✨🚀✨
27 января 2026 китайская компания Moonshot AI (при поддержке Alibaba) выпустила самую продвинутую открытую мультимодальную модель — Kimi K2.5, которая по многим показателям почти догнала (а по некоторым даже перегнала) передовые модели ИИ вроде GPT, Claude и Gemini.
Ключевые характеристики
🔹 Нативно мультимодальная модель (текст + изображения + видео). Построена через дообучение на ~15 триллионах смешанных визуально-текстовых токенов поверх базы Kimi K2.
🔹 Архитектура: Mixture-of-Experts (MoE) с 1 триллионом общих параметров, но активируется только 32 миллиарда на инференс, что даёт высокую мощность при относительно эффективном потреблении.
🔹 Контекст: до 256K токенов (очень длинный, идеально для сложных задач).
🔹 Режимы работы: Instant (быстрый), Thinking (глубокое рассуждение), Agent (агент с инструментами) и Agent Swarm (бета) — самоорганизующийся рой до 100 субагентов для параллельного выполнения сложных задач, что ускоряет работу в 4,5 раза по сравнению с одиночным агентом.
Сильные стороны и бенчмарки
🔸 Кодинг. Одна из сильнейших open-source моделей на сегодняшний день. Отличные результаты на SWE-Bench Verified (~76–77%), особенно во фронтенде, генерации UI из видео, изображений (vibe-coding). Можно загрузить скрин или видео сайта и получить готовый код с анимациями, слоями.
SWE-Bench (Verified) самый важный реальный бенчмарк по коду сейчас. Модель должна решать настоящие GitHub issues (исправлять баги, добавлять фичи) в реальных репозиториях. Лидерами по данному бенчмарку считаются модели с показателем ~76–81%.
🔸 Компьютерное зрение. MMMU Pro ~75%, OmniDoc Bench — топ среди открытых моделей, хорошо понимает сложные документы, диаграммы, видео.
MMMU — вопросы с картинками, диаграммами, графиками по разным дисциплинам (очень сложный мультимодальный тест).
OmniDoc Bench — оценивает анализ документов, в том числе PDF.
🔸 Агентные задачи. HLE (Humanity's Last Exam) с инструментами ~50–51%, BrowseComp, GDPval-AA — часто обходит или на уровне Claude Opus 4.5 / GPT-5.2, но дешевле и открыта.
HLE-Full (w/tools) — вариант HLE, где модель получает доступ к инструментам (веб-поиск, вычисления, выполнение кода и т.д.), чтобы решать задачи в агентном режиме (многоступенчатое рассуждение + поиск внешних знаний). Данный бенчмарк проверяет не только внутренние знания, рассуждение, но и умение эффективно использовать инструменты для исследования сложных тем (особенно в науке и математике).
BrowseComp оценивает умение агента долго и упорно бродить по интернету не сдаваясь.
GDPval-AA оценивает производительность на практических рабочих задачах.
В целом, Kimi K2.5 сейчас самая мощная открытая модель по комбинации зрение + кодинг + агенты, приближается к передовым моделям OpenAI, Anthropic, Google.
Подробнее об Agent Mode
В режиме Agent модель становится автономным агентом с инструментами. То есть она не просто генерирует текст, а разбивает сложные задачи на шаги, вызывает инструменты (tool calls), анализирует результаты и итеративно доводит дело до конца. Это позволяет справляться с многошаговыми задачами, где нужны инструменты вроде кода, поиска или манипуляции файлами.
В данном режиме модель сама решает, когда и какие инструменты использовать (без вмешательства пользователя). Для супер сложных задач есть Agent Swarm (бета). Это рой до 100 субагентов, которые работают параллельно (до 1500 tool calls), ускоряя всё в 4,5 раза по сравнению с одиночным агентом.
Ключевые особенности режима Agent: нативная мультимодальность (текст + изображения + видео), визуальное мышление, долгосрочное планирование. Агент "самоуправляемый". Он использует Parallel-Agent Reinforcement Learning (PARL) для разбиения задач на подзадачи, без фиксированных ролей.
Что умеет делать модель в Agent Mode
🔺 Выполнение кода. Python, алгоритмы вроде BFS/A* для задач типа поиска пути.
🔺 Анализ изображений, видео. Распознавание пикселей, объектов, OCR; визуализация результатов (например, аннотация изображений).
🔺 Веб-браузинг и поиск. Интеграция с поисковиками для реального времени данных.
🔺 Генерация документов. Создание, редактирование PDF, Word, Excel (со сводными таблицами (Pivot Tables, LaTeX).
🔺 Манипуляция файлами. Создание, редактирование, вставка, просмотр файлов.
🔺 Интеграции. Через Kimi Code (плагины для VSCode/Cursor), API для кастомных инструментов.
📌 Примеры практического применения Kimi агента (готовые промпты) для решения реальных задач в повседневной жизни — читайте тут.
Сравнение Kimi K2.5 с GPT-5.2
Kimi K2.5 не сильно отстаёт, а в ряде ключевых метрик даже обходит GPT-5.2, преимущественно там, где нужна мультимодальность + агенты (см. таблицу ниже 👇)
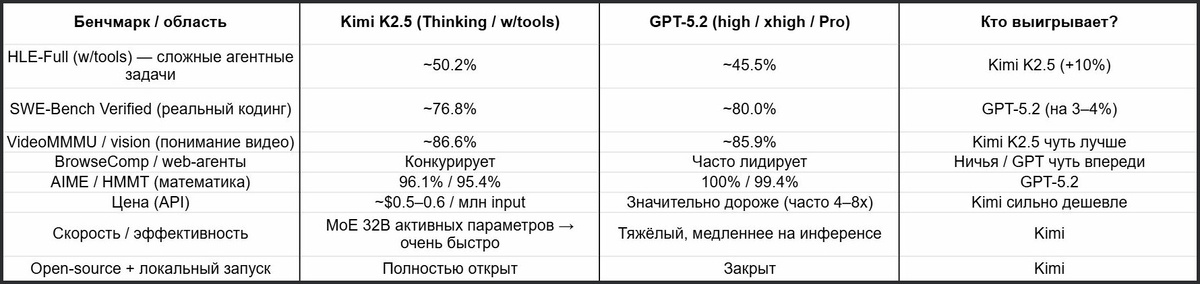
Как видно по таблице, Kimi K2.5 лучше в агентных, инструментальных задачах, особенно с Agent Swarm, визуальном кодинге (видео → анимированный UI), автономном дебаге и цене, доступности.
GPT-5.2 выигрывает в чистой математике, абстрактном рассуждении и иногда в сложном софт-инжиниринге.
В целом отставание минимальное, 3–10% в худшую сторону, а в комбинации "агент + компьютерное зрение" часто на равных с GPT или даже лучше.
Короче, если вам нужен мощный мультимодальный агент без подписки за бешеные деньги, то выбор очевиден. 😏
Сравнение Kimi K2.5 с Claude 4.5 Opus
Для Claude не всё так печально, как для GPT-5.2, но отставание Kimi минимальное или вообще отсутствует в самых актуальных для 2026 года агентных задачах. Ниже таблица сравнения на основе свежих бенчмарков от Moonshot, Hugging Face, VentureBeat, The Decoder и независимых обзоров на конец января 2026 года. 👇
Claude 4.5 Opus всё ещё король чистого софт-инжиниринга. Сложный кодинг, мультиязычный SWE и терминальные задачи, это его стихия. Поэтому если нужен идеальный "программист в коробке" без лишних итераций, то Opus пока чуть надёжнее (на 3–7%).
Но в агентных, инструментальных, автономных задачах, где модель сама ищет инфу, использует инструменты, параллелит подзадачи, Kimi K2.5 уже обходит Claude на 10–17%, а с Agent Swarm это вообще другой уровень (до 100 агентов параллельно. Claude такого вообще не умеет).
Компьютерное зрение + мультимодалка — здесь Claude тоже слегка отстаёт. В задачах с видео, OCR, сложными документами Kimi часто лучше.
Цена, доступность, скорость. Ну тут Claude просто убит. 💀 Kimi это open-source, дешёвый API, локальный запуск, и 4х+ быстрее в реальных рабочих задачах.
В общем, для Anthropic Kimi это не смертельно, но давление огромное, тем более когда открытая модель за копейки делает 80–90% того же, а в агентах даже лучше. Многие девелоперы уже мигрируют на Kimi именно по этой причине.
Доступ к Kimi K2.5
🔺 Бесплатно/частично бесплатно на www.kimi.com и в приложении Kimi (режимы Instant, Thinking, Agent, Swarm в бете для платных пользователей с кредитами).
🔺 API через platform.moonshot.ai (OpenAI-совместимый), цена ~$0.50–0.57 / млн входящих токенов, $2.50–2.85 / млн исходящих, что дешевле многих западных аналогов.
🔺 Open-source. Полные веса доступны на Hugging Face (moonshotai/Kimi-K2.5), лицензия Modified MIT. Можно скачивать, дообучать, деплоить локально, но требует мощного железа.
🔺 Интеграции: Kimi Code (плагин для VSCode, Cursor, Zed), NVIDIA NIM, Fireworks.ai.
Вывод
Kimi K2.5, это серьёзный прорыв от китайской команды. Для разработчиков, которые хотят мощного открытого мультимодального агента без огромных затрат, Kimi вообще подарок.
Многие уже называют выход Kimi моментом, когда open-source окончательно догнал и даже перегнал закрытые модели в агентных задачах и задачах, связанных с компьютерным зрением.
💙💙💙💙💙💙💙💙💙💙💙💙💙
Мои самые тёплые обнимашки всем, кто дочитал 🤗
Ссылка на официальный сайт с анонсом: https://www.kimi.com/blog/kimi-k2-5.html
Ссылка на короткий официальный видеообзор Kimi K2.5: https://vk.com/wall24800125_571