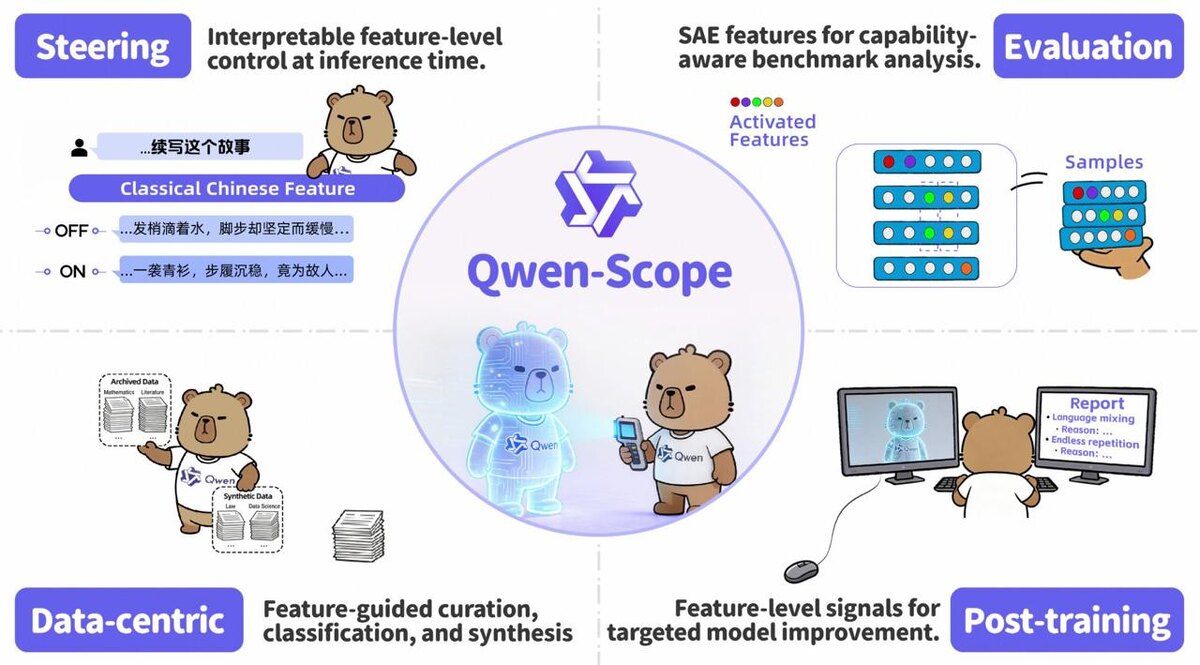
Qwen-Scope - набор sparse autoencoders для Qwen3 и Qwen3.5.
й: SAE помогают разложить внутренние активации модели на понятные человеку «фичи». Не просто миллиарды чисел, а признаки вроде языка, стиля, темы, сущности или повторяющегося паттерна.
Покрытие серьёзное: 14 наборов весов для 7 моделей, от Qwen3-1.7B до Qwen3.5-35B-A3B. Все обучены на 500 млн токенов из претрейна.
Главное, зачем это нужно:
- управлять генерацией без длинных промптов: менять язык, стиль или тему через активацию нужной фичи;
- классифицировать датасеты по нескольким примерам без отдельного классификатора;
- синтезировать данные для редких сценариев эффективнее обычных методов;
- находить фичи, из-за которых модель мешает языки, повторяется или ломает поведение;
- понимать, какие бенчмарки реально проверяют одно и то же.
По сути, это шаг от «уговариваем модель промптом» к прямому вмешательству в её внутренние механизмы.
Anthropic давно делает подобное для Claude, но публичных SAE такого масштаба для открытых LLM почти не было.
Теперь есть - и сразу для Qwen.
🤖 Model: https://modelscope.ai/collections/Qwen/Qwen-Scope
💻 Demo: https://modelscope.ai/studios/Qwen/QwenScope