30 ноября 2022 года OpenAI выпустила в открытый доступ ChatGPT на базе GPT-3.5. За пять дней сервис собрал миллион пользователей, за два месяца уже сто миллионов. Мир, не заметив этого, разделился на "до" и "после".
Писать о российском ИИ в апреле 2026 года задача специфическая. С одной стороны, отрасль вроде есть, модели выпускают, бенчмарки имеются, на конференциях рассказывают про "суверенный ИИ". С другой, открывая диалоговое окно или документацию поле просмотра цифры, возникает стойкое ощущение дежавю: где-то мы это уже видели. Кажется, в тексте про "Союз-5".
Потому начнем с главного. В мире к апрелю 2026 года сформировалась большая тройка моделей: OpenAI (GPT-5.4), Anthropic (Claude Opus 4.7), Google (Gemini 3.1 Pro). Это лидеры, которые тратят сотни миллиардов долларов на инфраструктуру.

Чуть позади - xAI с Grok и DeepSeek с GLM-5.1 от китайской Zhipu. Эта модель, кстати, полностью обучена на китайских чипах Huawei Ascend 910B. Последнее, к слову, важнее самой модели - это первое подтверждение того, что frontier-AI возможно обучать без Nvidia.
OpenAI только за 2025-2026 год выпустила GPT-5, 5.1, 5.2, 5.3, 5.3 Instant, 5.3 Codex, 5.4. Claude за полгода прошел путь от Opus 4.5 до 4.7.
Это тот контекст, на фоне которого имеет смысл обсуждать "российский ИИ".
Основных игроков у нас двое - Яндекс с линейкой YandexGPT и Сбер с GigaChat. Есть T-Bank AI Research, есть VK с их экспериментами, есть MTS AI, есть отдельные исследовательские группы, но говорить о сопоставимом масштабе можно только про первую двойку.
Яндекс. Флагман - YandexGPT 5 Pro (февраль 2025), обновление до 5.1 Pro (середина 2025). Модель обучена на 15 трлн токенов (70% русский, 30% английский), контекст 32 тыс. токенов. Здесь самое интересное - архитектура. По собственному признанию разработчиков, YandexGPT 5 Pro был инициализирован весами Qwen-2.5-32B-base от Alibaba, после чего прошел полный цикл дообучения на русскоязычных данных.
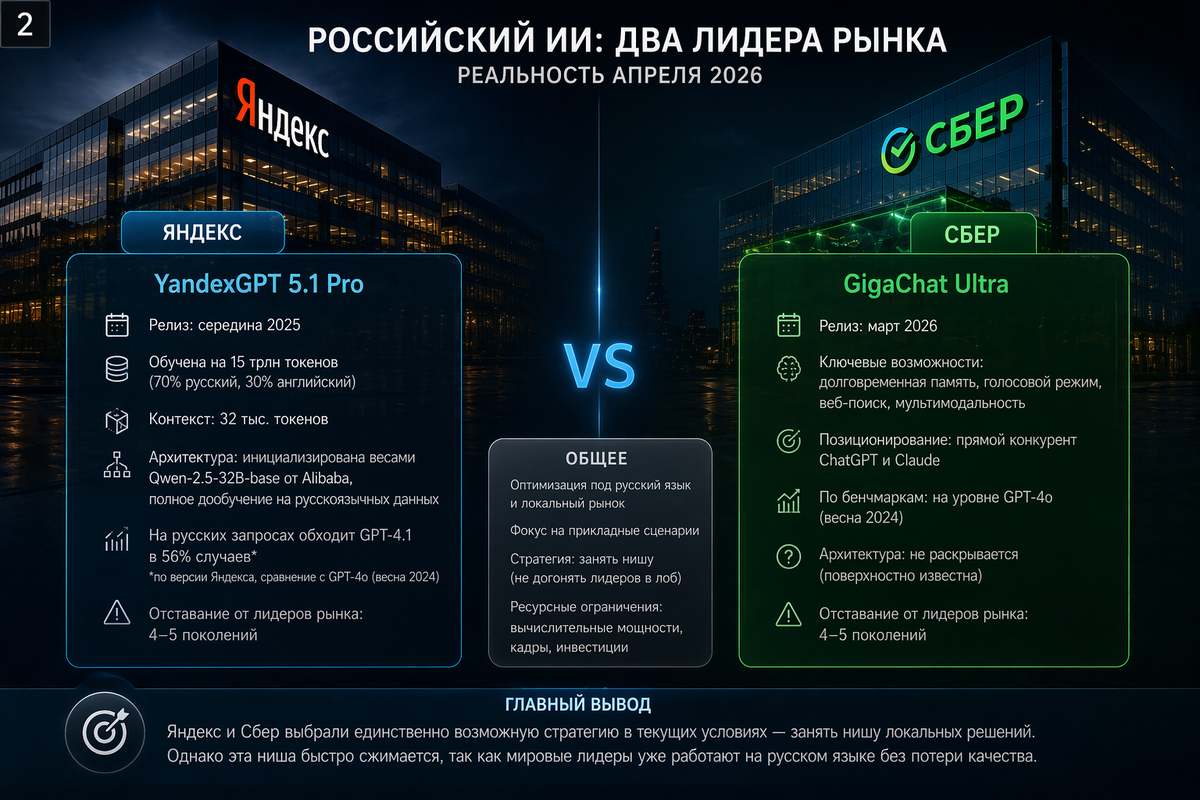
Подход разумный и прагматичный - полный претрейн 32B-модели с нуля стоит сотни миллионов долларов, которых у Яндекса нет. В результате на русскоязычных бенчмарках модель действительно показывает конкурентные цифры. По версии 5.1 Pro - обходит GPT-4.1 в 56% случаев на русских запросах.
Важная оговорка: все это сравнение с GPT-4o, моделью уровня весны 2024 года. На момент выхода YandexGPT 5 Pro в феврале 2025 года лидеры рынка уже были на уровне GPT-o1 и Claude 3.7. К апрелю 2026 между русскими бенчмарками Яндекса и лидерами отрасли - примерно 4-5 поколений разницы. Как мы видим, прорыва и рывка тут не случилось.
Со Сбером все интереснее. Флагман - GigaChat Ultra, который вышел в марте этого года. Последняя модель обзавелась долговременной памятью, голосовым режимом, автономным веб-поиском и в целом позиционируется как прямой конкурент ChatGPT и Claude, но по бенчмаркам все еще на уровне GPT-4o.
С Сбером всегда было сложнее понять, что именно "под капотом". В отличие от Яндекса, который честно признал использование Qwen, Сбер свою архитектурную родословную раскрывает неохотно.
Теперь, что интересно. Яндекс и Сбер выбрали единственно возможную в их обстоятельствах стратегию, не пытаясь догнать, а занять нишу, где у лидеров структурно нет мотивации соревноваться. OpenAI, Anthropic и Google оптимизируют свои модели под английский язык, потому что там их рынок. Российский рынок для них - 2-3% от общего, возиться с русской культурной спецификой им не выгодно.
Проблема одна. Ниша сжимается.
Модели следующего поколения - GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro - уже сейчас работают на русском языке практически без деградации качества.
И здесь возникает правильный вопрос. Три года назад мы писали текст про GPT-3.5 и зубоскалили, что эта игрушка с трудом может написать простенький текст. В 2026 году модели вроде Opus 4.7 и GPT-5.4 уверенно выполняют творческие задачи, ломают уязвимости нулевого дня, проводят военные операции. На базе LLM-моделей строится вся современная разработка. По сути, мы уже вошли в ту фазу, когда ИИ стал конкурентным инструментом, который дает странам, его использующим, радикальное преимущество.
Отечественные модели до этого уровня не доросли, а учитывая ограниченность ресурсов, утечку мозгов и общую риторику запретов и ограничений, вряд ли сумеют выйти в высшую лигу в обозримом будущем.
И вот здесь мы подходим к главному, ради чего этот текст писался. Разговор про "русский ИИ догоняет или не догоняет" относится к разговору про потребительские сервисы. А есть другой, куда менее публичный слой.
ИИ - это ведь не только чат с Алисой. Это системы распознавания целей в военной технике, системы управления беспилотниками, системы обработки данных разведки, системы кибербезопасности и - что критически важно в 2026 году - системы контроля космических аппаратов, ракет и промышленной инфраструктуры. Со всем этим современные LLM-модели либо умеют, либо учатся обращаться.
И бояться есть чего. К концу 2020-х разрыв в ИИ-инфраструктуре станет не количественным, а качественным. Если простым языком - это ситуация, когда передовая модель умеет то, чего не умеет модель прошлого поколения. Такой порог в ML-истории уже проходили (трансформеры против RNN, GPT-3 против GPT-2), и ничего не говорит о том, что его не пройдут снова.
Конечно, можно прыгнуть выше головы, вложить треть бюджета страны в закупку железа, обучение кадров и создание дата-центров. Тратим же мы треть бюджета на другие глобальные события? Другое дело, что вся современная высокотехнологичная продукция производится на западных или китайских чипах, с западным или китайским софтом в прошивках, нередко с компонентами, содержащими модели машинного обучения, созданными в чужих лабораториях.
Это означает буквально следующее. В ситуации серьезного конфликта вполне реален сценарий, при котором иностранная электроника просто не включится. Или включится, но будет работать не так, как от нее ожидается.
Это не паранойя и не теория заговора. Это уже происходит. Современный промышленный софт от Siemens, ABB, Rockwell имеет механизмы дистанционной деактивации, а в Конгрессе США готовятся принять закон, по которому производители GPU-карт будут обязаны включать механизмы деактивации во все изделия.
И тут мы подходим к ключевому вопросу: что делать? Смириться с тем, что вопрос самостоятельного LLM в России сейчас не решается. Нет денег уровня десятков миллиардов долларов, нет доступа к GPU, нет научной школы сопоставимого масштаба, нет частного капитала, готового ждать 10-15 лет, но самое главное - нет воли.
А в один из не самых приятных дней может выясниться, что против нас выступает умный ИИ, и его умная техника принимает решения мгновенно и без оглядки. Или что наша умная техника в критический момент все-таки принимает решения, однако все они не в нашу пользу. Первое - вопрос отставания. Второе - вопрос суверенитета. И неизвестно, что пугает больше.