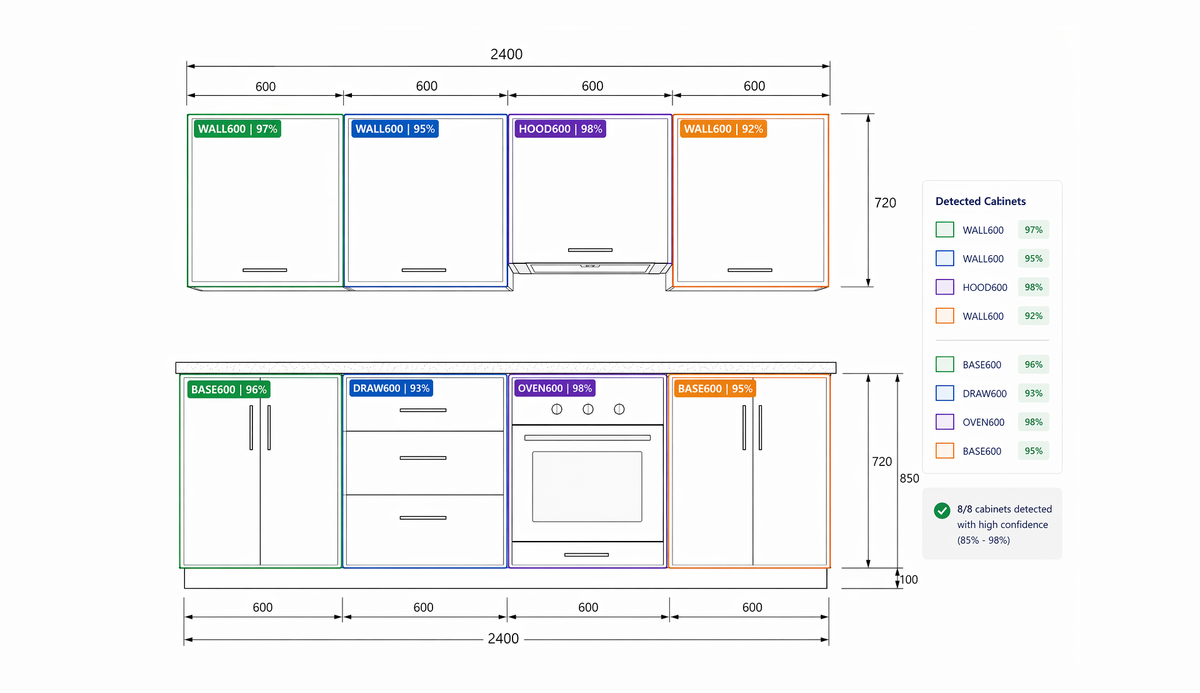
Перед нами был PDF на 30 страниц с архитектурными чертежами. На каждом — кухня, ванная или офис с рядами шкафов. Нужно:
- найти каждый шкаф на чертеже
- определить его тип
- посчитать двери и полки
- извлечь размеры
- и подобрать подходящий вариант из каталога
Сегодня такую работу делают вручную. Люди часами листают каталоги, сверяют размеры и характеристики. На один проект уходит десятки человеко-часов.
Мы решили автоматизировать этот процесс. В итоге у нас получилась система, которая принимает чертежи и каталог, а на выходе даёт рекомендации с точностью 87%.
Но путь к этому результату оказался совсем не таким, как мы ожидали.
Мы думали, что LLM решит всё за один шаг
Первая идея была максимально простой. Зачем строить сложную систему, если можно взять мощную мультимодальную модель и “скормить” ей всё сразу?
Чертёж + каталог → модель → готовый ответ.
Мы начали с Gemini 2.5 Pro — на тот момент она показывала отличные результаты в задачах с изображениями. И на маленьких примерах это даже работало.
Если взять:
- один план
- небольшой каталог (15 страниц)
Модель могла более-менее корректно найти нужный шкаф и дать рекомендацию. Но как только мы попробовали приблизиться к реальности, всё начинало ломаться.
Когда каталог вырос до 120 страниц (примерно 1500 позиций), модель просто перестала справляться. И вскрылись более глубокие проблемы.
Где именно всё ломается
1. Чертежи и каталог – это вообще разные миры
Каталог – это 3D-рендеры. Чертежи – это 2D-схемы.
Для человека это одно и то же, просто разные представления. Для модели – нет.
Она не всегда понимает, что объект на чертеже и объект в каталоге — это один и тот же тип шкафа.
2. Слишком много нюансов, которые нельзя “запихнуть в промпт”
Шкафы бывают разные:
- выдвижные
- навесные
- под раковину
- с полками
- с дверцами
У каждого типа свои правила подбора. Один промпт не может удержать все эти нюансы. Модель начинает путаться.
3. Базовые ошибки, которые нельзя игнорировать
Самое неприятное:
- модель ошибается в подсчёте шкафов
- “придумывает” размеры, то есть галлюцинирует
- путает типы
А именно эти параметры критичны для подбора!
Мы протестировали несколько моделей, результат оказался неожиданным
Мы взяли 20 реальных планов и полный каталог (120 страниц) и протестировали несколько моделей.
Результаты оказались хуже, чем ожидалось:
- Gemini 2.5 Pro – лучше всех работает с изображениями, но ошибается в подсчётах и размерах
- GPT-5 – лучше считает, но почти не умеет подбирать по каталогу
- Grok – что-то среднее, но без явных преимуществ
В цифрах это выглядело так: максимум около 34% точности. То есть ни одна модель даже близко не решала задачу.
Попытка “починить” это через RAG
Мы подумали: может проблема в том, что модель плохо ориентируется в каталоге? Попробовали классический подход – RAG (Retrieval-Augmented Generation):
- разбили каталог на части
- добавили поиск
- улучшили доступ к данным
Качество немного выросло (примерно до 40%), но ключевые проблемы никуда не делись:
- ошибки в подсчётах
- галлюцинации размеров
- путаница в типах
И стало понятно, что дело не в доступе к данным, а в самой природе задачи. В этот момент мы поняли главное – эту задачу нельзя решить одной моделью “в лоб”. Слишком много разных типов логики:
- детекция объектов
- геометрия
- визуальный анализ
- правила предметной области
- поиск по каталогу
Решение было только одно – разбить задачу на отдельные этапы и для каждого использовать свой инструмент.
Это стало переломным моментом проекта.
Мы разделили задачу на 5 частей
После этого система стала выглядеть уже совсем иначе. Теперь вместо “одной умной модели” у нас появился пайплайн из нескольких этапов:
- Найти шкафы на чертеже
- Понять, какие из них одинаковые
- Извлечь размеры
- Описать признаки каждого шкафа
- Найти лучшие совпадения в каталоге
На бумаге всё выглядит просто. Но почти на каждом этапе появились свои неожиданные проблемы.
👉 Про каждую часть мы написали отдельно и подробно в своём блоге.
Что мы поняли после этого проекта
1. LLM пока не умеют всё
Несмотря на весь хайп вокруг мультимодальных моделей, они пока плохо справляются с задачами, где нужно одновременно анализировать изображения, считать объекты, понимать геометрию, искать что-то в большом документе.
2. Предметная область всё ещё важнее “магии AI”
Без правил, фильтров и понимания логики чтения чертежей и каталогов мебели качество было бы намного хуже. Нейросеть не заменяет знание предметной области. Она работает лучше всего именно в комбинации с ним.
3. AI сейчас лучше работает как часть системы
Самый важный вывод для нас – на практике лучше работают не “универсальные AI”, а комбинация специализированных инструментов/моделей.
***
У вас похожая задача с чертежами?
👉 Если у вас похожая задача, давайте посмотрим! Напишите нам и мы найдём для вас решение.