⚡️ Xiaomi выложила веса семейства MiMo-V2.5
В опубликованном наборе 2 модели с 2 вариантами по контекстному окну каждая - на 256 тыс и 1 млн токенов.
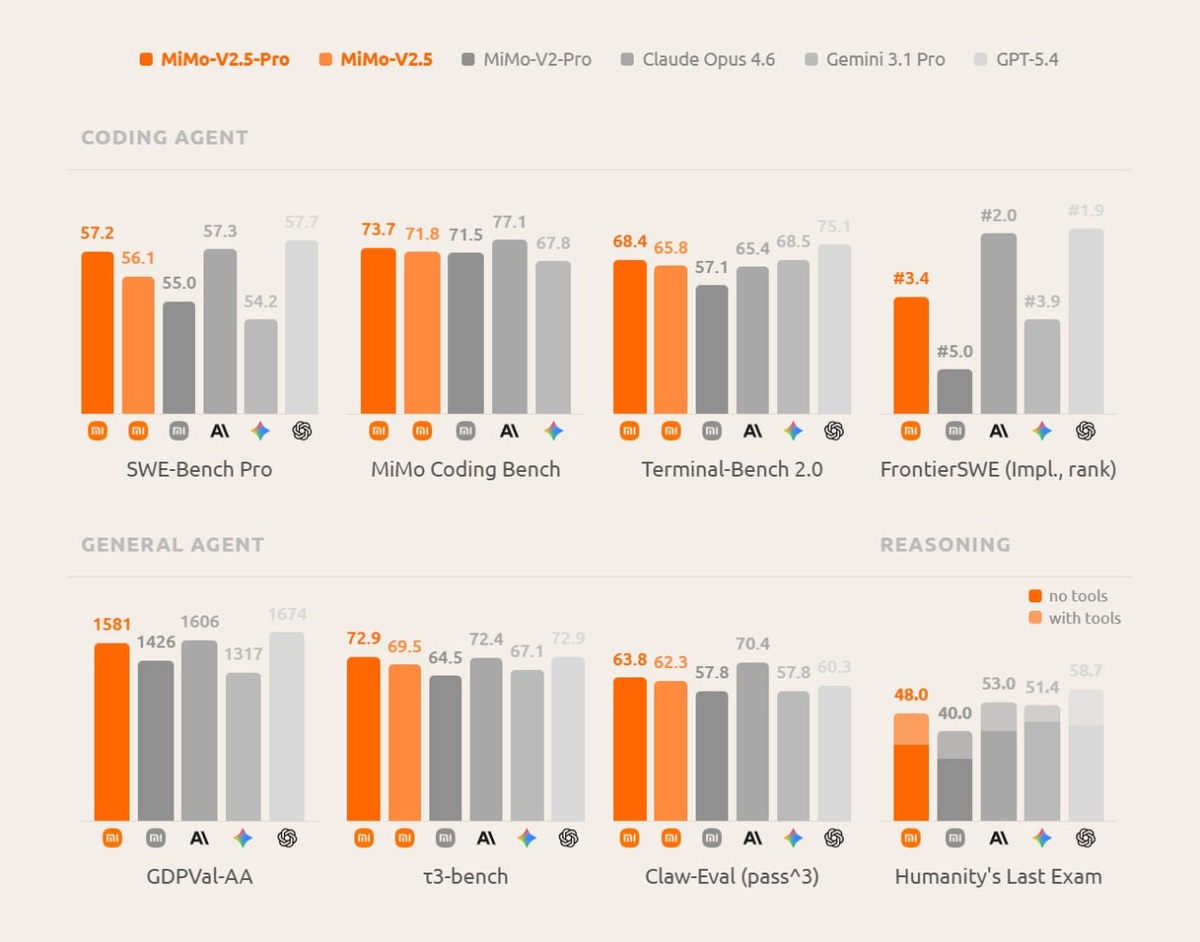
🟢MiMo-V2.5-Pro (1M) и MiMo-V2.5-Pro Base (256K)
MoE на 1,02 трлн параметров (42 млрд активных) c позиционированием для сложных задач в и работы агентов.
В SWE-bench Verified V2.5-Pro набирает 78,9 баллов, при этом в многошаговых задачах она тратит на 40–60% меньше токенов по сравнению с GPT-5.4 или Claude Opus 4.6.
В демонстрации возможностей V2.5-Pro самостоятельно написала рабочий компилятор из SysY в RISC-V: на процесс ушло 4,3 часа и почти 700 вызовов внешних инструментов.
🟠MiMo-V2.5 (1M) и MiMo-V2.5 Base (256K)
Мультимодальная модель на 310 млрд общих и 15 млрд активных параметров c выделенным визуальным (729 млн) и аудиоэнкодером (261 млн), которая понимает текст, изображения, видео и звук.
Обе ветки семейства используют гибридную систему внимания (скользящее окно плюс глобальное) и трехуровневый модуль MTP, который предсказывает сразу несколько токенов.
🟡Вместе с релизом Xiaomi запустила грантовую программу Orbit.
с 27 апреля по 27 мая компания бесплатно распределит между разработчиками и стартапами пул в 100 триллионов токенов.
После аппрува заявки полученные лимиты можно будет подключить к Cursor и Claude Code.
📌Лицензирование: MIT License
🟡Demo
#AI #ML #LLM #MMLM #MiMO #Xiaomi