Как методология PG_EXPECTO 8.1 (CoVe, ToT, Pre-Mortem, эпистемологическая строгость) позволила связать падение операционной скорости СУБД с дисковой очередью aqu_sz > 1 100% времени при нулевом iowait — и выйти на гипотезу о троттлинге IOPS на стороне гипервизора, а не в гостевой ОС.
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Philosophical_instruction_BETA_v5.1.md - Философское ядро + процедурный скелет автономного AI-агента с встроенной самопроверкой. Эпистемология, этика честности, научный метод, think pipeline (CoVe, ToT, Pre-Mortem, Red Teaming, 7 Грехов). Максимальная правдивость, защита от галлюцинаций и prompt injection.
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Предыдущая статья цикла
Предисловие
Когда операционная скорость PostgreSQL падает, ожидания растут, а iowait в системе остаётся в норме — стандартная диагностика заходит в тупик. Методология PG_EXPECTO с её эпистемологической строгостью, самопроверкой и анализом скрытых корреляций (включая ВКО=0,94) позволила не зафиксировать очевидное, а выйти на неочевидную причину: хронический дефицит свободной памяти (<5%) и аномалию дисковой очереди (aqu_sz > 1 в 100% времени) при нулевой утилизации. Это привело к гипотезе о троттлинге на стороне гипервизора — проблеме, которая не видна из гостевой ОС, но убивает производительность СУБД.
Задача
Применить методику PG_EXPECTO (философское ядро, самопроверка, эпистемологическая строгость, стат. анализ) для формирования аналитического отчета по инциденту производительности продуктивной СУБД .
Инцидент производительности СУБД с приоритетом 3
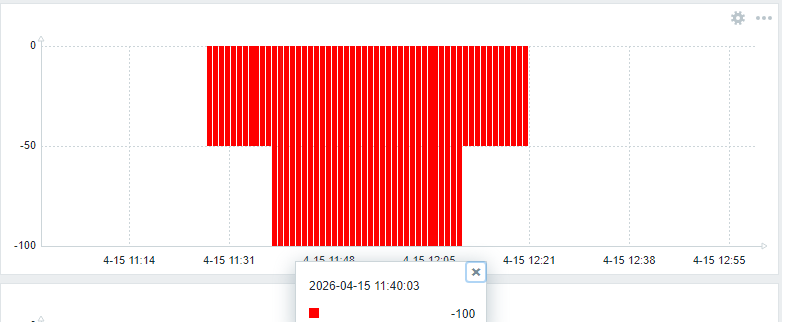
Операционная скорость
Рис.1 График изменения операционной скорости в течении 2-х часов перед инцидентом.
Ожидания СУБД
Рис.2 График изменения ожиданий СУБД в течении 2-х часов перед инцидентом.
Инструкция для формирования аналитического отчета по инциденту производительности:
1. Анализ статистических данных производительности СУБД и ОС в ходе инцидента.
Дата и время инцидента: 2026-04-15 11:40
Исходные данные для формирования статистического отчета :
- _1.settings.txt - Конфигурация СУБД и ОС
- _2.1.test.postgresql_vmstat_iostat.txt - ТЕСТОВЫЙ ОТРЕЗОК ПРОИЗВОДИТЕЛЬНОСТИ СУБД: КОМПЛЕКСНЫЙ КОРРЕЛЯЦИОННЫЙ АНАЛИЗ СУБД , VMSTAT , IOSTAT
- _2.incident.postgresql_vmstat_iostat.txt- ИНЦИДЕНТ ПРОИЗВОДИТЕЛЬНОСТИ СУБД: КОМПЛЕКСНЫЙ КОРРЕЛЯЦИОННЫЙ АНАЛИЗ СУБД , VMSTAT , IOSTAT
Инструкция pg_expecto:
Промпт для анализа статистических данных по инциденту производительности
РЕЗУЛЬТАТ - отчет по анализу статистических данных по инциденту производительности
2.Подготовка аналитического отчета по инциденту производительности СУБД
Входные данные для подготовки аналитического отчета
- performance.txt - анализ статистических данных по инциденту производительности
Промпт для подготовки аналитического отчета
РЕЗУЛЬТАТ - Аналитический отчет по инциденту производительности СУБД
Итоговый отчет по анализу производительности PostgreSQL
Общая информация
Периоды наблюдения:
- Тестовый период: 2026-04-15 09:40 – 10:40 (61 минутный срез).
- Инцидентный период: 2026-04-15 10:40 – 11:40 (61 минутный срез).
Конфигурация оборудования:
- Виртуальная машина: 16 vCPU (Intel Xeon Skylake), 62.79 ГБ ОЗУ.
Диски:
- vdb (950 ГБ) — данные (/data).
- vdc (95 ГБ) — WAL (/wal).
- ОС: Astra Linux.
- Версия PostgreSQL: 15.15.
Ключевые параметры конфигурации (Подтверждено):
- shared_buffers = 16073 MB (≈25.6% от общего объема ОЗУ).
- effective_cache_size = 48220 MB (≈76.8% от общего объема ОЗУ).
- random_page_cost = 1.1.
- effective_io_concurrency = 300.
- checkpoint_timeout = 15min.
- max_wal_size = 8GB.
- work_mem = 8MB.
- maintenance_work_mem = 2GB.
- autovacuum_work_mem = 1GB.
- autovacuum_naptime = 1s.
- autovacuum_vacuum_scale_factor = 0.01.
Основные интегральные показатели:
SPEED (операционная скорость):
- Тестовый период: медиана 526 378.
- Инцидентный период: медиана 507 064 (снижение ≈3.7%), тренд — устойчивое падение (R²=0.98, наклон -44.76).
WAITINGS (общие ожидания СУБД):
- Тестовый период: медиана 942.
- Инцидентный период: медиана 910 (тренд роста: R²=0.60, наклон +37.84).
Доминирующий тип ожиданий:
- IO (ввод-вывод), событие DataFileRead — более 99% всех ожиданий в обоих периодах.
Взвешенная корреляция ожиданий (ВКО) для IO:
- Тестовый период: 0.92 (критическое значение).
- Инцидентный период: 0.94 (критическое значение).
Ключевые проблемы СУБД и инфраструктуры
Проблемы уровня СУБД
Деградация производительности в инцидентный период (Подтверждено)
- Операционная скорость (SPEED) монотонно падает, общие ожидания (WAITINGS) растут.
Связь ожиданий IO с общими ожиданиями усилилась до R²=1.00 (против 0.98 в тестовый период).
Очередь процессов на выполнение (run queue) в ОС выросла (медиана с 3 до 4, тренд роста R²=0.69).
Доминирование ожиданий ввода-вывода на чтение (DataFileRead) (Подтверждено)
- 99.4–99.8% всех ожиданий — DataFileRead.
- Нагрузка распределена между множеством запросов (queryid); доля топ-запроса ≈11%.
- Корреляция ожиданий IO с операциями чтения (bi) усилилась в инцидентный период (r=0.8244 против 0.7653).
- Отрицательная корреляция SPEED с IOPS на устройстве vdb в инцидентный период (r=-0.6501) указывает на чувствительность производительности к частоте операций ввода-вывода.
Потенциально неоптимальные настройки памяти (Вероятно)
- work_mem = 8MB (значение по умолчанию). При наличии сортировок или хеш-соединений с объемом данных >8MB может приводить к использованию временных файлов и дополнительному IO. (Подтверждено: статистика temp_files в отчете отсутствует — Неизвестно).
- shared_buffers = 16GB при effective_cache_size = 48GB и почти полном заполнении page cache ОС (≈45GB). Суммарный кэш (≈61GB) близок к общему объему ОЗУ. Возможно, рабочий набор данных превышает доступную память, либо выполняются последовательные сканирования, вытесняющие полезные страницы.
Проблемы инфраструктуры
Хронический дефицит свободной оперативной памяти (Подтверждено)
- Свободная память (memory_free) менее 5% от общего объема (≈1 ГБ из 62.8 ГБ) на всем протяжении наблюдения.
- Практически вся память занята page cache (≈45.6 ГБ) и буферами PostgreSQL. Своппинг отсутствует.
- Вывод: система функционирует на пределе доступной памяти, что ограничивает гибкость при пиковых нагрузках и может приводить к вытеснению страниц из кэша.
- Аномалия дисковой очереди на устройстве данных (vdb) (Подтверждено)
- Тестовый период: aqu_sz > 1 в 26% времени (WARNING).
- Инцидентный период: aqu_sz > 1 в 100% времени (ALARM).
- При этом утилизация диска низкая (≈16.5%), задержки чтения/записи в пределах нормы для SSD (r_await ≈0.66ms, w_await ≈3.5ms).
- Противоречие: высокие ожидания IO в СУБД и постоянная очередь в драйвере диска не сопровождаются ростом утилизации или задержек на гостевом уровне.
- Возможные ограничения на уровне виртуализации (Вероятно)
- Рост очереди при низкой гостевой утилизации — признак троттлинга IOPS на гипервизоре или ограничений пропускной способности виртуального диска.
- Устройство WAL (vdc) не демонстрирует подобного поведения (aqu_sz в норме).
- Для подтверждения необходимы метрики с хостовой стороны (Неизвестно).
Потенциальные инженерные риски
- Silent errors (подавление ошибок): Отсутствие логов PostgreSQL не позволяет проверить предупреждения о частых контрольных точках или ошибках записи (Неизвестно).
- Resource leaks (утечки ресурсов): Данные о трендах numbackends, temp_files, потреблении памяти процессами отсутствуют (Неизвестно).
- Copy-paste config (неадаптированные параметры): work_mem = 8MB может быть унаследовано без адаптации к рабочей нагрузке (Вероятно).
- Race conditions (гонки): Рост run queue при низком IOwait и незначимой корреляции cs-sy не указывает на классические гонки, но требует анализа us (user time) в инцидентный период (Предположение).
Рекомендации по оптимизации СУБД и инфраструктуры
Рекомендации для СУБД (требуют дополнительной диагностики перед внедрением)
Анализ запросов, генерирующих DataFileRead
- Действие: Включить расширение pg_stat_statements (если не включено) и собрать статистику по чтению блоков (blk_read_time, blks_read, blks_hit) для топ-10 queryid из диаграммы Парето.
- Цель: Определить, вызваны ли ожидания последовательными сканированиями больших таблиц, неэффективными индексами или естественной высокой нагрузкой чтения.
- Инструменты: Запросы к pg_stat_statements, планы выполнения (EXPLAIN (ANALYZE, BUFFERS)).
- Ожидаемый результат: Идентификация запросов-кандидатов для оптимизации индексов или переписывания.
Оценка эффективности буферного кэша
- Действие: Вычислить hit ratio = blks_hit / (blks_hit + blks_read) из pg_stat_database за инцидентный период.
- Интерпретация: Значение ниже 90-95% указывает на недостаточность shared_buffers или преобладание последовательных сканирований.
- Рекомендация после анализа: При подтверждении низкого hit ratio и наличии свободной памяти рассмотреть увеличение shared_buffers до 20-24GB (≈35% ОЗУ) с последующим мониторингом.
- Проверка использования временных файлов и work_mem
- Действие: Проанализировать temp_files и temp_bytes в pg_stat_database за инцидентный период.
- Если значения значительны: Поэтапно увеличить work_mem (например, до 16–32MB) для сессий, выполняющих сортировки или хеш-соединения.
- Предостережение: Резкое увеличение work_mem при большом количестве одновременных соединений может привести к дефициту памяти. Рекомендуется устанавливать значение на уровне отдельной роли/базы или через параметр в сессии для проблемных запросов.
Анализ активности контрольных точек и autovacuum
- Действие: Проверить логи PostgreSQL на частоту записей checkpoint starting/completed и предупреждения checkpoint occurring too frequently.
- Мониторинг: pg_stat_bgwriter (соотношение checkpoints_timed и checkpoints_req, объемы сброшенных страниц buffers_checkpoint, buffers_clean, buffers_backend).
- Цель: Убедиться, что фоновая запись не создает всплесков IO, усугубляющих очередь на vdb.
- Потенциальная корректировка: При преобладании внеплановых контрольных точек (checkpoints_req) увеличить max_wal_size или уменьшить wal_keep_size.
Рекомендации для инфраструктуры
Исследование дисковой подсистемы на уровне гипервизора
- Действие: Совместно с администраторами виртуализации проверить наличие ограничений IOPS или пропускной способности (QoS) для виртуальных дисков vdb и vdc.
- Обоснование: Постоянная очередь (aqu_sz > 1) при низкой гостевой утилизации — сильный индикатор троттлинга на стороне хоста.
- Дополнительно: Запросить метрики задержек и очередей со стороны СХД за инцидентный период.
Уточнение картины использования памяти
- Действие: Перейти от мониторинга free к мониторингу available памяти (доступно для новых процессов).
- Если available стабильно ниже 10% ОЗУ: Рассмотреть возможность увеличения объема оперативной памяти ВМ или оптимизировать потребление памяти приложением (например, пулом соединений, количеством рабочих процессов PostgreSQL).
- Примечание: Высокое использование page cache само по себе не является проблемой, но создает риск при пиковых запросах памяти.
Детализация мониторинга ОС
- Действие: Увеличить частоту сбора метрик CPU (us, sy, id, wa) до 5-10 секунд для обнаружения кратковременных всплесков, скрытых минутным усреднением.
- Дополнительно: Добавить мониторинг tps, rtps, wtps для vdb/vdc.
Необходимая дополнительная информация для продолжения анализа и оптимизации
Без указанных ниже данных невозможно перейти от констатации проблем к конкретным действиям по изменению конфигурации. Все пункты имеют статус Неизвестно в текущем отчете и критически важны для дальнейшего анализа.
СУБД: запросы
- Необходимые данные: Планы выполнения (EXPLAIN (ANALYZE, BUFFERS)) для топ-5 queryid из диаграммы Парето за оба периода.
- Цель сбора: Определить, используются ли оптимальные индексы, нет ли избыточных последовательных сканирований.
СУБД: буферный кэш
- Необходимые данные: Значения blks_hit, blks_read из pg_stat_database за оба периода (или рассчитанный hit ratio).
- Цель сбора: Оценить достаточность shared_buffers.
СУБД: временные файлы
- Необходимые данные: Метрики temp_files, temp_bytes из pg_stat_database за инцидентный период.
- Цель сбора: Подтвердить или опровергнуть гипотезу о недостаточном work_mem.
СУБД: контрольные точки
- Необходимые данные: Статистика pg_stat_bgwriter за инцидентный период, включая checkpoints_timed, checkpoints_req, buffers_checkpoint, buffers_clean, buffers_backend.
- Цель сбора: Оценить влияние фоновой записи на дисковую подсистему.
СУБД: логи
- Необходимые данные: Фрагменты логов PostgreSQL за инцидентный период, содержащие предупреждения (WARNING) и записи о контрольных точках.
- Цель сбора: Выявить скрытые ошибки (частые контрольные точки, сбои записи).
Инфраструктура: виртуализация
- Необходимые данные: Метрики производительности дисков vdb/vdc со стороны гипервизора (задержки, IOPS, очередь, наличие троттлинга).
- Цель сбора: Разрешить противоречие между гостевой утилизацией и очередью.
Инфраструктура: память
- Необходимые данные: Значения available памяти из /proc/meminfo за инцидентный период.
- Цель сбора: Уточнить, насколько критичен дефицит свободной памяти.
Инфраструктура: CPU
- Необходимые данные: Детализированные значения us, sy, wa за инцидентный период с шагом 5-10 секунд.
- Цель сбора: Объяснить рост run queue при низком wa и sy.
После получения указанных данных потребуется повторный анализ для формирования конкретных рекомендаций по изменению параметров PostgreSQL или инфраструктуры. До этого момента любые предложения по изменению конфигурации будут носить статус Предположение или Вероятно.
Технический итог
Проведённый по методологии PG_EXPECTO корреляционный анализ тестового и инцидентного периодов (по 61 минуте каждый) выявил статистически значимую деградацию операционной скорости (медианное снижение на 3,7%, тренд падения R²=0,98) на фоне роста общих ожиданий (тренд R²=0,60) при доминировании событий DataFileRead (>99% всех ожиданий). Установлено, что ключевые аномалии носят инфраструктурный характер: свободная оперативная память стабильно ниже 5% от общего объёма, а средняя длина очереди запросов к дисковому устройству vdb (aqu_sz) в инцидентный период превышает 1 в 100% времени при неизменно низкой утилизации (≈16,5%) и нормативных задержках (r_await ≈0,66 мс). Данное расхождение, усиленное ростом run queue в ОС (медиана с 3 до 4, R²=0,69) и отрицательной корреляцией SPEED с IOPS на vdb (r=-0,6501), формирует обоснованную гипотезу о наличии троттлинга IOPS или ограничений пропускной способности на уровне гипервизора, не фиксируемых гостевой системой.
Послесловие
Представленный отчёт демонстрирует не только конкретный случай деградации производительности PostgreSQL, но и ценность эпистемологически строгого подхода, реализованного в фреймворке PG_EXPECTO. Отказ от принятия корреляций за причинно-следственные связи, систематическая верификация гипотез через механизмы самопроверки (CoVe, ToT, Pre-Mortem, Red Teaming) и явное разделение фактов («подтверждено»), правдоподобных суждений («вероятно») и неизвестных данных («неизвестно») позволяют избежать двух типичных ошибок оперативного анализа: преждевременного замыкания на ложную причину и некритичного переноса гостевых метрик на всю инфраструктурную цепочку. Дальнейшее развитие методики предполагает формализацию сбора данных с уровня гипервизора и СХД как обязательного условия для полноценной диагностики производительности СУБД в облачной среде.