Rust-эксперимент, который красиво объясняет, почему `Vec` почти всегда лучший варинт
Автор взял идею из Linux filesystem: inode хранит метаданные и указывает на блоки данных. Потом задал очень опасный, но полезный вопрос: а что если такую же схему перенести в Rust-контейнер?
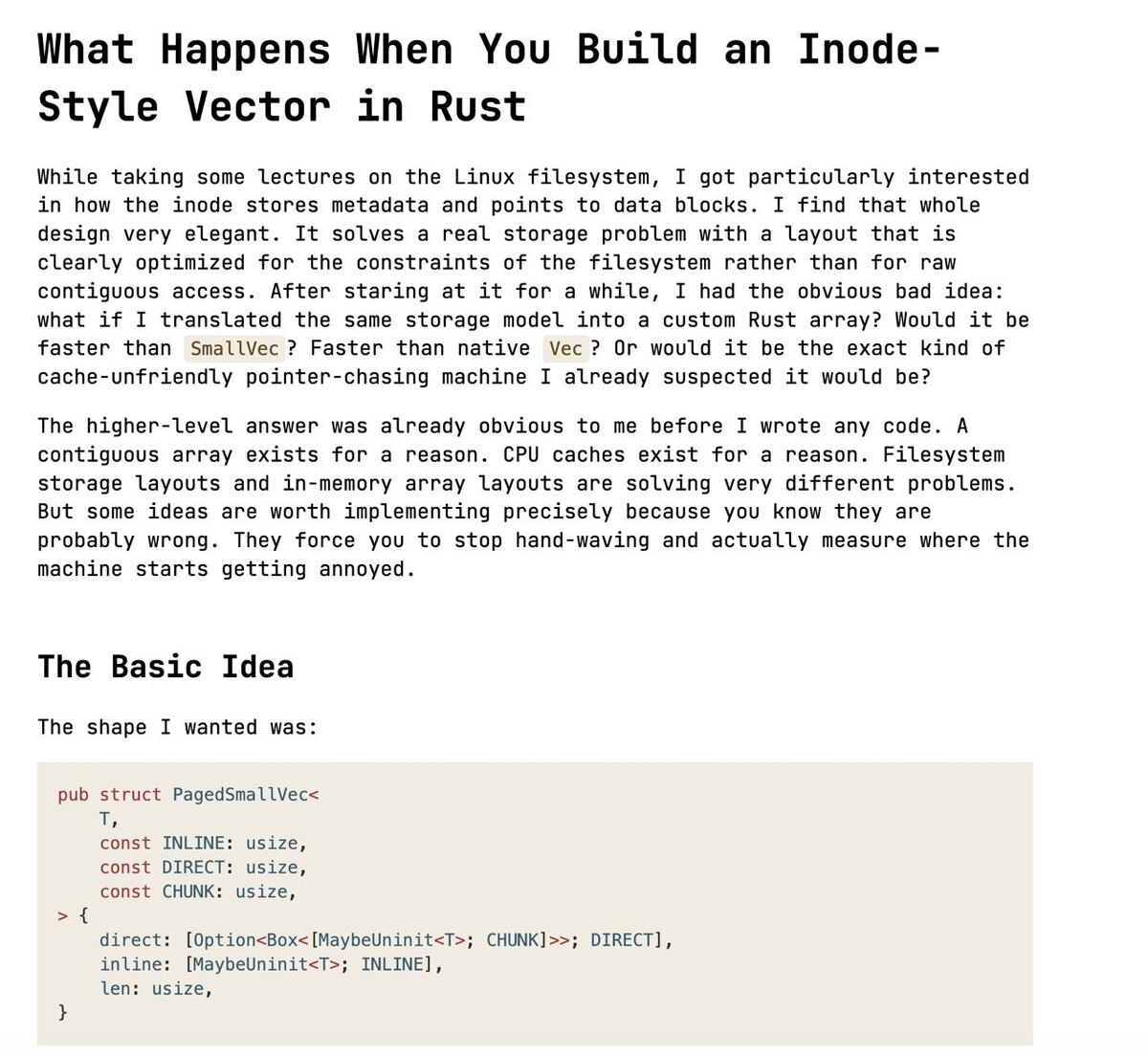
Так появился PagedSmallVec: сначала маленький inline-буфер, потом данные раскладываются по фиксированным чанкам, а не лежат одним непрерывным куском памяти.
Звучит умно. На практике CPU быстро объясняет, кто здесь главный.
Обычный Vec почти всегда быстрее, потому что он делает ровно то, что любит процессор: данные лежат подряд, доступ предсказуемый, меньше переходов по указателям, меньше ветвлений, меньше cache misses. У PagedSmallVec каждый доступ после inline-части превращается в математику по чанкам: вычислить индекс чанка, offset, найти нужный блок, достать значение. Для u32 это особенно больно: там сама операция дешёвая, поэтому накладные расходы контейнера видны сразу.
Бенчмарки получились ожидаемые, но от этого не менее полезные: в обычных vector-like сценариях Vec чаще первый, SmallVec обычно второй, а paged-структура чаще третья. На push, pop, random indexing и ordered remove магии не случилось.
Когда обход сделали не через get(i) на каждый элемент, а чанками через for_each_chunk, структура стала выглядеть гораздо разумнее. Потому что её естественная единица работы - не отдельный элемент, а блок. И вот тут появляется главный урок: плохой API может убить даже неплохую идею, если заставляет структуру данных работать против своей природы.
Где такая схема может иметь смысл?
В append-heavy системах, где буфер часто растёт, но редко индексируется посередине. Например, логи, event buffers, tracing pipelines, ingestion queues. Там иногда важнее не копировать огромный непрерывный буфер при росте, чем выиграть каждый отдельный доступ.
Ещё один сценарий - chunk-native processing: стриминговая аналитика, batch transforms, сериализация, компрессия, обработка данных кусками. Если ваша логика работает чанками, а не элементами, paged layout уже не выглядит странным.
Если ваша цель - «сделать Vec, только быстрее», inode-style vector в Rust плохая идея.
Если цель - понять, где именно pointer-heavy layout проигрывает contiguous memory, как легко сломать инварианты через MaybeUninit, почему unsafe-контейнеры требуют железной дисциплины и почему API должен совпадать с layout, то эксперимент отличный.
Иногда лучший результат плохой идеи - не победа в бенчмарках, а момент, когда машина наконец показывает, где именно вы ошибались.
https://sot.dev/inode-style-vector-in-rust.html