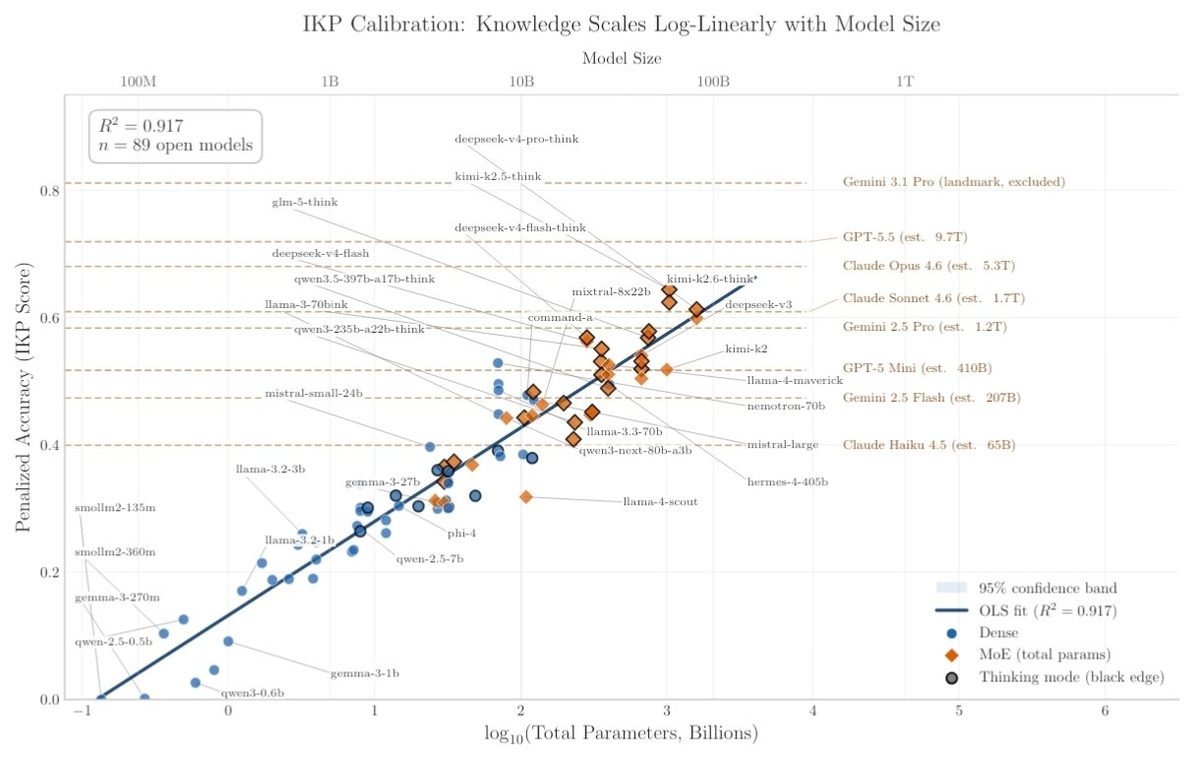
🤖 Китайский исследователь смог посчитать размер ChatGPT, Claude, Gemini и других закрытых моделей
Автор создал специальный бенчмарк, оценивающий кол-во знаний моделей. Он состоит из 1400 фактических вопросов, разбитых на 7 уровней редкости. Всё дело в том, что "интеллект" можно дистиллировать и сжимать в меньшие модели, а фактические знания — нет.
После калибровки на 89 открытых моделях с известным числом параметров выяснилось, что есть явная зависимость результатов бенча от числа параметров. Проецируя закрытые модели на калибровочную кривую, получились следующие результаты:
• GPT-5.5 ≈ 9.7T параметров
• Claude Opus 4.6 ≈ 5.3T
• Claude Sonnet 4.6 ≈ 1.7T
• Gemini 2.5 Pro ≈ 1.2T
Причём это минимальный предположительный размер, т.к. на некоторые вопросы нейронки отказывались отвечать, что напрямую влияло на результат.
Метод всё равно не идеальный, но намного точнее того, что всегда использовали ранее, а именно через "экономику инференса", который даёт погрешность в 2+ раза.
Именно поэтому китайские нейронки хороши исключительно в кодинге, а в остальных аспектах сосут, — интеллекта хватает, а эрудиции — нет. А когда эрудиции не хватает, они начинают брать информацию из веба, но:
а) информации крайне мало (по опыту тянут не более 150 источников, тот же Гемини при веб-поиске индексирует порядка 1000 страниц)
б) качество данной информации сомнительно, т.к. берутся самые популярные сайты, а они сейчас наиболее заполнены тем же нейрослопом.