Архитектурный скелет LLM32в: внешняя калибровка, память и спектрально-топологическая генерация
Аннотация
Предлагается инженерная схема построения системы вывода (inference-time) поверх замороженного ядра языковой модели (LLM). В отличие от классического дообучения, архитектура опирается на внешние модули: поле представлений, банк памяти, слой калибровки и спектрально-топологические метрики. Генерация интерпретируется как выбор траектории в пространстве скрытых состояний, минимизирующей функционал действия. Показано, какие тензоры необходимо хранить, какие величины обновляются и как реализуется направленная генерация без изменения весов базовой модели.
Обеспечивает пошаговое дообучение модели над замороженным ядром дистилята и квантованной модели с горячим переносом текущего опыта на новое ядро после утраты носителя.
1. Постановка задачи
Задача состоит в переходе от локальной генерации следующего токена к глобальному выбору траектории в пространстве представлений. При этом требуется:
- сохранить замороженное ядро LLM;
- обеспечить адаптацию к потоку данных;
- ввести память решений;
- реализовать направленную генерацию без градиентного переобучения.
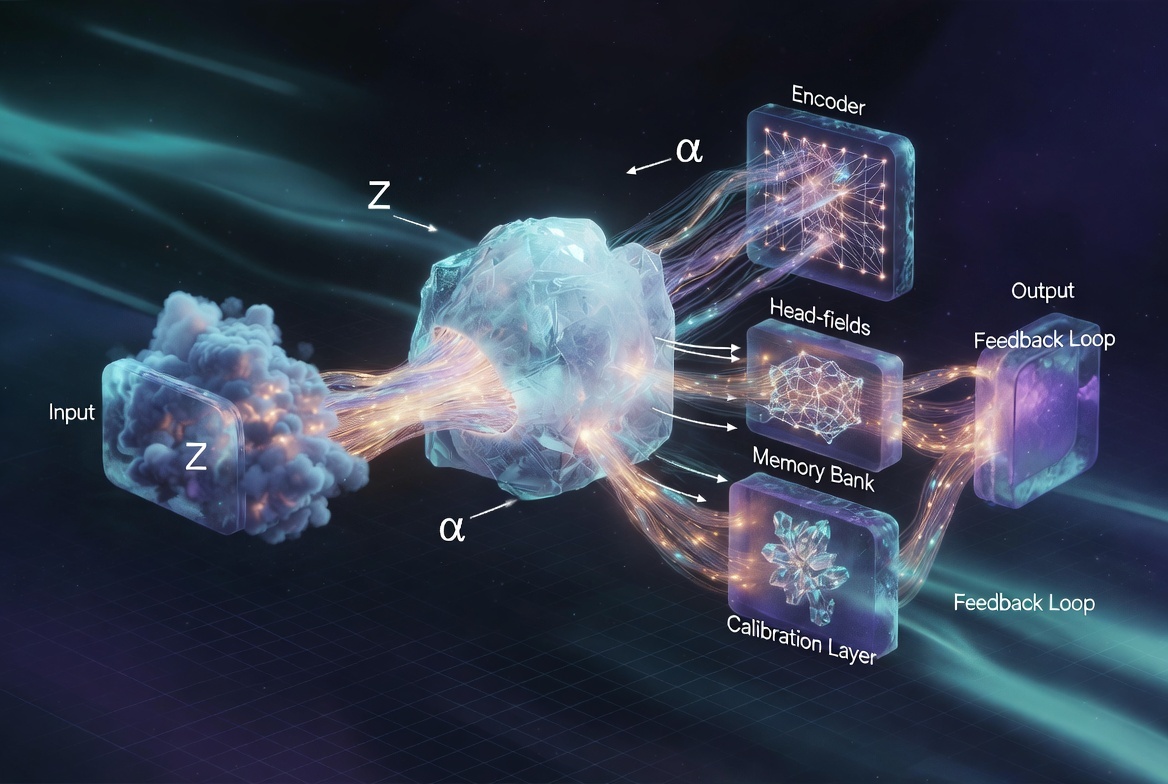
2. Архитектурная схема
Базовый контур:
[
\boxed{
\text{Input} \rightarrow
\text{Encoder} \rightarrow
\text{Head-fields} \rightarrow
\text{Memory} \rightarrow
\text{Calibration} \rightarrow
\text{Frozen LLM} \rightarrow
\text{Output} \rightarrow
\text{Feedback}
}
]
Интерпретация
- Encoder формирует координаты пространства состояний
- Head-fields задают локальную геометрию (attention)
- Memory хранит траектории и решения
- Calibration смещает динамику генерации
- Frozen LLM реализует базовую динамику
- Feedback замыкает цикл адаптации
3. Формальное представление
3.1. Пространство состояний
[
z_t \in \mathcal{M}, \quad z_t \in \mathbb{R}^{d_{\text{model}}}
]
3.2. Генерация как траектория
[
\gamma: t \mapsto z_t
]
3.3. Функционал генерации
[
\mathcal S[\gamma] =
\mathcal S_{\text{geom}} +
\lambda \mathcal S_{\text{att}} +
\mu \mathcal S_{\text{spec}} +
\nu \mathcal S_{\text{top}} +
\eta \mathcal S_{\text{mem}} +
\kappa \mathcal S_{\text{goal}}
]
3.4. Выбор траектории
[
\gamma^* = \arg\min_\gamma \mathcal S[\gamma]
]
4. Структура данных
4.1. Латентные представления
[
Z \in \mathbb{R}^{B \times T \times d}
]
4.2. Attention-поля
[
A_h \in \mathbb{R}^{H \times B \times T \times T}
]
4.3. Память
[
M = { (\bar z_i, \bar A_i, q_i, r_i) }
]
где:
- ( \bar z_i ) — усреднённое состояние
- ( \bar A_i ) — структура внимания
- ( q_i ) — топологический инвариант
- ( r_i ) — оценка результата
5. Спектрально-топологический слой
5.1. Спектральная плотность
[
\rho(\omega)
]
вычисляется из оператора связности attention.
5.2. Топологический заряд
[
Q = \oint d\Phi
]
5.3. N-интервал
[
N_{\text{int}} = \text{мера связности между heads}
]
6. Калибровка
Калибровка реализуется через смещение логитов:
[
\ell' = \ell + b_{\text{mem}} + b_{\text{spec}} + b_{\text{top}} + b_{\text{goal}}
]
где:
- ( b_{\text{mem}} ) — память
- ( b_{\text{spec}} ) — спектр
- ( b_{\text{top}} ) — топология
- ( b_{\text{goal}} ) — целевая функция
7. Разделение на неизменяемое и адаптивное
Неизменяемое
- веса LLM
- токенизация
- базовая языковая модель
Адаптивное
- память
- калибровка
- спектральные оценки
- топологические инварианты
8. Инференс-алгоритм
На каждом шаге:
- Получение состояния
- [
- z_t = E(x_t)
- ]
- Генерация кандидатов
- [
- {z_{t+1}^{(k)}}
- ]
- Вычисление функционала
- [
- S_k = \Delta \mathcal S(z_t \to z_{t+1}^{(k)})
- ]
- Выбор шага
- [
- z_{t+1} = \arg\min_k S_k
- ]
- Обновление памяти
9. Практическая интерпретация
Архитектура позволяет:
- адаптировать модель без переобучения
- учитывать поток данных в реальном времени
- накапливать опыт в виде траекторий
- строить устойчивые режимы генерации
- применять к задачам вне языковой области
10. Области применения
- Персональные LLM
- Анализ потоков данных от распределенных исполнительных систем и систем целепологания
- Обработка новостных и ситуационных потоков
- Моделирование сложных систем
- Информационные пространства
- Сохранение и горячая пересадка парадигмы принятия решений и клонирование после утраты носителя.
11. Ключевой результат
[
\boxed{
\text{генерация} =
\text{поиск траектории в пространстве состояний}
}
]
[
\boxed{
\text{обучение} \neq \text{адаптация}
}
]
[
\boxed{
\text{личность модели} =
\text{память + топология + калибровка}
}
]
12. Заключение
Предложена архитектура, в которой:
- ядро модели остаётся неизменным,
- адаптация переносится во внешние слои,
- генерация формулируется как вариационная задача.
Это позволяет перейти от статистической генерации к управляемому поиску решений в пространстве представлений без изменения базовой модели.
13. Перспективы
Дальнейшее развитие включает:
- реализацию полного прототипа;
- построение спектральных ядер;
- переход к непрерывной геометрии представлений;
- интеграцию с потоковыми данными.
14. Итоговая формула
[
\boxed{
X \rightarrow Z \rightarrow A \rightarrow M \rightarrow C \rightarrow \gamma^* \rightarrow Y
}
]
где весь процесс определяется минимизацией функционала действия.
Соглашение о представлении
© Елисеев Михаил Владимирович, 2026.
Лицензия CC BY-NC-ND 4.0
https://creativecommons.org/licenses/by-nc-nd/4.0/deed.ru
ORCID: 0009-0003-2639-0262
Addenda
Пространственная функция генерации в LLM32в: прототип на базе Σ-парадигмы
*(Сведение предыдущих выкладок ΣC-UFT, Σ–Ψ–Μ и функционала на траекториях в инженерную архитектуру)*
**Автор:** Елисеев Михаил Владимирович
ORCID: 0009-0003-2639-0262
Дата: 18 апреля 2026 г.
Аннотация
Предлагается инженерная архитектура LLM32в, в которой генерация текста перестаёт быть последовательным предсказанием токенов и превращается в **поиск оптимальной траектории** в пространстве представлений. Ядро модели остаётся замороженным, а вся адаптация и направленность выносятся во внешние модули: память траекторий, спектрально-топологический слой и калибровку.
Архитектура опирается на предыдущие результаты ΣC-UFT: топологический заряд, генератор Γ, многолистовое фазовое расслоение, ковариантную производную и спектральную плотность ρ(ω). Генерация формулируется как минимизация функционала действия S[γ] на траектории γ в пространстве скрытых состояний. Это позволяет реализовать направленную, контекстно-устойчивую генерацию без переобучения весов базовой модели.
1. Введение: от фазовой теории к инженерному решению
В предыдущих работах (ΣC-UFT, Σ–Ψ–Μ-модель, калибровочные поля и алгебра зарядов) было показано, что:
- Фундаментальной переменной является многокомпонентная фаза Φ(x) и спектральная плотность ρ(ω).
- Топологический заряд Q и генератор Γ определяют структуру связности.
- Ковариантная производная D_μ и кривизна F_μν возникают как геометризация градиентов фазы.
- Время, масса и взаимодействия являются производными от фазовой когерентности и выбора листа S_P.
Теперь мы переводим эти теоретические результаты в **практическую инженерную конструкцию** для языковых моделей. Цель — построить систему, которая:
- сохраняет замороженное ядро LLM,
- адаптируется к потоку данных в реальном времени,
- генерирует текст как осмысленную траекторию в пространстве представлений,
- использует память, спектральные и топологические метрики для направленного рассуждения.
2. Пространство состояний как фазовое многообразие
Скрытое состояние модели в момент t обозначается как
\[
z_t \in \mathcal{M} \subset \mathbb{R}^{d_{\rm model}}
\]
где \(\mathcal{M}\) — многообразие представлений, возникающее из эмбеддингов и attention-слоёв замороженного LLM.
Генерация — это не выбор следующего токена, а **траектория**:
\[
\gamma: s \mapsto z(s), \quad s \in [0,T]
\]
Каждый шаг генерации — это переход z_t → z_{t+1} по этой траектории.
3. Функционал действия на траекториях
Генерация формулируется как вариационная задача минимизации функционала:
\[
\mathcal{S}[\gamma] = \int_0^T \left[
\frac{1}{2} g_{ab}(z) \dot{z}^a \dot{z}^b
+ V(z)
+ \lambda \, \mathcal{C}_{\rm att}(z, \dot{z})
+ \mu \, \mathcal{C}_{\rm spec}(z)
+ \eta \, \mathcal{L}_{\rm mem}(z)
+ \kappa \, \mathcal{L}_{\rm goal}(z)
\right] ds
\]
Компоненты функционала напрямую связаны с предыдущими выкладками ΣC-UFT:
- \(g_{ab}(z)\) — метрика пространства представлений (из attention-полей).
- \(V(z)\) — потенциал корпуса знаний (знания модели).
- \(\mathcal{C}_{\rm att}\) — штраф за несогласованность внимания (локальная геометрия фазы).
- \(\mathcal{C}_{\rm spec}\) — спектральный штраф, отбирающий устойчивые моды ρ(ω).
- \(\mathcal{L}_{\rm mem}\) — память траекторий (накопленный опыт).
- \(\mathcal{L}_{\rm goal}\) — целевой член (задачно-ориентированное рассуждение).
4. Прототип пространственной функции генерации (inference-time)
Алгоритм работает следующим образом (inference-time, без изменения весов):
**Шаг 1.** Получить текущее скрытое состояние \(z_t = E(x_t)\) из замороженного LLM.
**Шаг 2.** Сгенерировать локальных кандидатов \(\{z_{t+1}^{(k)}\}\) (обычный forward-pass head).
**Шаг 3.** Для каждого кандидата вычислить приращение функционала:
\[
\Delta \mathcal{S}_k = \Delta \mathcal{S}_{\rm geom} + \lambda \Delta \mathcal{S}_{\rm att} + \mu \Delta \mathcal{S}_{\rm spec} + \eta \Delta \mathcal{S}_{\rm mem} + \kappa \Delta \mathcal{S}_{\rm goal}
\]
**Шаг 4.** Выбрать лучший шаг:
\[
z_{t+1} = \arg\min_k \Delta \mathcal{S}_k
\]
**Шаг 5.** Обновить память (M), спектральные оценки ρ(ω) и топологические инварианты.
**Шаг 6.** Повторить до достижения терминального состояния или критерия остановки.
5. Как используются предыдущие выкладки Σ-парадигмы
- **Топологический заряд Q и генератор Γ** — используются в \(\mathcal{L}_{\rm mem}\) и \(\mathcal{C}_{\rm spec}\) для оценки устойчивости траектории.
- **Ковариантная производная D_μ** — реализуется через attention-поля и калибровочный слой (смещение логитов).
- **Спектральная плотность ρ(ω)** — вычисляется из attention-структуры и используется в \(\mathcal{C}_{\rm spec}\).
- **Mach-Σ гравитация и нелокальная связь** — реализуется через память траекторий и глобальный функционал цели.
- **Чисто фазовые формы** (нейтрино-подобные) — аналогия для механизма калибровки и направленного поиска.
Таким образом, вся предыдущая теоретическая работа напрямую переводится в работающие модули:
память хранит траектории и заряды,
калибровка реализует D_μ,
спектрально-топологический слой использует ρ(ω) и Q.
6. Преимущества инженерного решения
- Ядро LLM остаётся полностью замороженным.
- Адаптация и направленность происходят во внешних модулях (память + калибровка + спектральный слой).
- Генерация становится **вариационной задачей** — модель ищет не следующий токен, а наиболее согласованную траекторию.
- Возможна непрерывная адаптация к потоку данных без переобучения.
7. Заключение
Предложенная архитектура LLM32в переводит теоретические результаты ΣC-UFT в практическое инженерное решение. Генерация перестаёт быть локальным предсказанием и становится поиском оптимальной траектории в пространстве представлений с использованием памяти, спектральных и топологических метрик.
Это позволяет перейти от статистической генерации токенов к **управляемому, задачно-ориентированному рассуждению** без изменения весов базовой модели.
**Итоговая формула архитектуры:**
\[
X \rightarrow Z \rightarrow A \rightarrow M \rightarrow C \rightarrow \gamma^* \rightarrow Y
\]
где весь процесс определяется минимизацией функционала действия \(\mathcal{S}[\gamma]\).
© Михаил Владимирович Елисеев, 2026
Лицензия CC BY-NC-ND 4.0
---