🚀 DeepSeek выкатили V4 и сделали то, к чему все шли последние два года.
Длинный контекст больше не фича для демо. Теперь это базовый уровень.
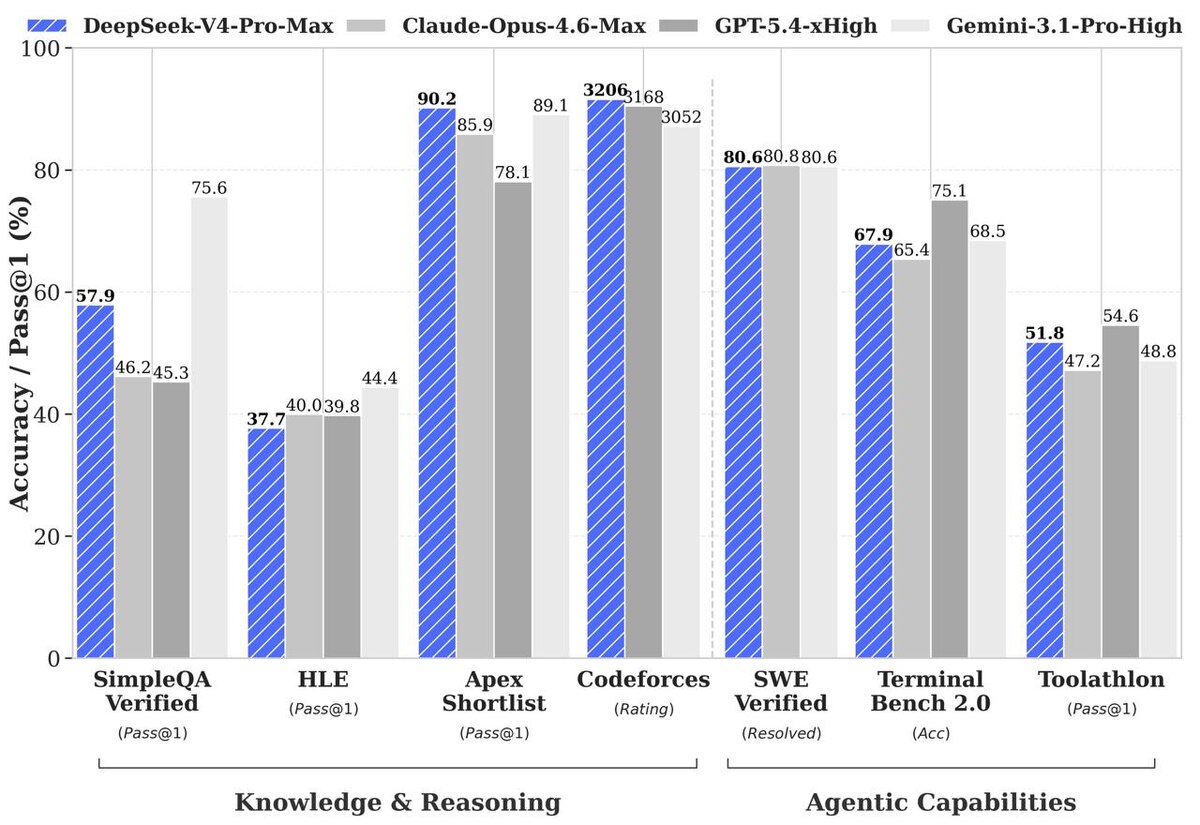
Пока Запад празднует релизы с пафосными стримами, китайцы из DeepSeek сегодня утром просто выложили в Hugging Face две открытые модели и пошли пить чай. А теперь весь твиттер пытается осознать, что произошло. V4-Pro на 1.6 триллиона параметров с 49 миллиардами активных и V4-Flash на 284 миллиарда с 13 активными. Обе открытые, обе с миллионом контекста по дефолту, обе уже доступны через API и на chat.deepseek.com.
Главная фишка даже не в размере, а в том, что DeepSeek пересобрали внимание. Они запихнули в модель токенную компрессию и свою DeepSeek Sparse Attention, за счёт чего длинный контекст стал буквально дешёвым.
Не «технически возможным за пять долларов за запрос», как у конкурентов, а реально дешёвым. 1М теперь стандарт во всех официальных сервисах, а не премиум-опция за отдельную плату.
По цифрам V4-Pro претендует на открытый SOTA в агентном кодинге, тащит математику и STEM и в общих знаниях уступает только Gemini 3.1 Pro. Flash-версия идёт следом почти вплотную по ризонингу и ровно держит планку Pro на простых агентных задачах, но с меньшей задержкой и смешным прайсом.
Отдельно интересно, что API теперь поддерживает и формат OpenAI ChatCompletions, и Anthropic, с переключением между Thinking и Non-Thinking режимами. Старые deepseek-chat и deepseek-reasoner отключат 24 июля 2026, так что у команд есть три месяца на миграцию.
И конечно, DeepSeek не забыли ткнуть Anthropic в бок: в треде прямо написано, что V4 «бесшовно интегрируется с Claude Code, OpenClaw и OpenCode». То есть пока у Anthropic вчера был пост-мортем про сломанный харнесс, DeepSeek сегодня предлагает подменить им модель и сэкономить.
Закрытые лаборатории будут делать вид, что ничего не случилось, но стоимость миллиона токенов контекста только что стала публичной ценой, и от неё уже не отмотаешь.
📄 Tech Report: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
🤗 Open Weights: https://huggingface.co/collections/deepseek-ai/deepseek-v4
#DeepSeek