
Конкурентоспособность цифрового продукта во многом определяется качеством пользовательского опыта. Его основа – стабильная работа приложения, высокая скорость отклика и прозрачность процессов. Бизнес должен поддерживать высокий уровень сервиса, соответствующий ожиданиям клиентов и требованиям рынка.
Но одного лишь определения заявленных стандартов недостаточно. Важно регулярно измерять реальные результаты – только так возможно достижение целевых значений ключевых показателей. Эту задачу решает SLO.
Рассмотрим подробнее, что представляет собой метрика и каким образом она помогает выстраивать предсказуемый и качественный сервис.
SLO, SLA и SLI: в чем разница
Термины часто используются вместе, но имеют разное назначение:
Цель уровня обслуживания (SLO, Service Level Objective) – это внутренняя управленческая цель, выраженная в процентах за период. Показатель состоит из трех ключевых элементов:
- Метрика – измеряемое число (уровень доступности, время отклика, доля успешных транзакций или объем простоев).
- Цель – конкретное значение, которого нужно достичь (99,9% успешных запросов за 7 дней или <200 мс времени ответа).
- Время – срок, за который измеряется метрика (месяц, квартал или другой отчетный цикл).
В отличие от алертов, которые часто настраиваются «на все подряд», SLO фиксируют именно то, что влияет на бизнес.
Соглашение об уровне обслуживания (SLA, Service Level Agreement) – это договор между поставщиком и клиентом, в котором описываются измеримые показатели работы сервиса (формальный документ или устная договоренность внутри компании между ИТ и бизнесом).
Индикатор уровня обслуживания (SLI, Service Level Indicator) – это метрика, отражающая фактическое состояние сервиса. Именно на основе SLI оценивается достижение целевых значений, установленных в рамках SLO. Есть два основных способа его задать:
- Через количество событий. Например, количество запросов без ошибок делится на все запросы. Если из 28 млн запросов за неделю 500 тысяч завершились с ошибкой, ваш SLI = (28M − 0.5M) / 28M ≈ 98,2%.
- Через интервалы времени. Иногда нужной метрики в виде счетчика нет. Допустим, вы хотите, чтобы запросы были быстрее 1 секунды, но у вас есть только среднее время за минуту. Тогда SLI считается как: количество минут, в которые среднее время запроса было меньше 1 секунды, делится на общее количество минут.
Про бюджет ошибок
Также в рамках разработки SLO ключевую роль играет бюджет ошибок (Error budget), который показывает допустимые отклонения от целевого уровня обслуживания – «сколько нам осталось до нарушения». Бизнесу важно не только поддерживать стабильность, но и развивать продукт: выпускать новые функции, обновлять архитектуру, проводить A/B‑тесты и оптимизировать производительность. Бюджет ошибок задает количественные границы допустимого риска и помогает балансировать эти задачи.
Допустим, SLO – 98% успешных запросов за 7 дней. Текущий SLI – 98,3%. Бюджет ошибок уже не 100%, а примерно 17%, потому что из допустимого запаса ошибок вы уже израсходовали часть. Если ошибок станет больше и SLI упадет до 98% – бюджет обнулится, обещание нарушено.
Если SLI уйдет ниже SLO, бюджет станет отрицательным: −66% означает, что вы кратно превысили допустимый уровень ошибок.
Однако бюджет ошибок может восстанавливаться. Если у вас было 500 тыс ошибочных запросов на фоне 28 млн хороших, а потом нагрузка выросла и вы обработали 600 млн хороших запросов при тех же 500 тыс ошибок – в процентном соотношении стало лучше, и показатель восстановился.
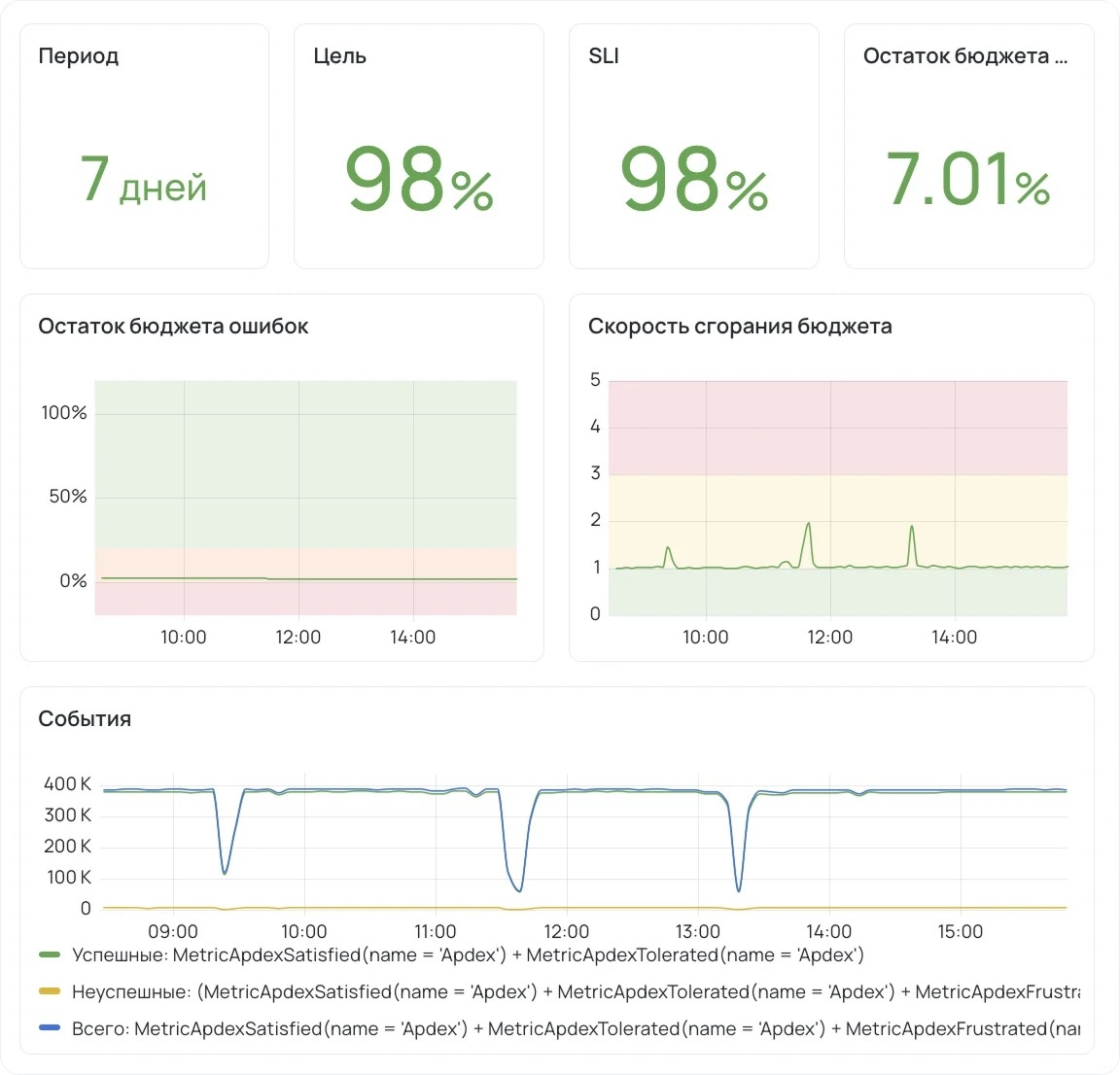
Про скорость сгорания
Метрика скорости сгорания (Burn Rate) показывает, с какой интенсивностью расходуется бюджет ошибок. Для наглядности ее можно представить по принципу светофора:
- Зеленый (<1) – бюджет ошибок стабилен. Все в порядке.
- Желтый (1-3) – повышенный расход; возможно нарушение SLO.
- Красный (>3) – нарушение SLO ожидается в ближайшее время.
Именно на скорости сгорания ставятся предиктивные алерты: система срабатывает только тогда, когда показатель превышает порог одновременно в коротком окне (5-60 минут) и в длинном (6-72 часа). Это подход заимствован из Google SRE.
При создании цели уровня обслуживания автоматически создаются три алерта:
- SLI < SLO – обещание уже нарушено.
- Фастберн (Fast burn) – бюджет ошибок сгорает быстро, проблема прямо сейчас.
- Слоуберн (Slow burn) – бюджет ошибок медленно тает, проблема в перспективе.
Как это работает в GMONIT
В платформе наблюдаемости есть несколько способов задать SLI — от простого к сложному:
Отношение метрик — можно выбрать метрику ошибок и метрику всех событий, система сама рассчитает SLI и предложит цель. Настройка занимает меньше 1 минуты.
SQL-условия — для случаев, когда нужна проверка порогового значения: например, «среднее время запроса <1 секунды за 5 минут». Нужно выбрать метрику, агрегацию, оператор сравнения и порог.
Произвольный SLI — полная свобода: любой источник данных, любые запросы. Можно подключить метрики из Prometheus, Zabbix или кастомные бизнес-метрики. Единственное требование — запрос должен возвращать значение от 0 до 1.
При создании вы сразу видите превью: текущий SLI, рекомендованную цель, остаток бюджета ошибок и графики. Можно поменять цель и увидеть, как изменится бюджет, еще до сохранения.
Кроме ручной настройки, есть библиотека шаблонов: готовые SLO для APM (доля ошибок транзакций, Apdex), браузерных метрик (скорость появления главного контента (LCP, Largest Contentful Paint), визуальная стабильность веб-страницы (CLS, Cumulative Layout Shift) и др.), инфраструктуры (CPU, память, диск, перезагрузки хостов).
Для каждого SLO можно добавить фильтр по приложению, настроить лейблы для маршрутизации алертов в нужный канал и привязать к Карточке инцидента.
__
SLO – это полноценный инструмент системного управления надежностью сервисов. В связке с аналитикой GMONIT целевой уровень обслуживания позволяет не только контролировать выполнение SLA, но и создавать прозрачную, измеримую и управляемую среду для команд разработки и эксплуатации. Они обеспечивают раннее выявление сбоев, помогают с приоритезацией в ИТ, минимизируют риски для бизнеса и поддерживают высокий уровень удовлетворенности клиентов.
Использование платформ наблюдаемости превращает управление продуктов из реактивного процесса в стратегически выверенную, предсказуемую и эффективную практику, где решения принимаются на основе объективных данных, а не догадок или постфактум-оценок.
Источник: https://gmonit.ru/service-level-objective