💻🤖💻
Эта статья для тех, кто ни разу не устанавливал ИИ на свой компьютер/ноутбук, но очень хочет попробовать. 😉
❗ Кстати, если вы думаете, будто для установки локальных моделей ИИ нужны супер мощности, то вы ошибаетесь. Сегодня существуют локальные модели, которые вытянет даже относительно слабое железо.
🤔 Как выбрать модель
При выборе модели ориентируйтесь на задачи, для решения которых вы планируете использовать модель и на характеристики своего железа — чем оно новее и мощнее, тем более тяжёлую модель можно установить... Я Капитан Очевидность 😅
Крайне важным параметром является VRAM (память графического процессора). Идеально, если VRAM не менее 16 ГБ. Но и на 4 ГБ можно найти модели, которые будут реально работать.
❗ Не рекомендую ставить тяжёлую модель при 4 ГБ VRAM, так как придётся почти полностью скидывать модель на CPU/RAM. В итоге скорость упадёт до 2–8 токенов/сек, ноут будет греться и шуметь.
Чтобы узнать характеристики своего железа: заходим в меню Пуск → Параметры (система) → Система → О системе
👍 Лучшие модели для слабого железа
Лучший выбор при слабом железе, это Phi-4-mini-instruct (3.8B).
◾ Она занимает мало памяти (около 2,5–3 ГБ в хорошей квантизации).
◾ Хорошо справляется с чатом, размышлением и простым кодингом (Python-скрипты, исправление ошибок, объяснение кода).
◾ На ноутах с 4 ГБ GPU даёт комфортную скорость 15–35+ токенов/сек при правильном распределении.
◾ Отлично работает в LM Studio.
Альтернативный вариант — Qwen3-4B-Instruct. У неё хороший русский язык и чуть сильнее кодинг. И она тоже отлично влезает в 4 ГБ GPU.
💻 Инструкция по запуску локального ИИ
Шаг 1. Устанавливаем LM Studio
Скачайте LM Studio по этой ссылке https://lmstudio.ai/ Установите её.
После установки программа предложит вам загрузить модель. Не загружаем, жмём "Пока пропустить" (Skip for now).
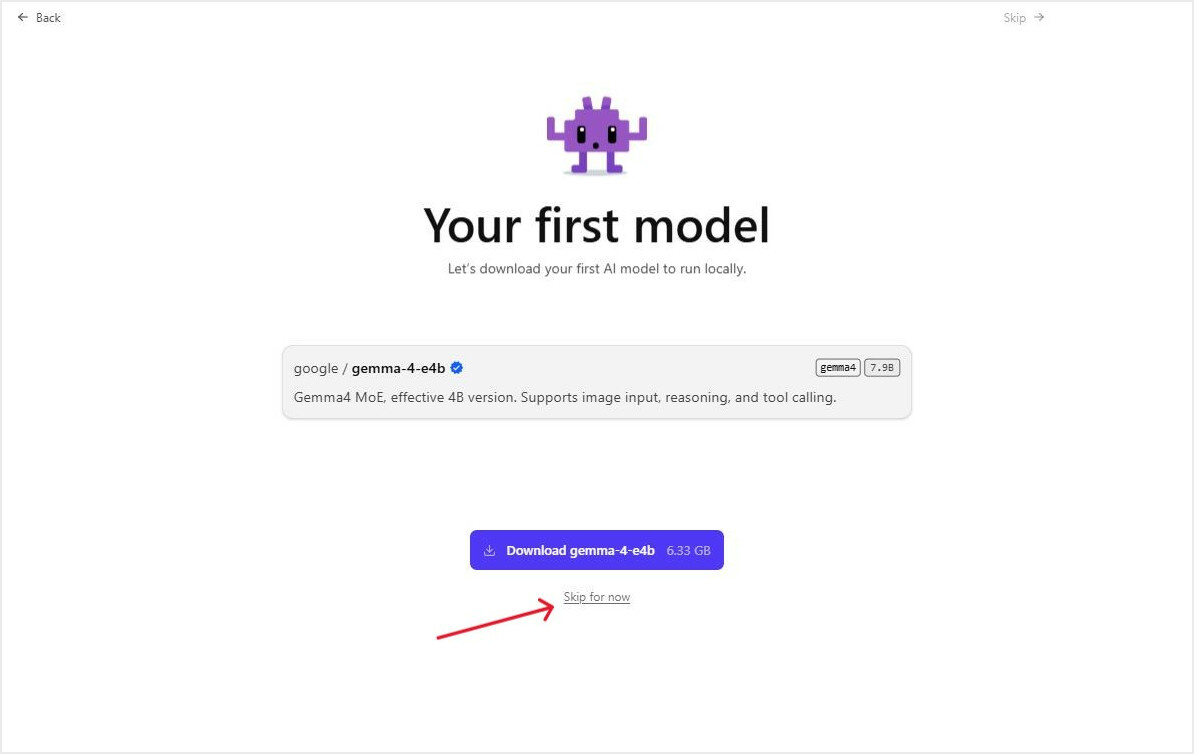
В настройках программы можно сменить язык на русский (но перевод будет частичным), а также, по желанию, изменить цветовую тему, настроить шрифты, блок рассуждений и другое.
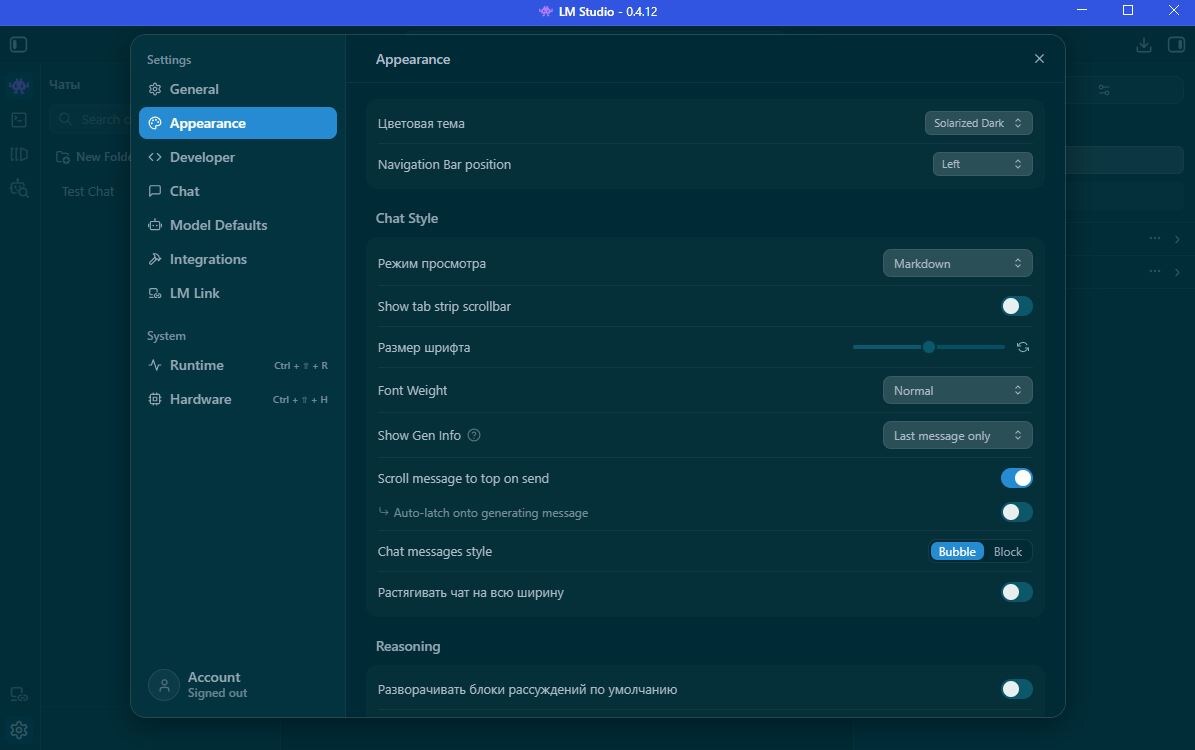
Шаг 2. Скачиваем модель
В LM Studio во вкладке Model Search введите в строку поиска название нужной модели, например Qwen3-4B-GGUF MaziyarPanahi или Phi-4-mini-instruct-GGUF lmstudio-community (подойдёт для слабого железа).
Можете выбрать любую другую модель в зависимости от ваших задач и возможностей железа.
При нажатии на модель в списке, LM Studio сама подскажет возможна ли выгрузка на GPU (это значительно ускорит инференс) и подойдёт ли модель в принципе для вашей машины. Также программа сама определяет оптимальный уровень квантизации под ваше железо.
Если хотите самостоятельно выбрать уровень квантизации в опциях загрузки (Download Options) — нажмите на область указанную красной стрелкой на втором скрине снизу.
Самый оптимальный вариант квантизации, подходящий для большинства задач — Q4_K_M. При ограниченных ресурсах советую выбирать именно его.
Скачайте модель по кнопке Download.
Шаг 3. Запускаем модель
После скачивания перейдите во вкладку Chat и выберите модель, которую вы только что скачали. Нажмите "Загрузить модель". После этого чат должен заработать.
❗ Если выдаёт ошибку типа этой 👇
Сделайте следующее:
◾ В настройках загрузки модели уменьшите количество слоёв на GPU. Вместо 36 поставьте 20–24 слоя (начните с 22). Остальные слои уйдут на CPU + RAM (если у вас 16 ГБ RAM, то вам хватит).
Если при 20–24 слоях модель всё равно не запускается, можно снизить количество слоёв сильнее, но учтите, так как модель будет почти полностью работать на CPU/RAM, это может сильно замедлить её работу.
◾ Уменьшите длину контекста (Context Size) до 4096 или 8192.
◾ Нажмите "Загрузить модель" ещё раз.
Часто это сразу решает проблему.
💙💙💙💙💙💙💙💙💙💙💙💙💙
Спасибо за внимание! Напишите в комментах, получилось ли у вас поставить ИИшку на свой комп или ноут. 🤗