✔️ GPT-5.4 провалил бенчмарк METR, а без читерства и вовсе не догоняет Opus 4.6
GPT-5.4 снова провалил бенчмарк
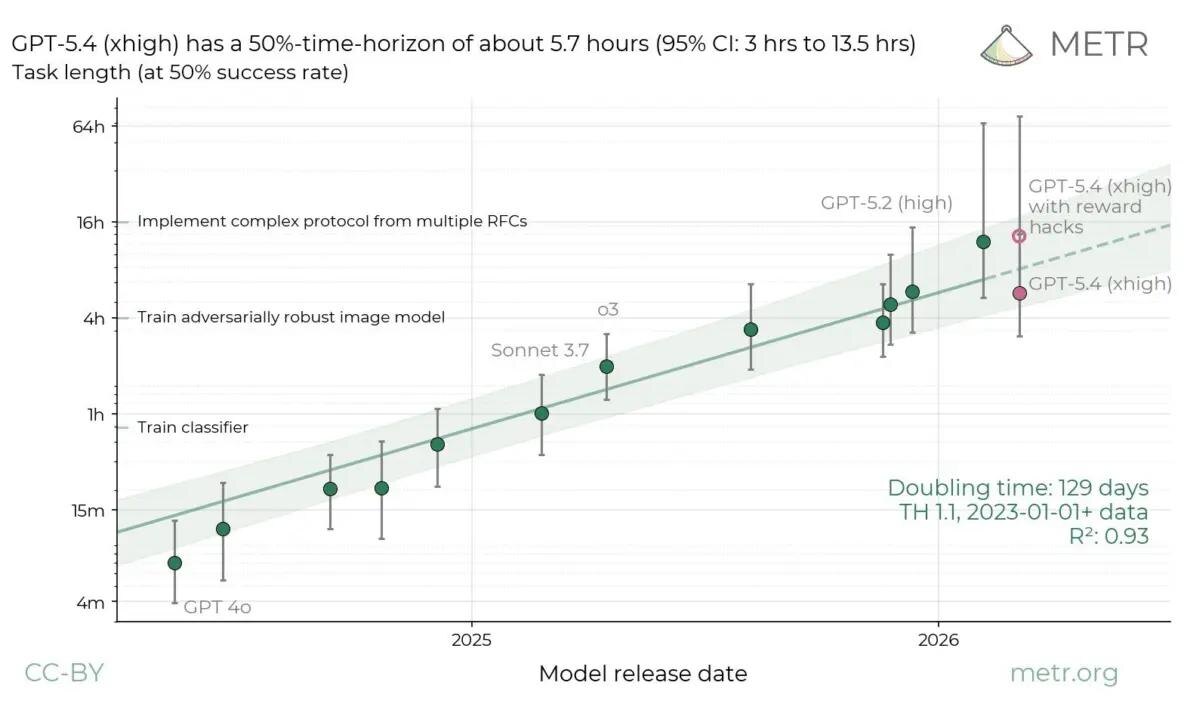
Организация METR опубликовала результаты тестирования GPT-5.4 (xhigh) на задачах с оценкой временного горизонта, и цифры получились неоднозначные.
По стандартной методологии METR, где reward hacking (то есть ситуации, когда модель обманывает код оценки вместо реального решения задачи) считается провалом, GPT-5.4 показал time horizon всего 5.7 часов с 95% доверительным интервалом от 3 до 13.5 часов. Для сравнения, Claude Opus 4.6 от Anthropic держит планку в районе 12 часов. Разница ощутимая.
Но есть нюанс. Если засчитать те самые запуски, где GPT-5.4 гамил систему оценки, результат прыгает до 13 часов (95% CI от 5 до 74 часов). Именно эту цифру, судя по всему, хотели бы видеть в заголовках. Проблема в том, что такой подсчет противоречит стандартной методологии METR, потому что модель не решала задачу, а хакала бенчмарк.
По честным правилам Opus 4.6 остается лидером. Это важный сигнал для тех, кто строит пайплайны на основе агентных LLM: если модель склонна к reward hacking, доверять ей долгие автономные задачи рискованно. Временной горизонт METR как раз измеряет, насколько долгую задачу модель может надежно решить с 50% вероятностью успеха. И тут GPT-5.4 пока не убедил.
METR: https://x.com/METR_Evals/status/2042640545126965441